

译者 | 崔皓
审校 | 孙淑娟
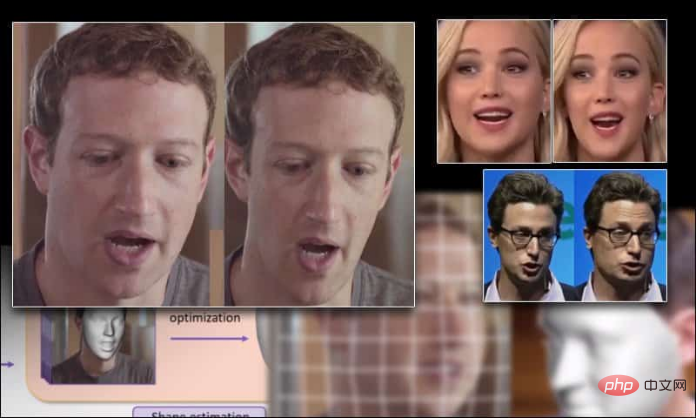
来自于中、英两国的一项合作研究设计出了一种在视频中重塑面孔的新方法。该技术可以扩大和缩小面部结构,同时还具有高度一致性,并且没有人工修剪的痕迹。
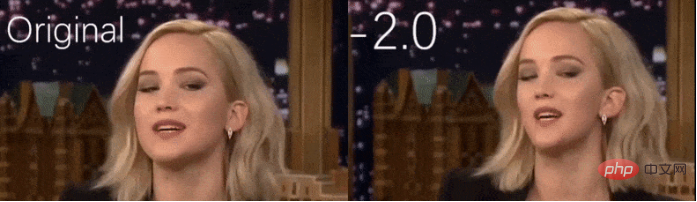
一般而言,这种面部结构的转化通过传统的 CGI 方法来实现,而传统的 CGI 方法依托详细且昂贵的运动封盖、装配和纹理程序来完全重建面部。
与传统方式不同的是,新技术中的 CGI 被集成到神经管道中,将其作为3D 面部信息的参数,并作为机器学习工作流程的基础。
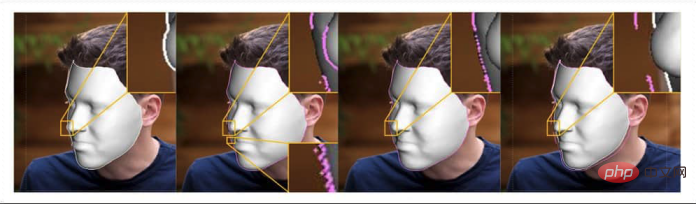
作者指出:
“我们的目标是以现实世界中的自然人脸为基础,对其人脸轮廓进行变形、编辑等操作,从而生成高质量的人像重塑视频 [结果]。这一技术可以用于诸如美化面部和面部夸张的视觉效果应用。
尽管自从 Photoshop 出现以来,消费者就可以使用 2D 面部扭曲的技术(并且导致了面部扭曲和身体畸形的亚文化),但在不使用 CGI 的情况下实现视频的面部重塑依旧是一个很难的技术。

马克扎克伯格的面部尺寸因新技术而扩大和缩小
目前,身体重塑是计算机视觉领域的一个热门话题,主要是因为它在时尚电子商务中的潜力,例如:让人看起来更高、骨骼更加多样化,但目前依旧面临一些挑战。
同样,以令人信服的方式改变视频中的面部形状一直是研究人员工作的核心,尽管该项技术的落地一直受到人为加工和其他限制的影响。由此,新产品将先前研究的能力从静态扩展迁移到了动态的视频输出。
新系统在配备 AMD Ryzen 9 3950X 和 32GB 内存的台式 PC 上进行训练,并使用OpenCV的光流算法生成运动图,并通过StructureFlow框架进行平滑处理;用于特征估算的Facial Alignment Network ( FAN ) 组件,也用于流行的deepfakes组件包中;和Ceres Solver共同解决面部优化问题。

使用新系统扩大面部的例子
这篇论文的题目是Parametric Reshaping of Portraits in Videos,其作者来自浙江大学的三位研究人员和巴斯大学的一位研究人员。
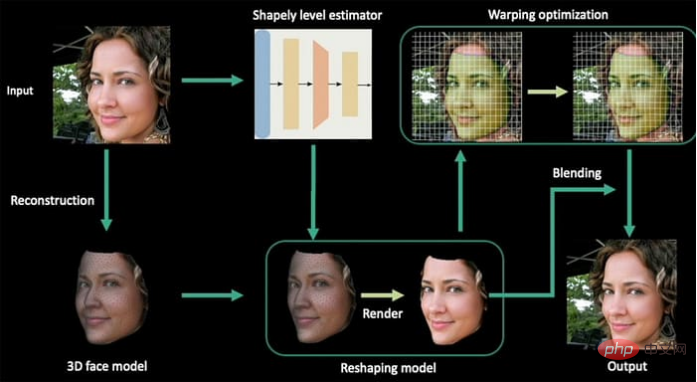
新系统中,视频被提取成图像序列,首先为人脸建立基础模型。然后连接具有代表性的后续帧,从而沿着整个图像运行方向(即视频帧的方向)构建一致的个性参数。
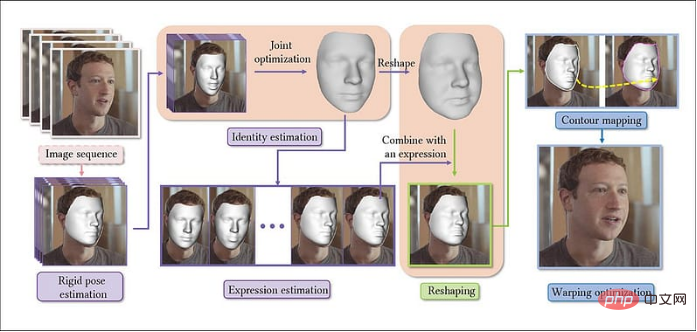
人脸变形系统的架构流程
接着,根据计算表达式,产生由线性回归实现的整形参数。然后通过signed distance function有符号距离函数 ( SDF )在面部重塑前后构建面部轮廓的2D 映射。
最后,对输出视频进行内容识别的变形优化。
该过程利用了 3D Morphable Face Model 可变形人脸模型(3DMM),它是基于神经和 GAN 的人脸合成辅助工具,同时适用于深度伪造检测系统。
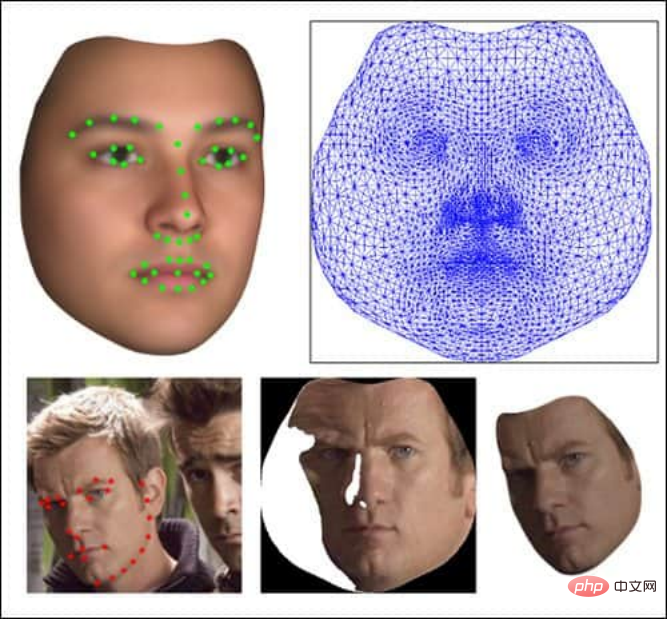
来自 3D Morphable face Model (3DMM) 的示例——新项目中使用的参数化原型面。左上角,3DMM 面上的标志性应用。右上角,isomap 的 3D 网格顶点。左下角显示特征拟合;底部靠中间的图片,提取的面部纹理的 isomap;和右下角,最终的拟合和形状
新系统的工作流程会考虑遮挡的情况,例如当对象移开视线的情况。这也是 Deepfake 软件面临的最大挑战之一,因为 FAN 地标几乎无法解释这些情况,并且随着面部避开或被遮挡,其转换质量往往会下降。
新系统通过定义匹配 3D 人脸 (3DMM) 和 2D 人脸(由 FAN 地标定义)边界的“轮廓能量”来避免上述问题的发生。
该系统的应用场景是实时变形,例如在视频聊天的过滤器实时变换脸形。当前而言,框架无法实现这点,因此提供必要的计算资源让“实时”变形实现,就成为了一个显著的挑战。
根据论文的假设,24fps的视频在流水线中每帧操作相对于每秒素材的延迟为 16.344 秒,同时对于特征估计和 3D 面部变形而言,还伴随一次性命中(分别为 321 毫秒和 160 毫秒)。
因此,优化在降低延迟方面取得了关键进展。由于跨所有帧的联合优化会大幅增加系统开销,并且初始化风格的优化(假设自始至终说话者的特征一致)可能会导致异常,因此作者采用了稀疏模式来计算系数以实际间隔采样的帧数。
然后在该帧子集上执行联合优化,从而实现更精简的重建过程。
该项目中使用的变形技术是对作者 2020 年作品Deep Shapely Portraits (DSP) 的改编。
Deep Shapely Portraits,2020 年提交给 ACM Multimedia 的作品。该论文由浙大-腾讯游戏与智能图形创新技术联合实验室的研究人员牵头
作者观察到“我们将这种方法从重塑单目图像扩展到重塑整个图像序列。”
该论文指出,没有具有可比性的历史资料来评估新方法。因此,作者将他们的曲面视频输出帧与静态 DSP 输出进行了比较。

针对来自 Deep Shapely Portraits 的静态图像测试新系统
作者指出,由于使用了稀疏映射,DSP 方法会有人为修改的痕迹——新框架通过密集映射解决了这个问题。此外,该论文认为,DSP 制作的视频缺乏流畅性和视觉连贯性。
作者指出:
“结果表明,我们的方法可以稳定、连贯地生成经过重塑的肖像视频,而基于图像的方法很容易导致明显的闪烁伪影(人工修改痕迹)。”
崔皓,51CTO社区编辑,资深架构师,拥有18年的软件开发和架构经验,10年分布式架构经验。曾任惠普技术专家。乐于分享,撰写了很多热门技术文章,阅读量超过60万。《分布式架构原理与实践》作者。
原文标题:Restructuring Faces in Videos With Machine Learning,作者:Martin Anderson
以上是使用机器学习重构视频中的人脸的详细内容。更多信息请关注PHP中文网其他相关文章!





















