

这篇文章主要介绍了python socket网络编程之粘包问题详解,现在分享给大家,也给大家做个参考。一起过来看看吧
一,粘包问题详情
1,只有TCP有粘包现象,UDP永远不会粘包
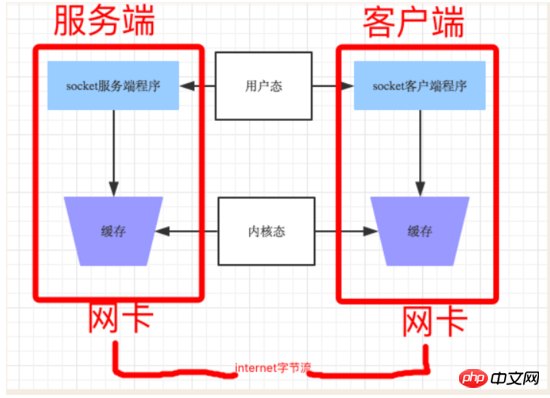
你的程序实际上无权直接操作网卡的,你操作网卡都是通过操作系统给用户程序暴露出来的接口,那每次你的程序要给远程发数据时,其实是先把数据从用户态copy到内核态,这样的操作是耗资源和时间的,频繁的在内核态和用户态之前交换数据势必会导致发送效率降低, 因此socket 为提高传输效率,发送方往往要收集到足够多的数据后才发送一次数据给对方。若连续几次需要send的数据都很少,通常TCP socket 会根据优化算法把这些数据合成一个TCP段后一次发送出去,这样接收方就收到了粘包数据。
2,首先需要掌握一个socket收发消息的原理
发送端可以是1k,1k的发送数据而接受端的应用程序可以2k,2k的提取数据,当然也有可能是3k或者多k提取数据,也就是说,应用程序是不可见的,因此TCP协议是面来那个流的协议,这也是容易出现粘包的原因而UDP是面向无连接的协议,每个UDP段都是一条消息,应用程序必须以消息为单位提取数据,不能一次提取任一字节的数据,这一点和TCP是很同的。怎样定义消息呢?认为对方一次性write/send的数据为一个消息,需要命的是当对方send一条信息的时候,无论鼎城怎么样分段分片,TCP协议层会把构成整条消息的数据段排序完成后才呈现在内核缓冲区。
例如基于TCP的套接字客户端往服务器端上传文件,发送时文件内容是按照一段一段的字节流发送的,在接收方看来更笨不知道文件的字节流从何初开始,在何处结束。
3,粘包的原因
3-1 直接原因
所谓粘包问题主要还是因为接收方不知道消息之间的界限,不知道一次性提取多少字节的数据所造成的
3-2 根本原因
发送方引起的粘包是由TCP协议本身造成的,TCP为提高传输效率,发送方往往要收集到足够多的数据后才发送一个TCP段。若连续几次需要send的数据都很少,通常TCP会根据 优化算法 把这些数据合成一个TCP段后一次发送出去,这样接收方就收到了粘包数据。
3-3 总结
TCP(transport control protocol,传输控制协议)是面向连接的,面向流的,提供高可靠性服务。收发两端(客户端和服务器端)都要有一一成对的socket,因此,发送端为了将多个发往接收端的包,更有效的发到对方,使用了优化方法(Nagle算法),将多次间隔较小且数据量小的数据,合并成一个大的数据块,然后进行封包。这样,接收端,就难于分辨出来了,必须提供科学的拆包机制。 即面向流的通信是无消息保护边界的。
UDP(user datagram protocol,用户数据报协议)是无连接的,面向消息的,提供高效率服务。不会使用块的合并优化算法,, 由于UDP支持的是一对多的模式,所以接收端的skbuff(套接字缓冲区)采用了链式结构来记录每一个到达的UDP包,在每个UDP包中就有了消息头(消息来源地址,端口等信息),这样,对于接收端来说,就容易进行区分处理了。 即面向消息的通信是有消息保护边界的。
tcp是基于数据流的,于是收发的消息不能为空,这就需要在客户端和服务端都添加空消息的处理机制,防止程序卡住,而udp是基于数据报的,即便是你输入的是空内容(直接回车),那也不是空消息,udp协议会帮你封装上消息头,实验略
udp的recvfrom是阻塞的,一个recvfrom(x)必须对唯一一个sendinto(y),收完了x个字节的数据就算完成,若是y>x数据就丢失,这意味着udp根本不会粘包,但是会丢数据,不可靠
tcp的协议数据不会丢,没有收完包,下次接收,会继续上次继续接收,己端总是在收到ack时才会清除缓冲区内容。数据是可靠的,但是会粘包。
二,两种情况下会发生粘包:
1,发送端需要等到本机的缓冲区满了以后才发出去,造成粘包(发送数据时间间隔很短,数据很小,python使用了优化算法,合在一起,产生粘包)
客户端
#_*_coding:utf-8_*_ import socket BUFSIZE=1024 ip_port=('127.0.0.1',8080) s=socket.socket(socket.AF_INET,socket.SOCK_STREAM) res=s.connect_ex(ip_port) s.send('hello'.encode('utf-8')) s.send('feng'.encode('utf-8'))
服务端
#_*_coding:utf-8_*_ from socket import * ip_port=('127.0.0.1',8080) tcp_socket_server=socket(AF_INET,SOCK_STREAM) tcp_socket_server.bind(ip_port) tcp_socket_server.listen(5) conn,addr=tcp_socket_server.accept() data1=conn.recv(10) data2=conn.recv(10) print('----->',data1.decode('utf-8')) print('----->',data2.decode('utf-8')) conn.close()
2,接收端不及时接受缓冲区的包,造成多个包接受(客户端发送一段数据,服务端只收了一小部分,服务端下次再收的时候还是从缓冲区拿上次遗留的数据,就产生粘包) 客户端
#_*_coding:utf-8_*_ import socket BUFSIZE=1024 ip_port=('127.0.0.1',8080) s=socket.socket(socket.AF_INET,socket.SOCK_STREAM) res=s.connect_ex(ip_port) s.send('hello feng'.encode('utf-8'))
服务端
#_*_coding:utf-8_*_ from socket import * ip_port=('127.0.0.1',8080) tcp_socket_server=socket(AF_INET,SOCK_STREAM) tcp_socket_server.bind(ip_port) tcp_socket_server.listen(5) conn,addr=tcp_socket_server.accept() data1=conn.recv(2) #一次没有收完整 data2=conn.recv(10)#下次收的时候,会先取旧的数据,然后取新的 print('----->',data1.decode('utf-8')) print('----->',data2.decode('utf-8')) conn.close()
三,粘包实例:
服务端
import socket import subprocess din=socket.socket(socket.AF_INET,socket.SOCK_STREAM) ip_port=('127.0.0.1',8080) din.bind(ip_port) din.listen(5) conn,deer=din.accept() data1=conn.recv(1024) data2=conn.recv(1024) print(data1) print(data2)
客户端:
import socket import subprocess din=socket.socket(socket.AF_INET,socket.SOCK_STREAM) ip_port=('127.0.0.1',8080) din.connect(ip_port) din.send('helloworld'.encode('utf-8')) din.send('sb'.encode('utf-8'))
四,拆包的发生情况
当发送端缓冲区的长度大于网卡的MTU时,tcp会将这次发送的数据拆成几个数据包发送过去
补充问题一:为何tcp是可靠传输,udp是不可靠传输
tcp在数据传输时,发送端先把数据发送到自己的缓存中,然后协议控制将缓存中的数据发往对端,对端返回一个ack=1,发送端则清理缓存中的数据,对端返回ack=0,则重新发送数据,所以tcp是可靠的
而udp发送数据,对端是不会返回确认信息的,因此不可靠
补充问题二:send(字节流)和recv(1024)及sendall是什么意思?
recv里指定的1024意思是从缓存里一次拿出1024个字节的数据
send的字节流是先放入己端缓存,然后由协议控制将缓存内容发往对端,如果字节流大小大于缓存剩余空间,那么数据丢失,用sendall就会循环调用send,数据不会丢失。
五,粘包问题如何解决?
问题的根源在于,接收端不知道发送端将要传送的字节流的长度,所以解决粘包的方法就是围绕,如何让发送端在发送数据前,把自己将要发送的字节流总大小让接收端知晓,然后接收端来一个死循环接收完所有数据。
5-1 简单的解决方法(从表面解决):
在客户端发送下边添加一个时间睡眠,就可以避免粘包现象。在服务端接收的时候也要进行时间睡眠,才能有效的避免粘包情况。
客户端:
#客户端 import socket import time import subprocess din=socket.socket(socket.AF_INET,socket.SOCK_STREAM) ip_port=('127.0.0.1',8080) din.connect(ip_port) din.send('helloworld'.encode('utf-8')) time.sleep(3) din.send('sb'.encode('utf-8'))
服务端:
#服务端 import socket import time import subprocess din=socket.socket(socket.AF_INET,socket.SOCK_STREAM) ip_port=('127.0.0.1',8080) din.bind(ip_port) din.listen(5) conn,deer=din.accept() data1=conn.recv(1024) time.sleep(4) data2=conn.recv(1024) print(data1) print(data2)
上面解决方法肯定会出现很多纰漏,因为你不知道什么时候传输完,时间暂停的长短都会有问题,长的话效率低,短的话不合适,所以这种方法是不合适的。
5-2 普通的解决方法(从根本看问题):
问题的根源在于,接收端不知道发送端将要传送的字节流的长度,所以解决粘包的方法就是围绕,如何让发送端在发送数据前,把自己将要发送的字节流总大小让接收端知晓,然后接收端来一个死循环接收完所有数据
为字节流加上自定义固定长度报头,报头中包含字节流长度,然后依次send到对端,对端在接受时,先从缓存中取出定长的报头,然后再取真是数据。
使用struct模块对打包的长度为固定4个字节或者八个字节,struct.pack.format参数是“i”时,只能打包长度为10的数字,那么还可以先将长度转化为json字符串,再打包。
普通的客户端
# _*_ coding: utf-8 _*_ import socket import struct phone = socket.socket(socket.AF_INET,socket.SOCK_STREAM) phone.connect(('127.0.0.1',8880)) #连接服 while True: # 发收消息 cmd = input('请你输入命令>>:').strip() if not cmd:continue phone.send(cmd.encode('utf-8')) #发送 #先收报头 header_struct = phone.recv(4) #收四个 unpack_res = struct.unpack('i',header_struct) total_size = unpack_res[0] #总长度 #后收数据 recv_size = 0 total_data=b'' while recv_size<total_size: #循环的收 recv_data = phone.recv(1024) #1024只是一个最大的限制 recv_size+=len(recv_data) # total_data+=recv_data # print('返回的消息:%s'%total_data.decode('gbk')) phone.close()
普通的服务端
# _*_ coding: utf-8 _*_
import socket
import subprocess
import struct
phone = socket.socket(socket.AF_INET,socket.SOCK_STREAM) #买手机
phone.bind(('127.0.0.1',8880)) #绑定手机卡
phone.listen(5) #阻塞的最大数
print('start runing.....')
while True: #链接循环
coon,addr = phone.accept()# 等待接电话
print(coon,addr)
while True: #通信循环
# 收发消息
cmd = coon.recv(1024) #接收的最大数
print('接收的是:%s'%cmd.decode('utf-8'))
#处理过程
res = subprocess.Popen(cmd.decode('utf-8'),shell = True,
stdout=subprocess.PIPE, #标准输出
stderr=subprocess.PIPE #标准错误
)
stdout = res.stdout.read()
stderr = res.stderr.read()
#先发报头(转成固定长度的bytes类型,那么怎么转呢?就用到了struct模块)
#len(stdout) + len(stderr)#统计数据的长度
header = struct.pack('i',len(stdout)+len(stderr))#制作报头
coon.send(header)
#再发命令的结果
coon.send(stdout)
coon.send(stderr)
coon.close()
phone.close()5-3 优化版的解决方法(从根本解决问题)
优化的解决粘包问题的思路就是服务端将报头信息进行优化,对要发送的内容用字典进行描述,首先字典不能直接进行网络传输,需要进行序列化转成json格式化字符串,然后转成bytes格式服务端进行发送,因为bytes格式的json字符串长度不是固定的,所以要用struct模块将bytes格式的json字符串长度压缩成固定长度,发送给客户端,客户端进行接受,反解就会得到完整的数据包。
终极版的客户端
# _*_ coding: utf-8 _*_ import socket import struct import json phone = socket.socket(socket.AF_INET,socket.SOCK_STREAM) phone.connect(('127.0.0.1',8080)) #连接服务器 while True: # 发收消息 cmd = input('请你输入命令>>:').strip() if not cmd:continue phone.send(cmd.encode('utf-8')) #发送 #先收报头的长度 header_len = struct.unpack('i',phone.recv(4))[0] #吧bytes类型的反解 #在收报头 header_bytes = phone.recv(header_len) #收过来的也是bytes类型 header_json = header_bytes.decode('utf-8') #拿到json格式的字典 header_dic = json.loads(header_json) #反序列化拿到字典了 total_size = header_dic['total_size'] #就拿到数据的总长度了 #最后收数据 recv_size = 0 total_data=b'' while recv_size<total_size: #循环的收 recv_data = phone.recv(1024) #1024只是一个最大的限制 recv_size+=len(recv_data) #有可能接收的不是1024个字节,或许比1024多呢, # 那么接收的时候就接收不全,所以还要加上接收的那个长度 total_data+=recv_data #最终的结果 print('返回的消息:%s'%total_data.decode('gbk')) phone.close()
终极版的服务端
# _*_ coding: utf-8 _*_
import socket
import subprocess
import struct
import json
phone = socket.socket(socket.AF_INET,socket.SOCK_STREAM) #买手机
phone.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1)
phone.bind(('127.0.0.1',8080)) #绑定手机卡
phone.listen(5) #阻塞的最大数
print('start runing.....')
while True: #链接循环
coon,addr = phone.accept()# 等待接电话
print(coon,addr)
while True: #通信循环
# 收发消息
cmd = coon.recv(1024) #接收的最大数
print('接收的是:%s'%cmd.decode('utf-8'))
#处理过程
res = subprocess.Popen(cmd.decode('utf-8'),shell = True,
stdout=subprocess.PIPE, #标准输出
stderr=subprocess.PIPE #标准错误
)
stdout = res.stdout.read()
stderr = res.stderr.read()
# 制作报头
header_dic = {
'total_size': len(stdout)+len(stderr), # 总共的大小
'filename': None,
'md5': None
}
header_json = json.dumps(header_dic) #字符串类型
header_bytes = header_json.encode('utf-8') #转成bytes类型(但是长度是可变的)
#先发报头的长度
coon.send(struct.pack('i',len(header_bytes))) #发送固定长度的报头
#再发报头
coon.send(header_bytes)
#最后发命令的结果
coon.send(stdout)
coon.send(stderr)
coon.close()
phone.close()六,struct模块
了解c语言的人,一定会知道struct结构体在c语言中的作用,它定义了一种结构,里面包含不同类型的数据(int,char,bool等等),方便对某一结构对象进行处理。而在网络通信当中,大多传递的数据是以二进制流(binary data)存在的。当传递字符串时,不必担心太多的问题,而当传递诸如int、char之类的基本数据的时候,就需要有一种机制将某些特定的结构体类型打包成二进制流的字符串然后再网络传输,而接收端也应该可以通过某种机制进行解包还原出原始的结构体数据。python中的struct模块就提供了这样的机制,该模块的主要作用就是对python基本类型值与用python字符串格式表示的C struct类型间的转化(This module performs conversions between Python values and C structs represented as Python strings.)。stuct模块提供了很简单的几个函数,下面写几个例子。
1,基本的pack和unpack
struct提供用format specifier方式对数据进行打包和解包(Packing and Unpacking)。例如:
#该模块可以把一个类型,如数字,转成固定长度的bytes类型 import struct # res = struct.pack('i',12345) # print(res,len(res),type(res)) #长度是4 res2 = struct.pack('i',12345111) print(res2,len(res2),type(res2)) #长度也是4 unpack_res =struct.unpack('i',res2) print(unpack_res) #(12345111,) # print(unpack_res[0]) #12345111
代码中,首先定义了一个元组数据,包含int、string、float三种数据类型,然后定义了struct对象,并制定了format‘I3sf',I 表示int,3s表示三个字符长度的字符串,f 表示 float。最后通过struct的pack和unpack进行打包和解包。通过输出结果可以发现,value被pack之后,转化为了一段二进制字节串,而unpack可以把该字节串再转换回一个元组,但是值得注意的是对于float的精度发生了改变,这是由一些比如操作系统等客观因素所决定的。打包之后的数据所占用的字节数与C语言中的struct十分相似。
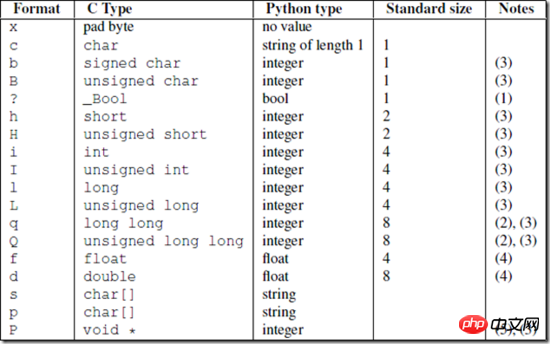
2,定义format可以参照官方api提供的对照表:
3,基本用法
import json,struct
#假设通过客户端上传1T:1073741824000的文件a.txt
#为避免粘包,必须自定制报头
header={'file_size':1073741824000,'file_name':'/a/b/c/d/e/a.txt','md5':'8f6fbf8347faa4924a76856701edb0f3'} #1T数据,文件路径和md5值
#为了该报头能传送,需要序列化并且转为bytes
head_bytes=bytes(json.dumps(header),encoding='utf-8') #序列化并转成bytes,用于传输
#为了让客户端知道报头的长度,用struck将报头长度这个数字转成固定长度:4个字节
head_len_bytes=struct.pack('i',len(head_bytes)) #这4个字节里只包含了一个数字,该数字是报头的长度
#客户端开始发送
conn.send(head_len_bytes) #先发报头的长度,4个bytes
conn.send(head_bytes) #再发报头的字节格式
conn.sendall(文件内容) #然后发真实内容的字节格式
#服务端开始接收
head_len_bytes=s.recv(4) #先收报头4个bytes,得到报头长度的字节格式
x=struct.unpack('i',head_len_bytes)[0] #提取报头的长度
head_bytes=s.recv(x) #按照报头长度x,收取报头的bytes格式
header=json.loads(json.dumps(header)) #提取报头
#最后根据报头的内容提取真实的数据,比如
real_data_len=s.recv(header['file_size'])
s.recv(real_data_len)以上是python socket网络编程之粘包问题详解的详细内容。更多信息请关注PHP中文网其他相关文章!





















