

首先简单的理解一下爬虫。即请求网站并且提取自己所需的数据的一个过程。至于怎么爬如何爬,将是后面进行学习的内容,暂且不必深究。通过我们的程序,可以代替我们向服务器发送请求,然后进行批量、大量的数据的下载。
发起请求:通过url向服务器发起request请求,请求可以包含额外的header信息。
获取响应内容:如果服务器正常响应,那我们将会收到一个response,response即为我们所请求的网页内容,或许包含HTML,Json字符串或者二进制的数据(视频、图片)等。
解析内容:如果是HTML代码,则可以使用网页解析器进行解析,如果是Json数据,则可以转换成Json对象进行解析,如果是二进制的数据,则可以保存到文件进行进一步处理。
保存数据:可以保存到本地文件,也可以保存到数据库(MySQL,Redis,Mongodb等)
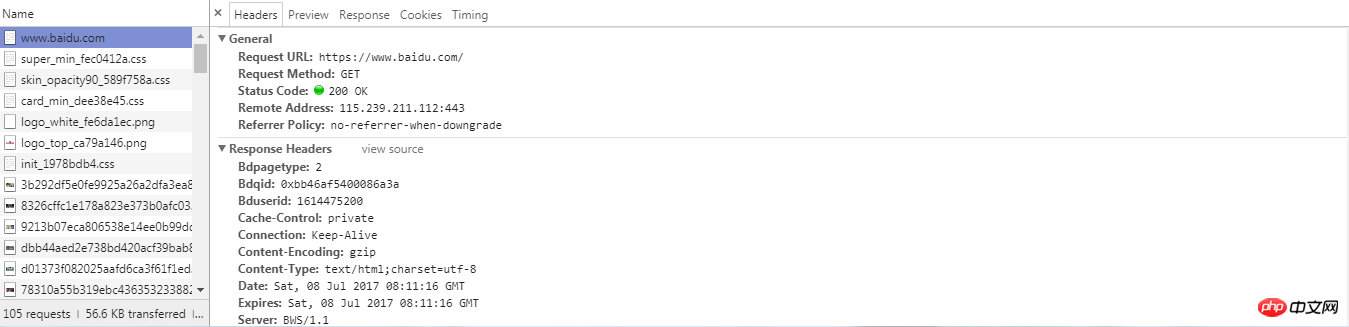
当我们通过浏览器向服务器发送request请求时,这个request包含了一些什么信息呢?我们可以通过chrome的开发者工具进行说明(如果不知道如何使用看本篇备注)。
请求方式:最常用的请求方式包括get请求和post请求。post请求在开发中最常见的是通过表单进行提交,从用户角度来讲,最常见的就是登录验证。当你需要输入一些信息进行登录的时候,这次请求即为post请求。
url统一资源定位符:一个网址,一张图片,一个视频等都可以用url去定义。当我们请求一个网页时,我们可以查看network标签,第一个通常是一个document,也就是说这个document是一个未加外部图片、css、js等渲染的html代码,在这个document的下面我们会看到一系列的jpg,js等,这是浏览器根据html代码发起的一次又一次的请求,而请求的地址,即为html文档中图片、js等的url地址
request headers:请求头,包括这次请求的请求类型,cookie信息以及浏览器类型等。 这个请求头在我们进行网页抓取的时候还是有些作用的,服务器会通过解析请求头来进行信息的审核,判断这次请求是一次合法的请求。所以当我们通过程序伪装浏览器进行请求的时候,就可以设置一下请求头的信息。
请求体:post请求会把用户信息包装在form-data里面进行提交,因此相比于get请求,post请求的Headers标签的内容会多出Form Data这个信息包。get请求可以简单的理解为普通的搜索回车,信息将会以?间隔添加在url的后面。
响应状态:通过Headers中的General可以看到status code。200表示成功,301跳转,404找不到网页,502服务器错误等。
响应头:包括了内容的类型,cookie信息等。
响应体:请求的目的就是为了得到响应体,包括html代码,Json以及二进制数据等。
通过Python的request库进行网页请求:

输出的结果就是还未渲染的网页代码,即请求体的内容。可以查看响应头的信息:
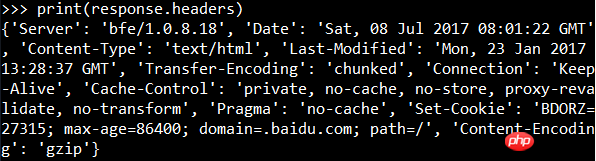
查看状态码:

还可以将请求头添加到请求信息里面:
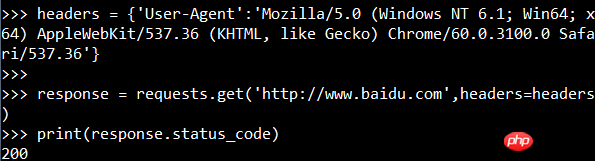
抓取图片(百度logo):

使用Selenium webdriver

输入print(driver.page_source)可以看到,这次的代码是渲染之后的代码。
F12打开开发者工具
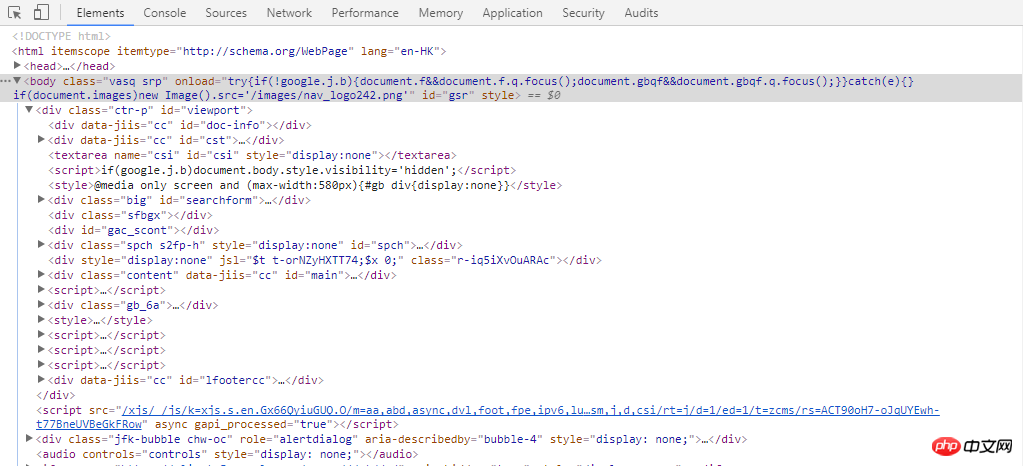
Elements标签显示了显然后的HTML代码。
Network标签
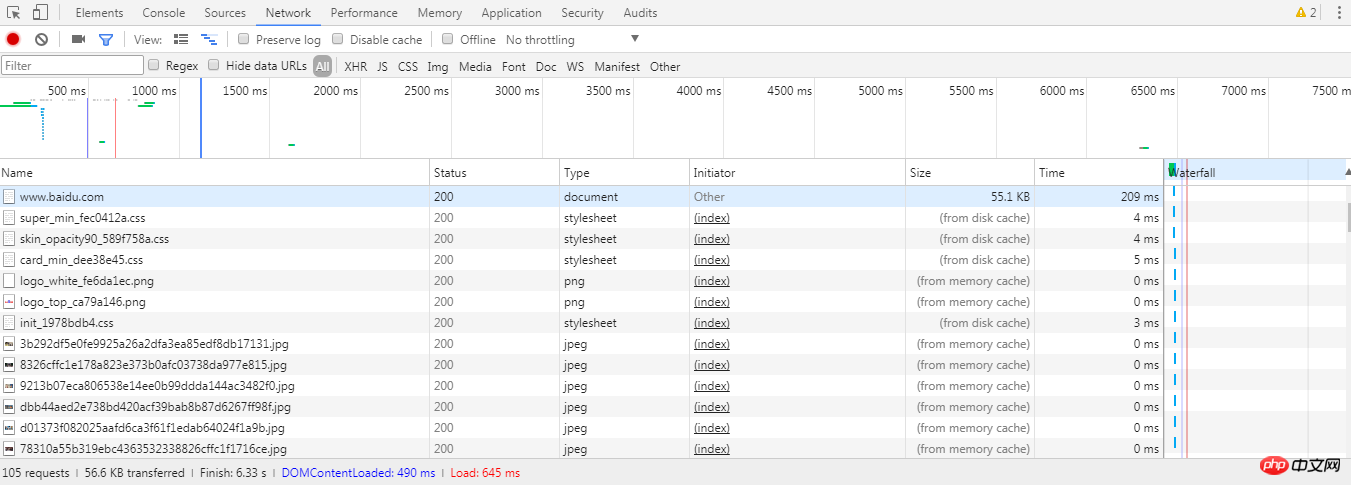
Network标签下有浏览器请求的数据,点开可以查看详细的信息,如上提到的request headers、response headers等等。
以上是什么是爬虫?爬虫的基本流程是什么?的详细内容。更多信息请关注PHP中文网其他相关文章!





















