

一.汉字转拼音的现状
首先应该说,汉字转拼音是个强需求,比如联系人按拼音字母排序/筛选;比如目的地(典型如机票购买)
按拼音首字母分类等等。但是这个需求的解决方案,但好像没听过什么巧妙的实现(特别是浏览器端),大概都需要一个庞大的字典。
具体到JavaScript,查查github和npm,比较优秀的处理汉字转拼音的库有pinyin
和pinyinjs,可以看到,两者都自带了庞大的字典。
这些字典动辄几十上百KB(有的甚至几MB),想在浏览器端使用还是需要一些勇气的。所以当我们碰到汉字转拼音的需求,也不怪我们第一反应就是拒绝需求(或者服务端实现)。
现在,如果我告诉你可以浏览器端300行代码实现汉字转拼音,是不是不可置信?
二.从安卓4.2.2联系人代码说起
再次强调这篇博客——利用Android源码,轻松实现汉字转拼音功能。
今天和大家分享一个从Android系统源代码提取出来的汉字转成拼音实现方案,只要一个类,560多行代码就可以让你轻松实现汉字转成拼音的功能,且无需其他任何第三方依赖。
是不是打破了你的思维定势:难道有什么强大的算法可以抛弃字典?
第一遍看完博客,稍有些失望,并没有什么算法解析,只是介绍了从安卓代码发现的这几百行代码。第二遍时带着移植到JavaScript的想法阅读代码,算是弄懂了原理,于是开始了踩坑的移植之旅。
三.手把手教你300行JavaScript代码实现汉字转拼音
首先直指核心:为什么有汉字转拼音必须有庞大字典的思维定势?
因为汉字的排布和拼音并有什么关联,比如在汉字区间\u4E00-\u9FFF,前一个可能是ha,后一个可能就是ze,没有办法从汉字的unicode关联到拼音,所以只能有一个庞大的字典记录每个汉字(或常用汉字)的拼音。
但是,假设我们可以把所有汉字按拼音排序,比如按'A','AI','AN','ANG','AO','BA',...,'ZUI','ZUN','ZUO'排序,那么,我们只需要记住每个相同拼音的汉字队列的第一个汉字就好了。那么,所需要的字典就会很小(覆盖所有拼音即可,拼音数量本身不多)。
现在,难点就是把汉字按拼音排序了。很幸运,ICU/本地化相关的API提供了这个排序API(如果没有方便的排序/比较方法,那么本篇文章可能就不会出现了)。
所以,这就是为什么300行可以实现汉字转拼音:Intl.CollatorAPI:Intl.Collator内部实现了本土化相关的字符串排序。我们通过Intl.Collator.prototype.compare可以把所有汉字基本按照拼音来排序。
边界汉字表:记录了排序的边界点。该汉字表的每个汉字都是排序后相同拼音的汉字集合的首个汉字(Eachunihansisthefirstonewithinsamepinyinwhencollatoriszh_CN)。
说到这里,可能仍然有没说清楚的地方,所以直接上一段代码:

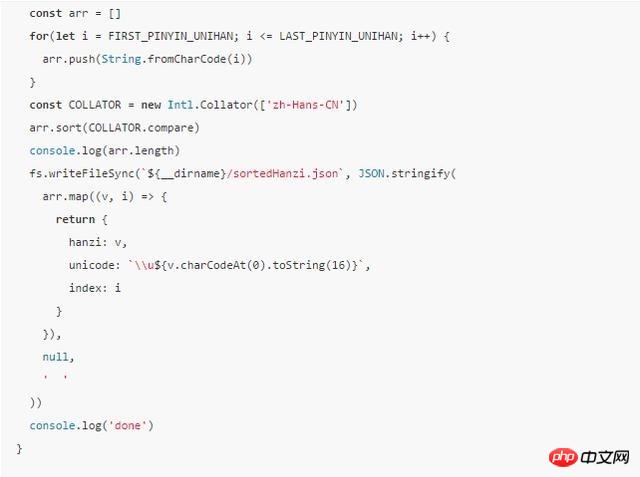
有兴趣的同学可以执行node--icu-data-dir=node_modules/full-icu上面的脚本.js看看,然后看看是不是得到了基本按照拼音排序的汉字表。
这里有几点要注意:
我再次加粗了“基本”,因为我们得到的汉字列表并没有完全按照拼音来排序,中间偶尔有一些其它拼音的汉字插入,这点在制作边界表时要额外注意。
上面脚本里得出的表是所有汉字的排序,其中有些和安卓代码里HanziToPinyin.java的表有不同,所以需要更新HanziToPinyin.java的表。(从Java转到JavaScript的最大的坑和工作量:更正边界表)
相信大家都看到了核心代码:constCOLLATOR=newIntl.Collator(['zh-Hans-CN']),Intl.Collator
(这里指定locale是中国zh-Hans-CN)正是能把汉字按拼音排序的关键,它是按locale-specific顺序,排序字符串的InternationalizationAPI。
执行脚本时请先npmifull-icu,这个依赖会自动安装缺失的中文支持并提示如何指定ICU数据文件来执行脚本。
1.ICUICU即InternationalComponentsforUnicode,为应用提供Unicode和国际化支持。
ICUisamature,widelyusedsetofC/C++andJavalibrariesprovidingUnicodeandGlobalizationsupportforsoftwareapplications.ICUiswidelyportableandgivesapplicationsthesameresultsonallplatformsandbetweenC/C++andJavasoftware.
并且ICU提供了本地化字符串比较服务(UnicodeCollationAlgorithm+本地特定的比较规则):
Collation:Comparestringsaccordingtotheconventionsandstandardsofaparticularlanguage,regionorcountry.ICU'scollationisbasedontheUnicodeCollationAlgorithmpluslocale-specificcomparisonrulesfromtheCommonLocaleDataRepository,acomprehensivesourceforthistypeofdata.
在现代浏览器上,一般ICU内置了对用户本地语言的支持,我们直接使用即可。
但对node.js来说,通常情况下,ICU只包含了一个子集(通常是英语),所以我们需要自行添加对中文的支持。一般来说,可以通过npminstallfull-icu安装full-icu
来安装缺失的中文支持。(参见上面node--icu-data-dir=node_modules/full-icu)。
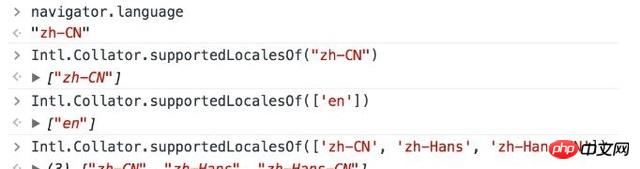
2.IntlAPI上一小节应该基本讲清楚了国际化/本地化相关的知识,这里再补充一下内置API的使用。怎么查看用户语言和Runtime是否支持这个语言?Intl.Collator.supportedLocalesOf(array|string)
返回包含支持(不用回退到默认locale)的locales的数组,参数可以是数组或字符串,为想要测试的locales(即BCP47languagetag)。
构造Collator对象和排序字符串
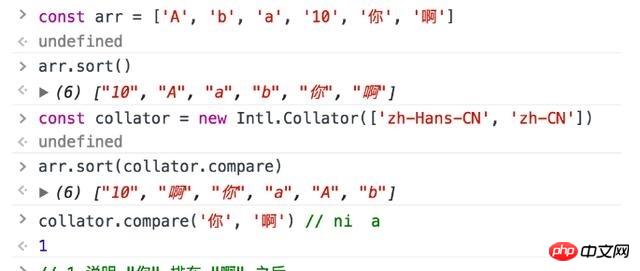
通过Intl.Collator.prototype.compare,我们可以按语言指定的顺序来排序字符串。而中文中,这个排序恰好绝大多数都是按拼音的顺序来的,'A','AI','AN','ANG','AO','BA','BAI','BAN','BANG','BAO','BEI','BEN','BENG','BI','BIAN','BIAO','BIE','BIN','BING','BO','BU','CA','CAI','CAN',...
,这正是我们上面提到的汉字转拼音的关键。
四.边界表更正
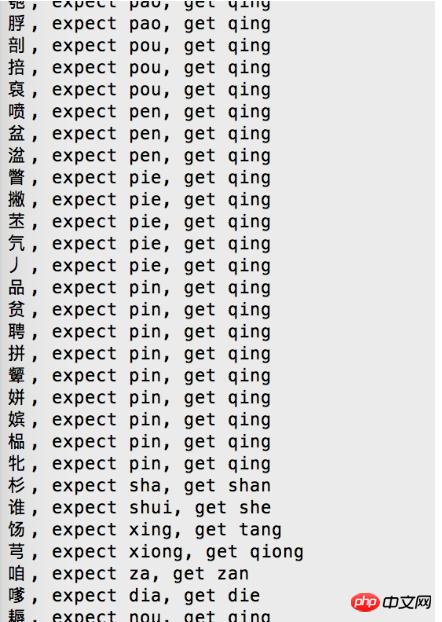
显然,这个边界表是有问题的,需要更正。
我们可看到,大部分的汉字被转成了qing,可见,qing这个拼音对应的汉字有问题。
找到这个汉字,是'\u72c5'/'狅',加上前后各一个字,['\u4eb2','\u72c5','\u828e']/["亲","狅","芎"]
。
搜索,'\u72c5'/'狅'可以读qing,但现在多读kuang,这应该就是错误的原因了。
根据最初得到那张所有汉字的排序表,qing的第一个汉字是'\u9751'/'靑'。
改动后,转换失败的只剩104了。

【相关推荐】
4. Javascript中关于async以及awai的用法具体介绍
以上是JavaScript解决汉字转拼音的实例详解的详细内容。更多信息请关注PHP中文网其他相关文章!


































