一. 前言
在前面的几篇文章中我介绍了如何通过Python分析源代码来爬取博客、维基百科InfoBox和图片,其文章链接如下:
[python学习] 简单爬取维基百科程序语言消息盒
[Python学习] 简单网络爬虫抓取博客文章及思想介绍
[python学习] 简单爬取图片网站图库中图片
其中核心代码如下:
# coding=utf-8
import urllib
import re
#下载静态HTML网页
url='http://www.csdn.net/'
content = urllib.urlopen(url).read()
open('csdn.html','w+').write(content)
#获取标题
title_pat=r'(?<=<title>).*?(?=</title>)'
title_ex=re.compile(title_pat,re.M|re.S)
title_obj=re.search(title_ex, content)
title=title_obj.group()
print title
#获取超链接内容
href = r'<a href=.*?>(.*?)</a>'
m = re.findall(href,content,re.S|re.M)
for text in m:
print unicode(text,'utf-8')
break #只输出一个url登录后复制
输出结果如下:
>>>
CSDN.NET - 全球最大中文IT社区,为IT专业技术人员提供最全面的信息传播和服务平台
登录
>>>
登录后复制
图片下载的核心代码如下:
import os
import urllib
class AppURLopener(urllib.FancyURLopener):
version = "Mozilla/5.0"
urllib._urlopener = AppURLopener()
url = "http://creatim.allyes.com.cn/imedia/csdn/20150228/15_41_49_5B9C9E6A.jpg"
filename = os.path.basename(url)
urllib.urlretrieve(url , filename)登录后复制
但是上面这种分析HTML来爬取网站内容的方法存在很多弊端,譬如:
1.正则表达式被HTML源码所约束,而不是取决于更抽象的结构;网页结构中很小的改动可能会导致程序的中断。
2.程序需要根据实际HTML源码分析内容,可能会遇到字符实体如&之类的HTML特性,需要指定处理如、图标超链接、下标等不同内容。
3.正则表达式并不是完全可读的,更复杂的HTML代码和查询表达式会变得很乱。
正如《Python基础教程(第2版)》采用两种解决方案:第一个是使用Tidy(Python库)的程序和XHTML解析;第二个是使用BeautifulSoup库。
二. 安装及介绍Beautiful Soup库
Beautiful Soup是用Python写的一个HTML/XML的解析器,它可以很好的处理不规范标记并生成剖析树(parse tree)。 它提供简单又常用的导航navigating,搜索以及修改剖析树的操作。它可以大大节省你的编程时间。
正如书中所说“那些糟糕的网页不是你写的,你只是试图从中获得一些数据。现在你不用关心HTML是什么样子的,解析器帮你实现”。
下载地址:
//m.sbmmt.com/
//m.sbmmt.com/
安装过程如下图所示:python setup.py install

具体使用方法建议参照中文:
//m.sbmmt.com/
其中BeautifulSoup的用法简单讲解下,使用“爱丽丝梦游仙境”的官方例子:
#!/usr/bin/python
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
#获取BeautifulSoup对象并按标准缩进格式输出
soup = BeautifulSoup(html_doc)
print(soup.prettify())
登录后复制
输出内容按照标准的缩进格式的结构输出如下:
<html>
<head>
<title>
The Dormouse's story
</title>
</head>
<body>
<p class="title">
<b>
The Dormouse's story
</b>
</p>
<p class="story">
Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1">
Elsie
</a>
,
<a class="sister" href="http://example.com/lacie" id="link2">
Lacie
</a>
and
<a class="sister" href="http://example.com/tillie" id="link3">
Tillie
</a>
;
and they lived at the bottom of a well.
</p>
<p class="story">
...
</p>
</body>
</html>登录后复制
下面是BeautifulSoup库简单快速入门介绍:(参考:官方文档)
'''获取title值'''
print soup.title
# <title>The Dormouse's story</title>
print soup.title.name
# title
print unicode(soup.title.string)
# The Dormouse's story
'''获取<p>值'''
print soup.p
# <p class="title"><b>The Dormouse's story</b></p>
print soup.a
# <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
'''从文档中找到<a>的所有标签链接'''
print soup.find_all('a')
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
for link in soup.find_all('a'):
print(link.get('href'))
# //m.sbmmt.com/
# //m.sbmmt.com/
# //m.sbmmt.com/
print soup.find(id='link3')
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>登录后复制
如果想获取文章中所有文字内容,代码如下:
'''从文档中获取所有文字内容'''
print soup.get_text()
# The Dormouse's story
#
# The Dormouse's story
#
# Once upon a time there were three little sisters; and their names were
# Elsie,
# Lacie and
# Tillie;
# and they lived at the bottom of a well.
#
# ...
登录后复制
同时在这过程中你可能会遇到两个典型的错误提示:
1.ImportError: No module named BeautifulSoup
当你成功安装BeautifulSoup 4库后,“from BeautifulSoup import BeautifulSoup”可能会遇到该错误。

其中的原因是BeautifulSoup 4库改名为bs4,需要使用“from bs4 import BeautifulSoup”导入。
2.TypeError: an integer is required
当你使用“print soup.title.string”获取title的值时,可能会遇到该错误。如下:
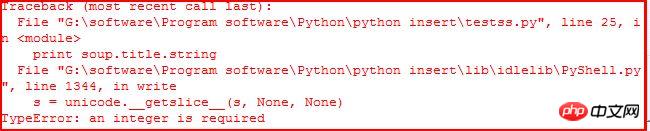
它应该是IDLE的BUG,当使用命令行Command没有任何错误。参考:stackoverflow。同时可以通过下面的代码解决该问题:
print unicode(soup.title.string)
print str(soup.title.string)
三. Beautiful Soup常用方法介绍
Beautiful Soup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为4种:Tag、NavigableString、BeautifulSoup、Comment|
1.Tag标签
tag对象与XML或HTML文档中的tag相同,它有很多方法和属性。其中最重要的属性name和attribute。用法如下:
#!/usr/bin/python
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
html = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title" id="start"><b>The Dormouse's story</b></p>
"""
soup = BeautifulSoup(html)
tag = soup.p
print tag
# <p class="title" id="start"><b>The Dormouse's story</b></p>
print type(tag)
# <class 'bs4.element.Tag'>
print tag.name
# p 标签名字
print tag['class']
# [u'title']
print tag.attrs
# {u'class': [u'title'], u'id': u'start'}登录后复制
使用BeautifulSoup每个tag都有自己的名字,可以通过.name来获取;同样一个tag可能有很多个属性,属性的操作方法与字典相同,可以直接通过“.attrs”获取属性。至于修改、删除操作请参考文档。
2.NavigableString
字符串常被包含在tag内,Beautiful Soup用NavigableString类来包装tag中的字符串。一个NavigableString字符串与Python中的Unicode字符串相同,并且还支持包含在遍历文档树和搜索文档树中的一些特性,通过unicode()方法可以直接将NavigableString对象转换成Unicode字符串。
print unicode(tag.string)
# The Dormouse's story
print type(tag.string)
# <class 'bs4.element.NavigableString'>
tag.string.replace_with("No longer bold")
print tag
# <p class="title" id="start"><b>No longer bold</b></p>登录后复制
这是获取“The Dormouse's story
”中tag = soup.p的值,其中tag中包含的字符串不能编辑,但可通过函数replace_with()替换。
NavigableString 对象支持遍历文档树和搜索文档树 中定义的大部分属性, 并非全部。尤其是一个字符串不能包含其它内容(tag能够包含字符串或是其它tag),字符串不支持 .contents 或 .string 属性或 find() 方法。
如果想在Beautiful Soup之外使用 NavigableString 对象,需要调用 unicode() 方法,将该对象转换成普通的Unicode字符串,否则就算Beautiful Soup已方法已经执行结束,该对象的输出也会带有对象的引用地址。这样会浪费内存。
3.Beautiful Soup对象
该对象表示的是一个文档的全部内容,大部分时候可以把它当做Tag对象,它支持遍历文档树和搜索文档树中的大部分方法。
注意:因为BeautifulSoup对象并不是真正的HTML或XML的tag,所以它没有name和 attribute属性,但有时查看它的.name属性可以通过BeautifulSoup对象包含的一个值为[document]的特殊实行.name实现——soup.name。
Beautiful Soup中定义的其它类型都可能会出现在XML的文档中:CData , ProcessingInstruction , Declaration , Doctype 。与 Comment 对象类似,这些类都是 NavigableString 的子类,只是添加了一些额外的方法的字符串独享。
4.Command注释
Tag、NavigableString、BeautifulSoup几乎覆盖了html和xml中的所有内容,但是还有些特殊对象容易让人担心——注释。Comment对象是一个特殊类型的NavigableString对象。
markup = "<b><!--Hey, buddy. Want to buy a used parser?--></b>"
soup = BeautifulSoup(markup)
comment = soup.b.string
print type(comment)
# <class 'bs4.element.Comment'>
print unicode(comment)
# Hey, buddy. Want to buy a used parser?
登录后复制
介绍完这四个对象后,下面简单介绍遍历文档树和搜索文档树及常用的函数。
5.遍历文档树
一个Tag可能包含多个字符串或其它的Tag,这些都是这个Tag的子节点。BeautifulSoup提供了许多操作和遍历子节点的属性。引用官方文档中爱丽丝例子:
操作文档最简单的方法是告诉你想获取tag的name,如下:
soup.head# <head><title>The Dormouse's story</title></head>soup.title# <title>The Dormouse's story</title>soup.body.b# <b>The Dormouse's story</b>
登录后复制
注意:通过点取属性的放是只能获得当前名字的第一个Tag,同时可以在文档树的tag中多次调用该方法如soup.body.b获取标签中第一个标签。
如果想得到所有的标签,使用方法find_all(),在前面的Python爬取维基百科等HTML中我们经常用到它+正则表达式的方法。
soup.find_all('a')# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
登录后复制
子节点:在分析HTML过程中通常需要分析tag的子节点,而tag的 .contents 属性可以将tag的子节点以列表的方式输出。字符串没有.contents属性,因为字符串没有子节点。
head_tag = soup.head
head_tag
# <head><title>The Dormouse's story</title></head>
head_tag.contents
[<title>The Dormouse's story</title>]
title_tag = head_tag.contents[0]
title_tag
# <title>The Dormouse's story</title>
title_tag.contents
# [u'The Dormouse's story']
登录后复制
通过tag的 .children 生成器,可以对tag的子节点进行循环:
for child in title_tag.children:
print(child)
# The Dormouse's story登录后复制
子孙节点:同样 .descendants 属性可以对所有tag的子孙节点进行递归循环:
for child in head_tag.descendants:
print(child)
# <title>The Dormouse's story</title>
# The Dormouse's story登录后复制
父节点:通过 .parent 属性来获取某个元素的父节点.在例子“爱丽丝”的文档中,标签是标签的父节点,换句话就是增加一层标签。<br/> <span style="color:#ff0000">注意:文档的顶层节点比如<html>的父节点是 BeautifulSoup 对象,BeautifulSoup 对象的 .parent 是None。</span><br/></span></strong></p><div class="code" style="position:relative; padding:0px; margin:0px;"><pre style="overflow-x:auto; overflow-y:hidden; padding:5px; line-height:15.6000003814697px; border-top-width:1px; border-bottom-width:1px; border-style:solid none; border-top-color:rgb(170,204,153); border-bottom-color:rgb(170,204,153); background-color:rgb(238,255,204)">title_tag = soup.titletitle_tag# <title>The Dormouse's story</title>title_tag.parent# <head><title>The Dormouse's story</title></head>title_tag.string.parent# <title>The Dormouse's story</title></pre><div class="contentsignin">登录后复制</div></div><p><strong><span style="font-size:18px"> <span style="color:#ff0000">兄弟节点</span>:因为<b>标签和<c>标签是同一层:他们是同一个元素的子节点,所以<b>和<c>可以被称为兄弟节点。一段文档以标准格式输出时,兄弟节点有相同的缩进级别.在代码中也可以使用这种关系。</span></strong><br/></p><div class="code" style="position:relative; padding:0px; margin:0px;"><pre style="overflow-x:auto; overflow-y:hidden; padding:5px; color:rgb(51,51,51); line-height:15.6000003814697px; border-top-width:1px; border-bottom-width:1px; border-style:solid none; border-top-color:rgb(170,204,153); border-bottom-color:rgb(170,204,153); background-color:rgb(238,255,204)">sibling_soup = BeautifulSoup("<a><b>text1</b><c>text2</c></b></a>")print(sibling_soup.prettify())# <html># <body># <a># <b># text1# </b># <c># text2# </c># </a># </body># </html></pre><div class="contentsignin">登录后复制</div></div><p><strong><span style="font-size:18px"> <span style="color:#ff0000">在文档树中,使用 .next_sibling 和 .previous_sibling 属性来查询兄弟节点。<b>标签有.next_sibling 属性,但是没有.previous_sibling 属性,因为<b>标签在同级节点中是第一个。同理<c>标签有.previous_sibling 属性,却没有.next_sibling 属性:</span></span></strong><br/></p><div class="code" style="position:relative; padding:0px; margin:0px;"><pre style="overflow-x:auto; overflow-y:hidden; padding:5px; color:rgb(51,51,51); line-height:15.6000003814697px; border-top-width:1px; border-bottom-width:1px; border-style:solid none; border-top-color:rgb(170,204,153); border-bottom-color:rgb(170,204,153); background-color:rgb(238,255,204)">sibling_soup.b.next_sibling# <c>text2</c>sibling_soup.c.previous_sibling# <b>text1</b></pre><div class="contentsignin">登录后复制</div></div><p><strong><span style="font-size:18px"> 介绍到这里基本就可以实现我们的BeautifulSoup库爬取网页内容,而网页修改、删除等内容建议大家阅读文档。下一篇文章就再次爬取维基百科的程序语言的内容吧!希望文章对大家有所帮助,如果有错误或不足之处,还请海涵!建议大家阅读官方文档和《Python基础教程》书。</span><br><span style="font-size:18px; color:rgb(51,51,51); font-family:Arial; line-height:26px"> </span><span style="font-size:18px; font-family:Arial; line-height:26px"><span style="color:#ff0000"> (By:Eastmount 2015-3-25 下午6点</span></span><span style="font-size:18px; color:rgb(51,51,51); font-family:Arial; line-height:26px">
</span>//m.sbmmt.com/<span style="font-family:Arial; color:#ff0000"><span style="font-size:18px; line-height:26px">)</span></span></strong><br></p>
<p></p>
<p><br></p>
<p class="pmark"><br></p>
<p>
</p><p>以上是Python之BeautifulSoup库安装及其简介的详细内容。更多信息请关注PHP中文网其他相关文章!</p> </div>
</div>
<div style="height: 25px;">
<div class="wzconBq" style="display: inline-flex;">
<span>相关标签:</span>
<div class="wzcbqd">
<a onclick="hits_log(2,'www',this);" href-data="//m.sbmmt.com/zh/search?word=beautifulsoup" target="_blank">beautifulsoup</a> <a onclick="hits_log(2,'www',this);" href-data="//m.sbmmt.com/zh/search?word=python" target="_blank">python</a> <a onclick="hits_log(2,'www',this);" href-data="//m.sbmmt.com/zh/search?word=知识" target="_blank">知识</a> </div>
</div>
<div style="display: inline-flex;float: right; color:#333333;">来源:php.cn</div>
</div>
<div class="wzconOtherwz">
<a href="//m.sbmmt.com/zh/faq/355982.html" title="详解pyhon中方法、属性、迭代器">
<span>上一篇:详解pyhon中方法、属性、迭代器</span>
</a>
<a href="//m.sbmmt.com/zh/faq/356004.html" title="Python中函数map()和reduce()的用法">
<span>下一篇:Python中函数map()和reduce()的用法</span>
</a>
</div>
<div class="wzconShengming">
<div class="bzsmdiv">本站声明</div>
<div>本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系admin@php.cn</div>
</div>
<ins class="adsbygoogle"
style="display:block"
data-ad-format="autorelaxed"
data-ad-client="ca-pub-5902227090019525"
data-ad-slot="2507867629"></ins>
<script>
(adsbygoogle = window.adsbygoogle || []).push({});
</script>
<div class="wzconZzwz">
<div class="wzconZzwztitle">作者最新文章</div>
<ul>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots"></span>
<a target="_blank" href="//m.sbmmt.com/zh/faq/354750.html">html设置加粗、倾斜、下划线、删除线等字体效果示例介绍</a>
</div>
<div>1970-01-01 08:00:00</div>
</li>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots"></span>
<a target="_blank" href="//m.sbmmt.com/zh/faq/338018.html">实现一个 Java 版的 Redis</a>
</div>
<div>1970-01-01 08:00:00</div>
</li>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots"></span>
<a target="_blank" href="//m.sbmmt.com/zh/faq/353509.html">最简单的微信小程序Demo</a>
</div>
<div>1970-01-01 08:00:00</div>
</li>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots"></span>
<a target="_blank" href="//m.sbmmt.com/zh/faq/356272.html">python中pandas.DataFrame(创建、索引、增添与删除)的简单操作方法介绍</a>
</div>
<div>1970-01-01 08:00:00</div>
</li>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots"></span>
<a target="_blank" href="//m.sbmmt.com/zh/faq/354839.html"> 微信小程序:如何实现tabs选项卡效果示例</a>
</div>
<div>1970-01-01 08:00:00</div>
</li>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots"></span>
<a target="_blank" href="//m.sbmmt.com/zh/faq/354423.html">Python构造自定义方法来美化字典结构输出</a>
</div>
<div>1970-01-01 08:00:00</div>
</li>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots"></span>
<a target="_blank" href="//m.sbmmt.com/zh/faq/350853.html">HTML5:使用Canvas实时处理Video</a>
</div>
<div>1970-01-01 08:00:00</div>
</li>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots"></span>
<a target="_blank" href="//m.sbmmt.com/zh/faq/346502.html">Asp.net使用SignalR实现发送图片</a>
</div>
<div>1970-01-01 08:00:00</div>
</li>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots"></span>
<a target="_blank" href="//m.sbmmt.com/zh/faq/354842.html">微信小程序开发教程-App()和Page()函数概述</a>
</div>
<div>1970-01-01 08:00:00</div>
</li>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots"></span>
<a target="_blank" href="//m.sbmmt.com/zh/faq/356574.html">详解python redis使用方法</a>
</div>
<div>1970-01-01 08:00:00</div>
</li>
</ul>
</div>
<div class="wzconZzwz">
<div class="wzconZzwztitle">最新问题</div>
<div class="wdsyContent">
<div class="wdsyConDiv flexRow wdsyConDiv1">
<div class="wdcdContent flexColumn">
<a href="//m.sbmmt.com/zh/wenda/175783.html" target="_blank" title="如何使用 BeautifulSoup 抓取特定的谷歌天气文本?" class="wdcdcTitle">如何使用 BeautifulSoup 抓取特定的谷歌天气文本?</a>
<a href="//m.sbmmt.com/zh/wenda/175783.html" class="wdcdcCons">如何使用BeautifulSoup在Python中找到课程文本“美国纽约市”?尝试复制视频进行练习,但不再有效。尝试在官方文档中找到一些内容,但没有成功。或者我的get_html_...</a>
<div class="wdcdcInfo flexRow">
<div class="wdcdcileft">
<span class="wdcdciSpan"> 来自于 2024-04-01 14:06:14</span>
</div>
<div class="wdcdciright flexRow">
<div class="wdcdcirdz flexRow ira"> <b class="wdcdcirdzi"></b>0 </div>
<div class="wdcdcirpl flexRow ira"><b class="wdcdcirpli"></b>1</div>
<div class="wdcdcirwatch flexRow ira"><b class="wdcdcirwatchi"></b>308</div>
</div>
</div>
</div>
</div>
<div class="wdsyConLine wdsyConLine2"></div>
</div>
</div>
<div class="wzconZt" >
<div class="wzczt-title">
<div>相关专题</div>
<a href="//m.sbmmt.com/zh/faq/zt" target="_blank">更多>
</a>
</div>
<div class="wzcttlist">
<ul>
<li class="ul-li">
<a target="_blank" href="//m.sbmmt.com/zh/faq/pythonkfgj"><img src="https://img.php.cn/upload/subject/202407/22/2024072214424826783.jpg?x-oss-process=image/resize,m_fill,h_145,w_220" alt="python开发工具" /> </a>
<a target="_blank" href="//m.sbmmt.com/zh/faq/pythonkfgj" class="title-a-spanl" title="python开发工具"><span>python开发工具</span> </a>
</li>
<li class="ul-li">
<a target="_blank" href="//m.sbmmt.com/zh/faq/pythondb"><img src="https://img.php.cn/upload/subject/202407/22/2024072214312147925.jpg?x-oss-process=image/resize,m_fill,h_145,w_220" alt="python打包成可执行文件" /> </a>
<a target="_blank" href="//m.sbmmt.com/zh/faq/pythondb" class="title-a-spanl" title="python打包成可执行文件"><span>python打包成可执行文件</span> </a>
</li>
<li class="ul-li">
<a target="_blank" href="//m.sbmmt.com/zh/faq/pythonnzsm"><img src="https://img.php.cn/upload/subject/202407/22/2024072214301218201.jpg?x-oss-process=image/resize,m_fill,h_145,w_220" alt="python能做什么" /> </a>
<a target="_blank" href="//m.sbmmt.com/zh/faq/pythonnzsm" class="title-a-spanl" title="python能做什么"><span>python能做什么</span> </a>
</li>
<li class="ul-li">
<a target="_blank" href="//m.sbmmt.com/zh/faq/formatzpython"><img src="https://img.php.cn/upload/subject/202407/22/2024072214275096159.jpg?x-oss-process=image/resize,m_fill,h_145,w_220" alt="format在python中的用法" /> </a>
<a target="_blank" href="//m.sbmmt.com/zh/faq/formatzpython" class="title-a-spanl" title="format在python中的用法"><span>format在python中的用法</span> </a>
</li>
<li class="ul-li">
<a target="_blank" href="//m.sbmmt.com/zh/faq/pythonjc"><img src="https://img.php.cn/upload/subject/202407/22/2024072214254329480.jpg?x-oss-process=image/resize,m_fill,h_145,w_220" alt="python教程" /> </a>
<a target="_blank" href="//m.sbmmt.com/zh/faq/pythonjc" class="title-a-spanl" title="python教程"><span>python教程</span> </a>
</li>
<li class="ul-li">
<a target="_blank" href="//m.sbmmt.com/zh/faq/pythonhjblbz"><img src="https://img.php.cn/upload/subject/202407/22/2024072214252616529.jpg?x-oss-process=image/resize,m_fill,h_145,w_220" alt="python环境变量的配置" /> </a>
<a target="_blank" href="//m.sbmmt.com/zh/faq/pythonhjblbz" class="title-a-spanl" title="python环境变量的配置"><span>python环境变量的配置</span> </a>
</li>
<li class="ul-li">
<a target="_blank" href="//m.sbmmt.com/zh/faq/pythoneval"><img src="https://img.php.cn/upload/subject/202407/22/2024072214251549631.jpg?x-oss-process=image/resize,m_fill,h_145,w_220" alt="蟒蛇评估" /> </a>
<a target="_blank" href="//m.sbmmt.com/zh/faq/pythoneval" class="title-a-spanl" title="蟒蛇评估"><span>蟒蛇评估</span> </a>
</li>
<li class="ul-li">
<a target="_blank" href="//m.sbmmt.com/zh/faq/scratchpyt"><img src="https://img.php.cn/upload/subject/202407/22/2024072214235344903.jpg?x-oss-process=image/resize,m_fill,h_145,w_220" alt="scratch和python区别" /> </a>
<a target="_blank" href="//m.sbmmt.com/zh/faq/scratchpyt" class="title-a-spanl" title="scratch和python区别"><span>scratch和python区别</span> </a>
</li>
</ul>
</div>
</div>
</div>
</div>
<div class="phpwzright">
<ins class="adsbygoogle"
style="display:block"
data-ad-client="ca-pub-5902227090019525"
data-ad-slot="3653428331"
data-ad-format="auto"
data-full-width-responsive="true"></ins>
<script>
(adsbygoogle = window.adsbygoogle || []).push({});
</script>
<div class="wzrOne">
<div class="wzroTitle">热门推荐</div>
<div class="wzroList">
<ul>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots wzrolr"></span>
<a style="height: auto;" title="python中eval是什么意思?" href="//m.sbmmt.com/zh/faq/419793.html">python中eval是什么意思?</a>
</div>
</li>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots wzrolr"></span>
<a style="height: auto;" title="python如何读取txt文件内容" href="//m.sbmmt.com/zh/faq/479676.html">python如何读取txt文件内容</a>
</div>
</li>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots wzrolr"></span>
<a style="height: auto;" title="py文件怎么打开?" href="//m.sbmmt.com/zh/faq/418747.html">py文件怎么打开?</a>
</div>
</li>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots wzrolr"></span>
<a style="height: auto;" title="python中str是什么意思" href="//m.sbmmt.com/zh/faq/419809.html">python中str是什么意思</a>
</div>
</li>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots wzrolr"></span>
<a style="height: auto;" title="python中format怎么用" href="//m.sbmmt.com/zh/faq/471817.html">python中format怎么用</a>
</div>
</li>
</ul>
</div>
</div>
<script src="https://sw.php.cn/hezuo/cac1399ab368127f9b113b14eb3316d0.js" type="text/javascript"></script>
<div class="wzrThree">
<div class="wzrthree-title">
<div>热门教程</div>
<a target="_blank" href="//m.sbmmt.com/zh/course.html">更多>
</a>
</div>
<div class="wzrthreelist swiper2">
<div class="wzrthreeTab swiper-wrapper">
<div class="check tabdiv swiper-slide" data-id="one">相关教程 <div></div></div>
<div class="tabdiv swiper-slide" data-id="two">热门推荐<div></div></div>
<div class="tabdiv swiper-slide" data-id="three">最新课程<div></div></div>
</div>
<ul class="one">
<li>
<a target="_blank" href="//m.sbmmt.com/zh/course/812.html" title="最新ThinkPHP 5.1全球首发视频教程(60天成就PHP大牛线上培训班课)" class="wzrthreelaimg">
<img src="https://img.php.cn/upload/course/000/000/041/620debc3eab3f377.jpg" alt="最新ThinkPHP 5.1全球首发视频教程(60天成就PHP大牛线上培训班课)"/>
</a>
<div class="wzrthree-right">
<a target="_blank" title="最新ThinkPHP 5.1全球首发视频教程(60天成就PHP大牛线上培训班课)" href="//m.sbmmt.com/zh/course/812.html">最新ThinkPHP 5.1全球首发视频教程(60天成就PHP大牛线上培训班课)</a>
<div class="wzrthreerb">
<div>1427566 <b class="kclbcollectb"></b></div>
<div class="courseICollection" data-id="812">
<b class="nofollow small-nocollect"></b>
</div>
</div>
</div>
</li>
<li>
<a target="_blank" href="//m.sbmmt.com/zh/course/74.html" title="php入门教程之一周学会PHP" class="wzrthreelaimg">
<img src="https://img.php.cn/upload/course/000/000/068/6253d1e28ef5c345.png" alt="php入门教程之一周学会PHP"/>
</a>
<div class="wzrthree-right">
<a target="_blank" title="php入门教程之一周学会PHP" href="//m.sbmmt.com/zh/course/74.html">php入门教程之一周学会PHP</a>
<div class="wzrthreerb">
<div>4277973 <b class="kclbcollectb"></b></div>
<div class="courseICollection" data-id="74">
<b class="nofollow small-nocollect"></b>
</div>
</div>
</div>
</li>
<li>
<a target="_blank" href="//m.sbmmt.com/zh/course/286.html" title="JAVA 初级入门视频教程" class="wzrthreelaimg">
<img src="https://img.php.cn/upload/course/000/000/068/62590a2bacfd9379.png" alt="JAVA 初级入门视频教程"/>
</a>
<div class="wzrthree-right">
<a target="_blank" title="JAVA 初级入门视频教程" href="//m.sbmmt.com/zh/course/286.html">JAVA 初级入门视频教程</a>
<div class="wzrthreerb">
<div>2578507 <b class="kclbcollectb"></b></div>
<div class="courseICollection" data-id="286">
<b class="nofollow small-nocollect"></b>
</div>
</div>
</div>
</li>
<li>
<a target="_blank" href="//m.sbmmt.com/zh/course/504.html" title="小甲鱼零基础入门学习Python视频教程" class="wzrthreelaimg">
<img src="https://img.php.cn/upload/course/000/000/068/62590a67ce3a6655.png" alt="小甲鱼零基础入门学习Python视频教程"/>
</a>
<div class="wzrthree-right">
<a target="_blank" title="小甲鱼零基础入门学习Python视频教程" href="//m.sbmmt.com/zh/course/504.html">小甲鱼零基础入门学习Python视频教程</a>
<div class="wzrthreerb">
<div>510352 <b class="kclbcollectb"></b></div>
<div class="courseICollection" data-id="504">
<b class="nofollow small-nocollect"></b>
</div>
</div>
</div>
</li>
<li>
<a target="_blank" href="//m.sbmmt.com/zh/course/2.html" title="PHP 零基础入门教程" class="wzrthreelaimg">
<img src="https://img.php.cn/upload/course/000/000/068/6253de27bc161468.png" alt="PHP 零基础入门教程"/>
</a>
<div class="wzrthree-right">
<a target="_blank" title="PHP 零基础入门教程" href="//m.sbmmt.com/zh/course/2.html">PHP 零基础入门教程</a>
<div class="wzrthreerb">
<div>867541 <b class="kclbcollectb"></b></div>
<div class="courseICollection" data-id="2">
<b class="nofollow small-nocollect"></b>
</div>
</div>
</div>
</li>
</ul>
<ul class="two" style="display: none;">
<li>
<a target="_blank" href="//m.sbmmt.com/zh/course/812.html" title="最新ThinkPHP 5.1全球首发视频教程(60天成就PHP大牛线上培训班课)" class="wzrthreelaimg">
<img src="https://img.php.cn/upload/course/000/000/041/620debc3eab3f377.jpg" alt="最新ThinkPHP 5.1全球首发视频教程(60天成就PHP大牛线上培训班课)"/>
</a>
<div class="wzrthree-right">
<a target="_blank" title="最新ThinkPHP 5.1全球首发视频教程(60天成就PHP大牛线上培训班课)" href="//m.sbmmt.com/zh/course/812.html">最新ThinkPHP 5.1全球首发视频教程(60天成就PHP大牛线上培训班课)</a>
<div class="wzrthreerb">
<div >1427566次学习</div>
<div class="courseICollection" data-id="812">
<b class="nofollow small-nocollect"></b>
</div>
</div>
</div>
</li>
<li>
<a target="_blank" href="//m.sbmmt.com/zh/course/286.html" title="JAVA 初级入门视频教程" class="wzrthreelaimg">
<img src="https://img.php.cn/upload/course/000/000/068/62590a2bacfd9379.png" alt="JAVA 初级入门视频教程"/>
</a>
<div class="wzrthree-right">
<a target="_blank" title="JAVA 初级入门视频教程" href="//m.sbmmt.com/zh/course/286.html">JAVA 初级入门视频教程</a>
<div class="wzrthreerb">
<div >2578507次学习</div>
<div class="courseICollection" data-id="286">
<b class="nofollow small-nocollect"></b>
</div>
</div>
</div>
</li>
<li>
<a target="_blank" href="//m.sbmmt.com/zh/course/504.html" title="小甲鱼零基础入门学习Python视频教程" class="wzrthreelaimg">
<img src="https://img.php.cn/upload/course/000/000/068/62590a67ce3a6655.png" alt="小甲鱼零基础入门学习Python视频教程"/>
</a>
<div class="wzrthree-right">
<a target="_blank" title="小甲鱼零基础入门学习Python视频教程" href="//m.sbmmt.com/zh/course/504.html">小甲鱼零基础入门学习Python视频教程</a>
<div class="wzrthreerb">
<div >510352次学习</div>
<div class="courseICollection" data-id="504">
<b class="nofollow small-nocollect"></b>
</div>
</div>
</div>
</li>
<li>
<a target="_blank" href="//m.sbmmt.com/zh/course/901.html" title="Web前端开发极速入门" class="wzrthreelaimg">
<img src="https://img.php.cn/upload/course/000/000/067/64be28a53a4f6310.png" alt="Web前端开发极速入门"/>
</a>
<div class="wzrthree-right">
<a target="_blank" title="Web前端开发极速入门" href="//m.sbmmt.com/zh/course/901.html">Web前端开发极速入门</a>
<div class="wzrthreerb">
<div >216284次学习</div>
<div class="courseICollection" data-id="901">
<b class="nofollow small-nocollect"></b>
</div>
</div>
</div>
</li>
<li>
<a target="_blank" href="//m.sbmmt.com/zh/course/234.html" title="零基础精通 PS 视频教程" class="wzrthreelaimg">
<img src="https://img.php.cn/upload/course/000/000/068/62611f57ed0d4840.jpg" alt="零基础精通 PS 视频教程"/>
</a>
<div class="wzrthree-right">
<a target="_blank" title="零基础精通 PS 视频教程" href="//m.sbmmt.com/zh/course/234.html">零基础精通 PS 视频教程</a>
<div class="wzrthreerb">
<div >899573次学习</div>
<div class="courseICollection" data-id="234">
<b class="nofollow small-nocollect"></b>
</div>
</div>
</div>
</li>
</ul>
<ul class="three" style="display: none;">
<li>
<a target="_blank" href="//m.sbmmt.com/zh/course/1648.html" title="【web前端】Node.js快速入门" class="wzrthreelaimg">
<img src="https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png" alt="【web前端】Node.js快速入门"/>
</a>
<div class="wzrthree-right">
<a target="_blank" title="【web前端】Node.js快速入门" href="//m.sbmmt.com/zh/course/1648.html">【web前端】Node.js快速入门</a>
<div class="wzrthreerb">
<div >8224次学习</div>
<div class="courseICollection" data-id="1648">
<b class="nofollow small-nocollect"></b>
</div>
</div>
</div>
</li>
<li>
<a target="_blank" href="//m.sbmmt.com/zh/course/1647.html" title="国外Web开发全栈课程全集" class="wzrthreelaimg">
<img src="https://img.php.cn/upload/course/000/000/067/6628cc96e310c937.png" alt="国外Web开发全栈课程全集"/>
</a>
<div class="wzrthree-right">
<a target="_blank" title="国外Web开发全栈课程全集" href="//m.sbmmt.com/zh/course/1647.html">国外Web开发全栈课程全集</a>
<div class="wzrthreerb">
<div >6558次学习</div>
<div class="courseICollection" data-id="1647">
<b class="nofollow small-nocollect"></b>
</div>
</div>
</div>
</li>
<li>
<a target="_blank" href="//m.sbmmt.com/zh/course/1646.html" title="Go语言实战之 GraphQL" class="wzrthreelaimg">
<img src="https://img.php.cn/upload/course/000/000/067/662221173504a436.png" alt="Go语言实战之 GraphQL"/>
</a>
<div class="wzrthree-right">
<a target="_blank" title="Go语言实战之 GraphQL" href="//m.sbmmt.com/zh/course/1646.html">Go语言实战之 GraphQL</a>
<div class="wzrthreerb">
<div >5409次学习</div>
<div class="courseICollection" data-id="1646">
<b class="nofollow small-nocollect"></b>
</div>
</div>
</div>
</li>
<li>
<a target="_blank" href="//m.sbmmt.com/zh/course/1645.html" title="550W粉丝大佬手把手从零学JavaScript" class="wzrthreelaimg">
<img src="https://img.php.cn/upload/course/000/000/067/662077e163124646.png" alt="550W粉丝大佬手把手从零学JavaScript"/>
</a>
<div class="wzrthree-right">
<a target="_blank" title="550W粉丝大佬手把手从零学JavaScript" href="//m.sbmmt.com/zh/course/1645.html">550W粉丝大佬手把手从零学JavaScript</a>
<div class="wzrthreerb">
<div >746次学习</div>
<div class="courseICollection" data-id="1645">
<b class="nofollow small-nocollect"></b>
</div>
</div>
</div>
</li>
<li>
<a target="_blank" href="//m.sbmmt.com/zh/course/1644.html" title="python大神Mosh,零基础小白6小时完全入门" class="wzrthreelaimg">
<img src="https://img.php.cn/upload/course/000/000/067/6616418ca80b8916.png" alt="python大神Mosh,零基础小白6小时完全入门"/>
</a>
<div class="wzrthree-right">
<a target="_blank" title="python大神Mosh,零基础小白6小时完全入门" href="//m.sbmmt.com/zh/course/1644.html">python大神Mosh,零基础小白6小时完全入门</a>
<div class="wzrthreerb">
<div >27660次学习</div>
<div class="courseICollection" data-id="1644">
<b class="nofollow small-nocollect"></b>
</div>
</div>
</div>
</li>
</ul>
</div>
<script>
var mySwiper = new Swiper('.swiper2', {
autoplay: false,//可选选项,自动滑动
slidesPerView : 'auto',
})
$('.wzrthreeTab>div').click(function(e){
$('.wzrthreeTab>div').removeClass('check')
$(this).addClass('check')
$('.wzrthreelist>ul').css('display','none')
$('.'+e.currentTarget.dataset.id).show()
})
</script>
</div>
<div class="wzrFour">
<div class="wzrfour-title">
<div>最新下载</div>
<a href="//m.sbmmt.com/zh/xiazai">更多>
</a>
</div>
<script>
$(document).ready(function(){
var sjyx_banSwiper = new Swiper(".sjyx_banSwiperwz",{
speed:1000,
autoplay:{
delay:3500,
disableOnInteraction: false,
},
pagination:{
el:'.sjyx_banSwiperwz .swiper-pagination',
clickable :false,
},
loop:true
})
})
</script>
<div class="wzrfourList swiper3">
<div class="wzrfourlTab swiper-wrapper">
<div class="check swiper-slide" data-id="onef">网站特效 <div></div></div>
<div class="swiper-slide" data-id="twof">网站源码<div></div></div>
<div class="swiper-slide" data-id="threef">网站素材<div></div></div>
<div class="swiper-slide" data-id="fourf">前端模板<div></div></div>
</div>
<ul class="onef">
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a target="_blank" title="jQuery企业留言表单联系代码" href="//m.sbmmt.com/zh/toolset/js-special-effects/8071">[表单按钮] jQuery企业留言表单联系代码</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a target="_blank" title="HTML5 MP3音乐盒播放特效" href="//m.sbmmt.com/zh/toolset/js-special-effects/8070">[播放器特效] HTML5 MP3音乐盒播放特效</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a target="_blank" title="HTML5炫酷粒子动画导航菜单特效" href="//m.sbmmt.com/zh/toolset/js-special-effects/8069">[菜单导航] HTML5炫酷粒子动画导航菜单特效</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a target="_blank" title="jQuery可视化表单拖拽编辑代码" href="//m.sbmmt.com/zh/toolset/js-special-effects/8068">[表单按钮] jQuery可视化表单拖拽编辑代码</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a target="_blank" title="VUE.JS仿酷狗音乐播放器代码" href="//m.sbmmt.com/zh/toolset/js-special-effects/8067">[播放器特效] VUE.JS仿酷狗音乐播放器代码</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a target="_blank" title="经典html5推箱子小游戏" href="//m.sbmmt.com/zh/toolset/js-special-effects/8066">[html5特效] 经典html5推箱子小游戏</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a target="_blank" title="jQuery滚动添加或减少图片特效" href="//m.sbmmt.com/zh/toolset/js-special-effects/8065">[图片特效] jQuery滚动添加或减少图片特效</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a target="_blank" title="CSS3个人相册封面悬停放大特效" href="//m.sbmmt.com/zh/toolset/js-special-effects/8064">[相册特效] CSS3个人相册封面悬停放大特效</a>
</div>
</li>
</ul>
<ul class="twof" style="display:none">
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/zh/toolset/website-source-code/8328" title="家居装潢清洁维修服务公司网站模板" target="_blank">[前端模板] 家居装潢清洁维修服务公司网站模板</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/zh/toolset/website-source-code/8327" title="清新配色个人求职简历引导页模板" target="_blank">[前端模板] 清新配色个人求职简历引导页模板</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/zh/toolset/website-source-code/8326" title="设计师创意求职简历网页模板" target="_blank">[前端模板] 设计师创意求职简历网页模板</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/zh/toolset/website-source-code/8325" title="现代工程建筑公司网站模板" target="_blank">[前端模板] 现代工程建筑公司网站模板</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/zh/toolset/website-source-code/8324" title="教育服务机构响应式HTML5模板" target="_blank">[前端模板] 教育服务机构响应式HTML5模板</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/zh/toolset/website-source-code/8323" title="网上电子书店商城网站模板" target="_blank">[前端模板] 网上电子书店商城网站模板</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/zh/toolset/website-source-code/8322" title="IT技术解决互联网公司网站模板" target="_blank">[前端模板] IT技术解决互联网公司网站模板</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/zh/toolset/website-source-code/8321" title="紫色风格外汇交易服务网站模板" target="_blank">[前端模板] 紫色风格外汇交易服务网站模板</a>
</div>
</li>
</ul>
<ul class="threef" style="display:none">
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/zh/toolset/website-materials/3078" target="_blank" title="可爱的夏天元素矢量素材(EPS+PNG)">[PNG素材] 可爱的夏天元素矢量素材(EPS+PNG)</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/zh/toolset/website-materials/3077" target="_blank" title="四个红的的 2023 毕业徽章矢量素材(AI+EPS+PNG)">[PNG素材] 四个红的的 2023 毕业徽章矢量素材(AI+EPS+PNG)</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/zh/toolset/website-materials/3076" target="_blank" title="唱歌的小鸟和装满花朵的推车设计春天banner矢量素材(AI+EPS)">[banner图] 唱歌的小鸟和装满花朵的推车设计春天banner矢量素材(AI+EPS)</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/zh/toolset/website-materials/3075" target="_blank" title="金色的毕业帽矢量素材(EPS+PNG)">[PNG素材] 金色的毕业帽矢量素材(EPS+PNG)</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/zh/toolset/website-materials/3074" target="_blank" title="黑白风格的山脉图标矢量素材(EPS+PNG)">[PNG素材] 黑白风格的山脉图标矢量素材(EPS+PNG)</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/zh/toolset/website-materials/3073" target="_blank" title="不同颜色披风和不同姿势的超级英雄剪影矢量素材(EPS+PNG)">[PNG素材] 不同颜色披风和不同姿势的超级英雄剪影矢量素材(EPS+PNG)</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/zh/toolset/website-materials/3072" target="_blank" title="扁平风格的植树节banner矢量素材(AI+EPS)">[banner图] 扁平风格的植树节banner矢量素材(AI+EPS)</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/zh/toolset/website-materials/3071" target="_blank" title="九个漫画风格的爆炸聊天气泡矢量素材(EPS+PNG)">[PNG素材] 九个漫画风格的爆炸聊天气泡矢量素材(EPS+PNG)</a>
</div>
</li>
</ul>
<ul class="fourf" style="display:none">
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/zh/toolset/website-source-code/8328" target="_blank" title="家居装潢清洁维修服务公司网站模板">[前端模板] 家居装潢清洁维修服务公司网站模板</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/zh/toolset/website-source-code/8327" target="_blank" title="清新配色个人求职简历引导页模板">[前端模板] 清新配色个人求职简历引导页模板</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/zh/toolset/website-source-code/8326" target="_blank" title="设计师创意求职简历网页模板">[前端模板] 设计师创意求职简历网页模板</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/zh/toolset/website-source-code/8325" target="_blank" title="现代工程建筑公司网站模板">[前端模板] 现代工程建筑公司网站模板</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/zh/toolset/website-source-code/8324" target="_blank" title="教育服务机构响应式HTML5模板">[前端模板] 教育服务机构响应式HTML5模板</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/zh/toolset/website-source-code/8323" target="_blank" title="网上电子书店商城网站模板">[前端模板] 网上电子书店商城网站模板</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/zh/toolset/website-source-code/8322" target="_blank" title="IT技术解决互联网公司网站模板">[前端模板] IT技术解决互联网公司网站模板</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/zh/toolset/website-source-code/8321" target="_blank" title="紫色风格外汇交易服务网站模板">[前端模板] 紫色风格外汇交易服务网站模板</a>
</div>
</li>
</ul>
</div>
<script>
var mySwiper = new Swiper('.swiper3', {
autoplay: false,//可选选项,自动滑动
slidesPerView : 'auto',
})
$('.wzrfourlTab>div').click(function(e){
$('.wzrfourlTab>div').removeClass('check')
$(this).addClass('check')
$('.wzrfourList>ul').css('display','none')
$('.'+e.currentTarget.dataset.id).show()
})
</script>
</div>
</div>
</div>
<footer>
<div class="footer">
<div class="footertop">
<img src="/static/imghw/logo.png" alt="">
<p>公益在线PHP培训,帮助PHP学习者快速成长!</p>
</div>
<div class="footermid">
<a href="//m.sbmmt.com/zh/about/us.html">关于我们</a>
<a href="//m.sbmmt.com/zh/about/disclaimer.html">免责声明</a>
<a href="//m.sbmmt.com/zh/update/article_0_1.html">Sitemap</a>
</div>
<div class="footerbottom">
<p>
© php.cn All rights reserved
</p>
</div>
</div>
</footer>
<input type="hidden" id="verifycode" value="/captcha.html">
<script>layui.use(['element', 'carousel'], function () {var element = layui.element;$ = layui.jquery;var carousel = layui.carousel;carousel.render({elem: '#test1', width: '100%', height: '330px', arrow: 'always'});$.getScript('/static/js/jquery.lazyload.min.js', function () {$("img").lazyload({placeholder: "/static/images/load.jpg", effect: "fadeIn", threshold: 200, skip_invisible: false});});});</script>
<script src="/static/js/common_new.js"></script>
<script type="text/javascript" src="/static/js/jquery.cookie.js?1736707044"></script>
<script src="https://vdse.bdstatic.com//search-video.v1.min.js"></script>
<link rel='stylesheet' id='_main-css' href='/static/css/viewer.min.css?2' type='text/css' media='all'/>
<script type='text/javascript' src='/static/js/viewer.min.js?1'></script>
<script type='text/javascript' src='/static/js/jquery-viewer.min.js'></script>
<script type="text/javascript" src="/static/js/global.min.js?5.5.53"></script>
<!-- Matomo -->
<script>
var _paq = window._paq = window._paq || [];
/* tracker methods like "setCustomDimension" should be called before "trackPageView" */
_paq.push(['trackPageView']);
_paq.push(['enableLinkTracking']);
(function() {
var u="https://tongji.php.cn/";
_paq.push(['setTrackerUrl', u+'matomo.php']);
_paq.push(['setSiteId', '9']);
var d=document, g=d.createElement('script'), s=d.getElementsByTagName('script')[0];
g.async=true; g.src=u+'matomo.js'; s.parentNode.insertBefore(g,s);
})();
</script>
<!-- End Matomo Code -->
</body>
</html>



