1. Scrapy简介
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试
Scrapy 使用了 Twisted异步网络库来处理网络通讯。整体架构大致如下
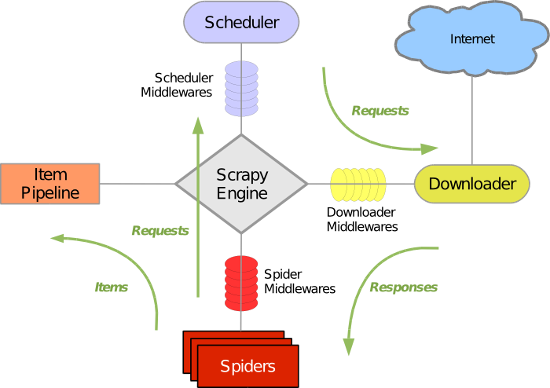
Scrapy主要包括了以下组件:
(1)引擎(Scrapy): 用来处理整个系统的数据流处理, 触发事务(框架核心)
(2)调度器(Scheduler): 用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址
(3)下载器(Downloader): 用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的)
(4)爬虫(Spiders): 爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面
项目管道(Pipeline): 负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
(5)下载器中间件(Downloader Middlewares): 位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。
(6)爬虫中间件(Spider Middlewares): 介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。
(7)调度中间件(Scheduler Middewares): 介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
Scrapy运行流程大概如下:
首先,引擎从调度器中取出一个链接(URL)用于接下来的抓取
引擎把URL封装成一个请求(Request)传给下载器,下载器把资源下载下来,并封装成应答包(Response)
然后,爬虫解析Response
若是解析出实体(Item),则交给实体管道进行进一步的处理。
若是解析出的是链接(URL),则把URL交给Scheduler等待抓取
2. 安装Scrapy
使用以下命令:
sudo pip install virtualenv #安装虚拟环境工具
virtualenv ENV #创建一个虚拟环境目录
source ./ENV/bin/active #激活虚拟环境
pip install Scrapy
#验证是否安装成功
pip list
登录后复制
#输出如下
cffi (0.8.6)
cryptography (0.6.1)
cssselect (0.9.1)
lxml (3.4.1)
pip (1.5.6)
pycparser (2.10)
pyOpenSSL (0.14)
queuelib (1.2.2)
Scrapy (0.24.4)
setuptools (3.6)
six (1.8.0)
Twisted (14.0.2)
w3lib (1.10.0)
wsgiref (0.1.2)
zope.interface (4.1.1)
登录后复制
更多虚拟环境的操作可以查看我的博文
3. Scrapy Tutorial
在抓取之前, 你需要新建一个Scrapy工程. 进入一个你想用来保存代码的目录,然后执行:
$ scrapy startproject tutorial
登录后复制
这个命令会在当前目录下创建一个新目录 tutorial, 它的结构如下:
.
├── scrapy.cfg
└── tutorial
├── __init__.py
├── items.py
├── pipelines.py
├── settings.py
└── spiders
└── __init__.py
登录后复制
这些文件主要是:
(1)scrapy.cfg: 项目配置文件
(2)tutorial/: 项目python模块, 之后您将在此加入代码
(3)tutorial/items.py: 项目items文件
(4)tutorial/pipelines.py: 项目管道文件
(5)tutorial/settings.py: 项目配置文件
(6)tutorial/spiders: 放置spider的目录
3.1. 定义Item
Items是将要装载抓取的数据的容器,它工作方式像 python 里面的字典,但它提供更多的保护,比如对未定义的字段填充以防止拼写错误
通过创建scrapy.Item类, 并且定义类型为 scrapy.Field 的类属性来声明一个Item.
我们通过将需要的item模型化,来控制从 dmoz.org 获得的站点数据,比如我们要获得站点的名字,url 和网站描述,我们定义这三种属性的域。在 tutorial 目录下的 items.py 文件编辑
from scrapy.item import Item, Field
class DmozItem(Item):
# define the fields for your item here like:
name = Field()
description = Field()
url = Field()
登录后复制
3.2. 编写Spider
Spider 是用户编写的类, 用于从一个域(或域组)中抓取信息, 定义了用于下载的URL的初步列表, 如何跟踪链接,以及如何来解析这些网页的内容用于提取items。
要建立一个 Spider,继承 scrapy.Spider 基类,并确定三个主要的、强制的属性:
name:爬虫的识别名,它必须是唯一的,在不同的爬虫中你必须定义不同的名字.
start_urls:包含了Spider在启动时进行爬取的url列表。因此,第一个被获取到的页面将是其中之一。后续的URL则从初始的URL获取到的数据中提取。我们可以利用正则表达式定义和过滤需要进行跟进的链接。
parse():是spider的一个方法。被调用时,每个初始URL完成下载后生成的 Response 对象将会作为唯一的参数传递给该函数。该方法负责解析返回的数据(response data),提取数据(生成item)以及生成需要进一步处理的URL的 Request 对象。
这个方法负责解析返回的数据、匹配抓取的数据(解析为 item )并跟踪更多的 URL。
在 /tutorial/tutorial/spiders 目录下创建 dmoz_spider.py
import scrapy
class DmozSpider(scrapy.Spider):
name = "dmoz"
allowed_domains = ["dmoz.org"]
start_urls = [
"http://www.dmoz.org/Computers/Programming/Languages/Python/Books/",
"http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/"
]
def parse(self, response):
filename = response.url.split("/")[-2]
with open(filename, 'wb') as f:
f.write(response.body)
登录后复制
3.3. 爬取
当前项目结构
├── scrapy.cfg
└── tutorial
├── __init__.py
├── items.py
├── pipelines.py
├── settings.py
└── spiders
├── __init__.py
└── dmoz_spider.py
登录后复制
到项目根目录, 然后运行命令:
$ scrapy crawl dmoz
登录后复制
运行结果:
2014-12-15 09:30:59+0800 [scrapy] INFO: Scrapy 0.24.4 started (bot: tutorial)
2014-12-15 09:30:59+0800 [scrapy] INFO: Optional features available: ssl, http11
2014-12-15 09:30:59+0800 [scrapy] INFO: Overridden settings: {'NEWSPIDER_MODULE': 'tutorial.spiders', 'SPIDER_MODULES': ['tutorial.spiders'], 'BOT_NAME': 'tutorial'}
2014-12-15 09:30:59+0800 [scrapy] INFO: Enabled extensions: LogStats, TelnetConsole, CloseSpider, WebService, CoreStats, SpiderState
2014-12-15 09:30:59+0800 [scrapy] INFO: Enabled downloader middlewares: HttpAuthMiddleware, DownloadTimeoutMiddleware, UserAgentMiddleware, RetryMiddleware, DefaultHeadersMiddleware, MetaRefreshMiddleware, HttpCompressionMiddleware, RedirectMiddleware, CookiesMiddleware, ChunkedTransferMiddleware, DownloaderStats
2014-12-15 09:30:59+0800 [scrapy] INFO: Enabled spider middlewares: HttpErrorMiddleware, OffsiteMiddleware, RefererMiddleware, UrlLengthMiddleware, DepthMiddleware
2014-12-15 09:30:59+0800 [scrapy] INFO: Enabled item pipelines:
2014-12-15 09:30:59+0800 [dmoz] INFO: Spider opened
2014-12-15 09:30:59+0800 [dmoz] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2014-12-15 09:30:59+0800 [scrapy] DEBUG: Telnet console listening on 127.0.0.1:6023
2014-12-15 09:30:59+0800 [scrapy] DEBUG: Web service listening on 127.0.0.1:6080
2014-12-15 09:31:00+0800 [dmoz] DEBUG: Crawled (200) <GET http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/> (referer: None)
2014-12-15 09:31:00+0800 [dmoz] DEBUG: Crawled (200) <GET http://www.dmoz.org/Computers/Programming/Languages/Python/Books/> (referer: None)
2014-12-15 09:31:00+0800 [dmoz] INFO: Closing spider (finished)
2014-12-15 09:31:00+0800 [dmoz] INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 516,
'downloader/request_count': 2,
'downloader/request_method_count/GET': 2,
'downloader/response_bytes': 16338,
'downloader/response_count': 2,
'downloader/response_status_count/200': 2,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2014, 12, 15, 1, 31, 0, 666214),
'log_count/DEBUG': 4,
'log_count/INFO': 7,
'response_received_count': 2,
'scheduler/dequeued': 2,
'scheduler/dequeued/memory': 2,
'scheduler/enqueued': 2,
'scheduler/enqueued/memory': 2,
'start_time': datetime.datetime(2014, 12, 15, 1, 30, 59, 533207)}
2014-12-15 09:31:00+0800 [dmoz] INFO: Spider closed (finished)
登录后复制
3.4. 提取Items
3.4.1. 介绍Selector
从网页中提取数据有很多方法。Scrapy使用了一种基于 XPath 或者 CSS 表达式机制: Scrapy Selectors
出XPath表达式的例子及对应的含义:
- /html/head/title: 选择HTML文档中 标签内的 元素</li>
<li>/html/head/title/text(): 选择 <title> 元素内的文本</li>
<li>//td: 选择所有的 <td> 元素</li>
<li>//div[@class="mine"]: 选择所有具有class="mine" 属性的 div 元素</li>
</ul>
<p>等多强大的功能使用可以查看XPath tutorial</p>
<p>为了方便使用 XPaths,Scrapy 提供 Selector 类, 有四种方法 :</p>
<ul>
<li>xpath():返回selectors列表, 每一个selector表示一个xpath参数表达式选择的节点.</li>
<li>css() : 返回selectors列表, 每一个selector表示CSS参数表达式选择的节点</li>
<li>extract():返回一个unicode字符串,该字符串为XPath选择器返回的数据</li>
<li>re(): 返回unicode字符串列表,字符串作为参数由正则表达式提取出来</li>
</ul>
<p><strong>3.4.2. 取出数据<br />
</strong></p>
<ul>
<li>首先使用谷歌浏览器开发者工具, 查看网站源码, 来看自己需要取出的数据形式(这种方法比较麻烦), 更简单的方法是直接对感兴趣的东西右键审查元素, 可以直接查看网站源码</li>
</ul>
<p>在查看网站源码后, 网站信息在第二个<ul>内</p>
<div class="jb51code">
<div class="code" style="position:relative; padding:0px; margin:0px;"><pre class="brush:py;">
<ul class="directory-url" style="margin-left:0;">
<li><a href="http://www.pearsonhighered.com/educator/academic/product/0,,0130260363,00%2Ben-USS_01DBC.html" class="listinglink">Core Python Programming</a>
- By Wesley J. Chun; Prentice Hall PTR, 2001, ISBN 0130260363. For experienced developers to improve extant skills; professional level examples. Starts by introducing syntax, objects, error handling, functions, classes, built-ins. [Prentice Hall]
<div class="flag"><a href="/public/flag?cat=Computers%2FProgramming%2FLanguages%2FPython%2FBooks&url=http%3A%2F%2Fwww.pearsonhighered.com%2Feducator%2Facademic%2Fproduct%2F0%2C%2C0130260363%2C00%252Ben-USS_01DBC.html"><img src="/img/flag.png" alt="[!]" title="report an issue with this listing"></a></div>
</li>
...省略部分...
</ul>
</pre><div class="contentsignin">登录后复制</div></div>
</p>
<p>那么就可以通过一下方式进行提取数据</p>
<div class="jb51code">
<div class="code" style="position:relative; padding:0px; margin:0px;"><pre class="brush:py;">
#通过如下命令选择每个在网站中的 <li> 元素:
sel.xpath('//ul/li')
#网站描述:
sel.xpath('//ul/li/text()').extract()
#网站标题:
sel.xpath('//ul/li/a/text()').extract()
#网站链接:
sel.xpath('//ul/li/a/@href').extract()
</pre><div class="contentsignin">登录后复制</div></div>
</p>
<p>如前所述,每个 xpath() 调用返回一个 selectors 列表,所以我们可以结合 xpath() 去挖掘更深的节点。我们将会用到这些特性,所以:</p>
<div class="jb51code">
<div class="code" style="position:relative; padding:0px; margin:0px;"><pre class="brush:py;">
for sel in response.xpath('//ul/li')
title = sel.xpath('a/text()').extract()
link = sel.xpath('a/@href').extract()
desc = sel.xpath('text()').extract()
print title, link, desc
</pre><div class="contentsignin">登录后复制</div></div>
</p>
<p>在已有的爬虫文件中修改代码</p>
<div class="jb51code">
<div class="code" style="position:relative; padding:0px; margin:0px;"><pre class="brush:py;">
import scrapy
class DmozSpider(scrapy.Spider):
name = "dmoz"
allowed_domains = ["dmoz.org"]
start_urls = [
"http://www.dmoz.org/Computers/Programming/Languages/Python/Books/",
"http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/"
]
def parse(self, response):
for sel in response.xpath('//ul/li'):
title = sel.xpath('a/text()').extract()
link = sel.xpath('a/@href').extract()
desc = sel.xpath('text()').extract()
print title, link, desc
</pre><div class="contentsignin">登录后复制</div></div>
</p>
<p><strong>3.4.3. 使用item<br />
</strong>Item对象是自定义的python字典,可以使用标准的字典语法来获取到其每个字段的值(字段即是我们之前用Field赋值的属性)</p>
<div class="jb51code">
<div class="code" style="position:relative; padding:0px; margin:0px;"><pre class="brush:py;">
>>> item = DmozItem()
>>> item['title'] = 'Example title'
>>> item['title']
'Example title'
</pre><div class="contentsignin">登录后复制</div></div>
</p>
<p>一般来说,Spider将会将爬取到的数据以 Item 对象返回, 最后修改爬虫类,使用 Item 来保存数据,代码如下</p>
<div class="jb51code">
<div class="code" style="position:relative; padding:0px; margin:0px;"><pre class="brush:py;">
from scrapy.spider import Spider
from scrapy.selector import Selector
from tutorial.items import DmozItem
class DmozSpider(Spider):
name = "dmoz"
allowed_domains = ["dmoz.org"]
start_urls = [
"http://www.dmoz.org/Computers/Programming/Languages/Python/Books/",
"http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/",
]
def parse(self, response):
sel = Selector(response)
sites = sel.xpath('//ul[@class="directory-url"]/li')
items = []
for site in sites:
item = DmozItem()
item['name'] = site.xpath('a/text()').extract()
item['url'] = site.xpath('a/@href').extract()
item['description'] = site.xpath('text()').re('-\s[^\n]*\\r')
items.append(item)
return items
</pre><div class="contentsignin">登录后复制</div></div>
</p>
<p><strong>3.5. 使用Item Pipeline<br />
</strong>当Item在Spider中被收集之后,它将会被传递到Item Pipeline,一些组件会按照一定的顺序执行对Item的处理。<br />
每个item pipeline组件(有时称之为ItemPipeline)是实现了简单方法的Python类。他们接收到Item并通过它执行一些行为,同时也决定此Item是否继续通过pipeline,或是被丢弃而不再进行处理。<br />
以下是item pipeline的一些典型应用:</p>
<ul>
<li>清理HTML数据</li>
<li>验证爬取的数据(检查item包含某些字段)</li>
<li>查重(并丢弃)</li>
<li>将爬取结果保存,如保存到数据库、XML、JSON等文件中</li>
</ul>
<p>编写你自己的item pipeline很简单,每个item pipeline组件是一个独立的Python类,同时必须实现以下方法:</p>
<p>(1)process_item(item, spider) #每个item pipeline组件都需要调用该方法,这个方法必须返回一个 Item (或任何继承类)对象,或是抛出 DropItem异常,被丢弃的item将不会被之后的pipeline组件所处理。</p>
<p>#参数:</p>
<p>item: 由 parse 方法返回的 Item 对象(Item对象)</p>
<p>spider: 抓取到这个 Item 对象对应的爬虫对象(Spider对象)</p>
<p>(2)open_spider(spider) #当spider被开启时,这个方法被调用。</p>
<p>#参数:</p>
<p>spider : (Spider object) – 被开启的spider</p>
<p>(3)close_spider(spider) #当spider被关闭时,这个方法被调用,可以再爬虫关闭后进行相应的数据处理。</p>
<p>#参数:</p>
<p>spider : (Spider object) – 被关闭的spider</p>
<p>为JSON文件编写一个items</p>
<div class="jb51code">
<div class="code" style="position:relative; padding:0px; margin:0px;"><pre class="brush:py;">
from scrapy.exceptions import DropItem
class TutorialPipeline(object):
# put all words in lowercase
words_to_filter = ['politics', 'religion']
def process_item(self, item, spider):
for word in self.words_to_filter:
if word in unicode(item['description']).lower():
raise DropItem("Contains forbidden word: %s" % word)
else:
return item
</pre><div class="contentsignin">登录后复制</div></div>
</p>
<p>在 settings.py 中设置ITEM_PIPELINES激活item pipeline,其默认为[]</p>
<div class="jb51code">
<div class="code" style="position:relative; padding:0px; margin:0px;"><pre class="brush:py;">
ITEM_PIPELINES = {'tutorial.pipelines.FilterWordsPipeline': 1}
</pre><div class="contentsignin">登录后复制</div></div>
</p>
<p><strong>3.6. 存储数据<br />
</strong>使用下面的命令存储为json文件格式</p>
<p>scrapy crawl dmoz -o items.json</p>
<p><strong>4.示例<br />
4.1最简单的spider(默认的Spider)<br />
</strong>用实例属性start_urls中的URL构造Request对象<br />
框架负责执行request<br />
将request返回的response对象传递给parse方法做分析</p>
<p>简化后的源码:</p>
<div class="jb51code">
<div class="code" style="position:relative; padding:0px; margin:0px;"><pre class="brush:py;">
class Spider(object_ref):
"""Base class for scrapy spiders. All spiders must inherit from this
class.
"""
name = None
def __init__(self, name=None, **kwargs):
if name is not None:
self.name = name
elif not getattr(self, 'name', None):
raise ValueError("%s must have a name" % type(self).__name__)
self.__dict__.update(kwargs)
if not hasattr(self, 'start_urls'):
self.start_urls = []
def start_requests(self):
for url in self.start_urls:
yield self.make_requests_from_url(url)
def make_requests_from_url(self, url):
return Request(url, dont_filter=True)
def parse(self, response):
raise NotImplementedError
BaseSpider = create_deprecated_class('BaseSpider', Spider)
</pre><div class="contentsignin">登录后复制</div></div>
</p>
<p>一个回调函数返回多个request的例子</p>
<div class="jb51code">
<div class="code" style="position:relative; padding:0px; margin:0px;"><pre class="brush:py;">
import scrapyfrom myproject.items import MyItemclass MySpider(scrapy.Spider):
name = 'example.com'
allowed_domains = ['example.com']
start_urls = [
'http://www.example.com/1.html',
'http://www.example.com/2.html',
'http://www.example.com/3.html',
]
def parse(self, response):
sel = scrapy.Selector(response)
for h3 in response.xpath('//h3').extract():
yield MyItem(title=h3)
for url in response.xpath('//a/@href').extract():
yield scrapy.Request(url, callback=self.parse)
</pre><div class="contentsignin">登录后复制</div></div>
</p>
<p>构造一个Request对象只需两个参数: URL和回调函数</p>
<p><strong>4.2CrawlSpider<br />
</strong>通常我们需要在spider中决定:哪些网页上的链接需要跟进, 哪些网页到此为止,无需跟进里面的链接。CrawlSpider为我们提供了有用的抽象——Rule,使这类爬取任务变得简单。你只需在rule中告诉scrapy,哪些是需要跟进的。<br />
回忆一下我们爬行mininova网站的spider.</p>
<div class="jb51code">
<div class="code" style="position:relative; padding:0px; margin:0px;"><pre class="brush:py;">
class MininovaSpider(CrawlSpider):
name = 'mininova'
allowed_domains = ['mininova.org']
start_urls = ['http://www.mininova.org/yesterday']
rules = [Rule(LinkExtractor(allow=['/tor/\d+']), 'parse_torrent')]
def parse_torrent(self, response):
torrent = TorrentItem()
torrent['url'] = response.url
torrent['name'] = response.xpath("//h1/text()").extract()
torrent['description'] = response.xpath("//div[@id='description']").extract()
torrent['size'] = response.xpath("//div[@id='specifications']/p[2]/text()[2]").extract()
return torrent
</pre><div class="contentsignin">登录后复制</div></div>
</p>
<p>上面代码中 rules的含义是:匹配/tor/\d+的URL返回的内容,交给parse_torrent处理,并且不再跟进response上的URL。<br />
官方文档中也有个例子:</p>
<div class="jb51code">
<div class="code" style="position:relative; padding:0px; margin:0px;"><pre class="brush:py;">
rules = (
# 提取匹配 'category.php' (但不匹配 'subsection.php') 的链接并跟进链接(没有callback意味着follow默认为True)
Rule(LinkExtractor(allow=('category\.php', ), deny=('subsection\.php', ))),
# 提取匹配 'item.php' 的链接并使用spider的parse_item方法进行分析
Rule(LinkExtractor(allow=('item\.php', )), callback='parse_item'),
)
</pre><div class="contentsignin">登录后复制</div></div>
<p>除了Spider和CrawlSpider外,还有XMLFeedSpider, CSVFeedSpider, SitemapSpider</p>
<p></p>
</div> </div>
</div>
<div style="height: 25px;">
<div class="wzconBq" style="display: inline-flex;">
<span>相关标签:</span>
<div class="wzcbqd">
<a onclick="hits_log(2,'www',this);" href-data="//m.sbmmt.com/zh/search?word=python" target="_blank">python</a> <a onclick="hits_log(2,'www',this);" href-data="//m.sbmmt.com/zh/search?word=scrapy" target="_blank">scrapy</a> <a onclick="hits_log(2,'www',this);" href-data="//m.sbmmt.com/zh/search?word=爬虫" target="_blank">爬虫</a> </div>
</div>
<div style="display: inline-flex;float: right; color:#333333;">来源:php.cn</div>
</div>
<div class="wzconOtherwz">
<a href="//m.sbmmt.com/zh/faq/312655.html" title="Ruby元编程基础学习笔记整理">
<span>上一篇:Ruby元编程基础学习笔记整理</span>
</a>
<a href="//m.sbmmt.com/zh/faq/312657.html" title="搭建Python的Django框架环境并建立和运行第一个App的教程">
<span>下一篇:搭建Python的Django框架环境并建立和运行第一个App的教程</span>
</a>
</div>
<div class="wzconShengming">
<div class="bzsmdiv">本站声明</div>
<div>本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系admin@php.cn</div>
</div>
<ins class="adsbygoogle"
style="display:block"
data-ad-format="autorelaxed"
data-ad-client="ca-pub-5902227090019525"
data-ad-slot="2507867629"></ins>
<script>
(adsbygoogle = window.adsbygoogle || []).push({});
</script>
<div class="wzconZzwz">
<div class="wzconZzwztitle">作者最新文章</div>
<ul>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots"></span>
<a target="_blank" href="//m.sbmmt.com/zh/faq/1796639331.html">什么是 NullPointerException,如何修复它?</a>
</div>
<div>2024-10-22 09:46:29</div>
</li>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots"></span>
<a target="_blank" href="//m.sbmmt.com/zh/faq/1796629482.html">从新手到程序员:您的旅程从 C 基础知识开始</a>
</div>
<div>2024-10-13 13:53:41</div>
</li>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots"></span>
<a target="_blank" href="//m.sbmmt.com/zh/faq/1796628545.html">使用PHP解锁网络开发:初学者指南</a>
</div>
<div>2024-10-12 12:15:51</div>
</li>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots"></span>
<a target="_blank" href="//m.sbmmt.com/zh/faq/1796627928.html">揭秘 C:为新程序员提供一条清晰简单的道路</a>
</div>
<div>2024-10-11 22:47:31</div>
</li>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots"></span>
<a target="_blank" href="//m.sbmmt.com/zh/faq/1796627806.html">释放您的编码潜力:绝对初学者的 C 编程</a>
</div>
<div>2024-10-11 19:36:51</div>
</li>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots"></span>
<a target="_blank" href="//m.sbmmt.com/zh/faq/1796627670.html">释放你内心的程序员:C 绝对初学者</a>
</div>
<div>2024-10-11 15:50:41</div>
</li>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots"></span>
<a target="_blank" href="//m.sbmmt.com/zh/faq/1796627643.html">使用 C 自动化您的生活:适合初学者的脚本和工具</a>
</div>
<div>2024-10-11 15:07:41</div>
</li>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots"></span>
<a target="_blank" href="//m.sbmmt.com/zh/faq/1796627620.html">PHP 变得简单:Web 开发的第一步</a>
</div>
<div>2024-10-11 14:21:21</div>
</li>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots"></span>
<a target="_blank" href="//m.sbmmt.com/zh/faq/1796627574.html">使用 Python 构建任何东西:释放创造力的初学者指南</a>
</div>
<div>2024-10-11 12:59:11</div>
</li>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots"></span>
<a target="_blank" href="//m.sbmmt.com/zh/faq/1796627539.html">编码的关键:为初学者释放 Python 的力量</a>
</div>
<div>2024-10-11 12:17:31</div>
</li>
</ul>
</div>
<div class="wzconZzwz">
<div class="wzconZzwztitle">最新问题</div>
<div class="wdsyContent">
<div class="wdsyConDiv flexRow wdsyConDiv1">
<div class="wdcdContent flexColumn">
<a href="//m.sbmmt.com/zh/wenda/176206.html" target="_blank" title="Python/MySQL无法正确持久化整数数据" class="wdcdcTitle">Python/MySQL无法正确持久化整数数据</a>
<a href="//m.sbmmt.com/zh/wenda/176206.html" class="wdcdcCons">在这里不需要任何代码。我想要保存一个非常长的数字,因为我正在制作一个游戏,需要保存分数。但是我测试了一下,将分数设置为25000000000,但在mysql中保存为21474836...</a>
<div class="wdcdcInfo flexRow">
<div class="wdcdcileft">
<span class="wdcdciSpan"> 来自于 2024-04-04 19:09:44</span>
</div>
<div class="wdcdciright flexRow">
<div class="wdcdcirdz flexRow ira"> <b class="wdcdcirdzi"></b>0 </div>
<div class="wdcdcirpl flexRow ira"><b class="wdcdcirpli"></b>1</div>
<div class="wdcdcirwatch flexRow ira"><b class="wdcdcirwatchi"></b>367</div>
</div>
</div>
</div>
</div>
<div class="wdsyConLine wdsyConLine2"></div>
<div class="wdsyConDiv flexRow wdsyConDiv1">
<div class="wdcdContent flexColumn">
<a href="//m.sbmmt.com/zh/wenda/176165.html" target="_blank" title="使用selenium想要点击并在类中定义URL" class="wdcdcTitle">使用selenium想要点击并在类中定义URL</a>
<a href="//m.sbmmt.com/zh/wenda/176165.html" class="wdcdcCons">今天我需要另一个提示。我正在尝试构建Python/Selenium代码,想法是单击www.thewebsiteIwantoclickon下面是我正在处理的HTML示例。类entit...</a>
<div class="wdcdcInfo flexRow">
<div class="wdcdcileft">
<span class="wdcdciSpan"> 来自于 2024-04-04 14:14:44</span>
</div>
<div class="wdcdciright flexRow">
<div class="wdcdcirdz flexRow ira"> <b class="wdcdcirdzi"></b>0 </div>
<div class="wdcdcirpl flexRow ira"><b class="wdcdcirpli"></b>1</div>
<div class="wdcdcirwatch flexRow ira"><b class="wdcdcirwatchi"></b>3492</div>
</div>
</div>
</div>
</div>
<div class="wdsyConLine wdsyConLine2"></div>
<div class="wdsyConDiv flexRow wdsyConDiv1">
<div class="wdcdContent flexColumn">
<a href="//m.sbmmt.com/zh/wenda/176001.html" target="_blank" title="Selenium + Python - 通过execute_script检查图像" class="wdcdcTitle">Selenium + Python - 通过execute_script检查图像</a>
<a href="//m.sbmmt.com/zh/wenda/176001.html" class="wdcdcCons">我需要使用python中的selenium验证图像是否显示在页面上。例如,让我们检查https://openweathermap.org/页面左上角的徽标。我使用execute_s...</a>
<div class="wdcdcInfo flexRow">
<div class="wdcdcileft">
<span class="wdcdciSpan"> 来自于 2024-04-03 09:32:15</span>
</div>
<div class="wdcdciright flexRow">
<div class="wdcdcirdz flexRow ira"> <b class="wdcdcirdzi"></b>0 </div>
<div class="wdcdcirpl flexRow ira"><b class="wdcdcirpli"></b>1</div>
<div class="wdcdcirwatch flexRow ira"><b class="wdcdcirwatchi"></b>375</div>
</div>
</div>
</div>
</div>
<div class="wdsyConLine wdsyConLine2"></div>
<div class="wdsyConDiv flexRow wdsyConDiv1">
<div class="wdcdContent flexColumn">
<a href="//m.sbmmt.com/zh/wenda/175819.html" target="_blank" title="保留前X行,删除表格行的方法" class="wdcdcTitle">保留前X行,删除表格行的方法</a>
<a href="//m.sbmmt.com/zh/wenda/175819.html" class="wdcdcCons">我在MySQLincident_archive中有一个包含数百万条记录的大表,我想按created列对行进行排序,并保留前X行并删除其余行,最有效的方法是什么。到目前为止,我用Py...</a>
<div class="wdcdcInfo flexRow">
<div class="wdcdcileft">
<span class="wdcdciSpan"> 来自于 2024-04-01 18:32:54</span>
</div>
<div class="wdcdciright flexRow">
<div class="wdcdcirdz flexRow ira"> <b class="wdcdcirdzi"></b>0 </div>
<div class="wdcdcirpl flexRow ira"><b class="wdcdcirpli"></b>1</div>
<div class="wdcdcirwatch flexRow ira"><b class="wdcdcirwatchi"></b>347</div>
</div>
</div>
</div>
</div>
<div class="wdsyConLine wdsyConLine2"></div>
<div class="wdsyConDiv flexRow wdsyConDiv1">
<div class="wdcdContent flexColumn">
<a href="//m.sbmmt.com/zh/wenda/175783.html" target="_blank" title="如何使用 BeautifulSoup 抓取特定的谷歌天气文本?" class="wdcdcTitle">如何使用 BeautifulSoup 抓取特定的谷歌天气文本?</a>
<a href="//m.sbmmt.com/zh/wenda/175783.html" class="wdcdcCons">如何使用BeautifulSoup在Python中找到课程文本“美国纽约市”?尝试复制视频进行练习,但不再有效。尝试在官方文档中找到一些内容,但没有成功。或者我的get_html_...</a>
<div class="wdcdcInfo flexRow">
<div class="wdcdcileft">
<span class="wdcdciSpan"> 来自于 2024-04-01 14:06:14</span>
</div>
<div class="wdcdciright flexRow">
<div class="wdcdcirdz flexRow ira"> <b class="wdcdcirdzi"></b>0 </div>
<div class="wdcdcirpl flexRow ira"><b class="wdcdcirpli"></b>1</div>
<div class="wdcdcirwatch flexRow ira"><b class="wdcdcirwatchi"></b>308</div>
</div>
</div>
</div>
</div>
<div class="wdsyConLine wdsyConLine2"></div>
</div>
</div>
<div class="wzconZt" >
<div class="wzczt-title">
<div>相关专题</div>
<a href="//m.sbmmt.com/zh/faq/zt" target="_blank">更多>
</a>
</div>
<div class="wzcttlist">
<ul>
<li class="ul-li">
<a target="_blank" href="//m.sbmmt.com/zh/faq/pythonkfgj"><img src="https://img.php.cn/upload/subject/202407/22/2024072214424826783.jpg?x-oss-process=image/resize,m_fill,h_145,w_220" alt="python开发工具" /> </a>
<a target="_blank" href="//m.sbmmt.com/zh/faq/pythonkfgj" class="title-a-spanl" title="python开发工具"><span>python开发工具</span> </a>
</li>
<li class="ul-li">
<a target="_blank" href="//m.sbmmt.com/zh/faq/pythondb"><img src="https://img.php.cn/upload/subject/202407/22/2024072214312147925.jpg?x-oss-process=image/resize,m_fill,h_145,w_220" alt="python打包成可执行文件" /> </a>
<a target="_blank" href="//m.sbmmt.com/zh/faq/pythondb" class="title-a-spanl" title="python打包成可执行文件"><span>python打包成可执行文件</span> </a>
</li>
<li class="ul-li">
<a target="_blank" href="//m.sbmmt.com/zh/faq/pythonnzsm"><img src="https://img.php.cn/upload/subject/202407/22/2024072214301218201.jpg?x-oss-process=image/resize,m_fill,h_145,w_220" alt="python能做什么" /> </a>
<a target="_blank" href="//m.sbmmt.com/zh/faq/pythonnzsm" class="title-a-spanl" title="python能做什么"><span>python能做什么</span> </a>
</li>
<li class="ul-li">
<a target="_blank" href="//m.sbmmt.com/zh/faq/formatzpython"><img src="https://img.php.cn/upload/subject/202407/22/2024072214275096159.jpg?x-oss-process=image/resize,m_fill,h_145,w_220" alt="format在python中的用法" /> </a>
<a target="_blank" href="//m.sbmmt.com/zh/faq/formatzpython" class="title-a-spanl" title="format在python中的用法"><span>format在python中的用法</span> </a>
</li>
<li class="ul-li">
<a target="_blank" href="//m.sbmmt.com/zh/faq/pythonjc"><img src="https://img.php.cn/upload/subject/202407/22/2024072214254329480.jpg?x-oss-process=image/resize,m_fill,h_145,w_220" alt="python教程" /> </a>
<a target="_blank" href="//m.sbmmt.com/zh/faq/pythonjc" class="title-a-spanl" title="python教程"><span>python教程</span> </a>
</li>
<li class="ul-li">
<a target="_blank" href="//m.sbmmt.com/zh/faq/pythonhjblbz"><img src="https://img.php.cn/upload/subject/202407/22/2024072214252616529.jpg?x-oss-process=image/resize,m_fill,h_145,w_220" alt="python环境变量的配置" /> </a>
<a target="_blank" href="//m.sbmmt.com/zh/faq/pythonhjblbz" class="title-a-spanl" title="python环境变量的配置"><span>python环境变量的配置</span> </a>
</li>
<li class="ul-li">
<a target="_blank" href="//m.sbmmt.com/zh/faq/pythoneval"><img src="https://img.php.cn/upload/subject/202407/22/2024072214251549631.jpg?x-oss-process=image/resize,m_fill,h_145,w_220" alt="蟒蛇评估" /> </a>
<a target="_blank" href="//m.sbmmt.com/zh/faq/pythoneval" class="title-a-spanl" title="蟒蛇评估"><span>蟒蛇评估</span> </a>
</li>
<li class="ul-li">
<a target="_blank" href="//m.sbmmt.com/zh/faq/scratchpyt"><img src="https://img.php.cn/upload/subject/202407/22/2024072214235344903.jpg?x-oss-process=image/resize,m_fill,h_145,w_220" alt="scratch和python区别" /> </a>
<a target="_blank" href="//m.sbmmt.com/zh/faq/scratchpyt" class="title-a-spanl" title="scratch和python区别"><span>scratch和python区别</span> </a>
</li>
</ul>
</div>
</div>
</div>
</div>
<div class="phpwzright">
<ins class="adsbygoogle"
style="display:block"
data-ad-client="ca-pub-5902227090019525"
data-ad-slot="3653428331"
data-ad-format="auto"
data-full-width-responsive="true"></ins>
<script>
(adsbygoogle = window.adsbygoogle || []).push({});
</script>
<div class="wzrOne">
<div class="wzroTitle">热门推荐</div>
<div class="wzroList">
<ul>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots wzrolr"></span>
<a style="height: auto;" title="python中eval是什么意思?" href="//m.sbmmt.com/zh/faq/419793.html">python中eval是什么意思?</a>
</div>
</li>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots wzrolr"></span>
<a style="height: auto;" title="python如何读取txt文件内容" href="//m.sbmmt.com/zh/faq/479676.html">python如何读取txt文件内容</a>
</div>
</li>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots wzrolr"></span>
<a style="height: auto;" title="py文件怎么打开?" href="//m.sbmmt.com/zh/faq/418747.html">py文件怎么打开?</a>
</div>
</li>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots wzrolr"></span>
<a style="height: auto;" title="python中str是什么意思" href="//m.sbmmt.com/zh/faq/419809.html">python中str是什么意思</a>
</div>
</li>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots wzrolr"></span>
<a style="height: auto;" title="python中format怎么用" href="//m.sbmmt.com/zh/faq/471817.html">python中format怎么用</a>
</div>
</li>
</ul>
</div>
</div>
<script src="https://sw.php.cn/hezuo/cac1399ab368127f9b113b14eb3316d0.js" type="text/javascript"></script>
<div class="wzrThree">
<div class="wzrthree-title">
<div>热门教程</div>
<a target="_blank" href="//m.sbmmt.com/zh/course.html">更多>
</a>
</div>
<div class="wzrthreelist swiper2">
<div class="wzrthreeTab swiper-wrapper">
<div class="check tabdiv swiper-slide" data-id="one">相关教程 <div></div></div>
<div class="tabdiv swiper-slide" data-id="two">热门推荐<div></div></div>
<div class="tabdiv swiper-slide" data-id="three">最新课程<div></div></div>
</div>
<ul class="one">
<li>
<a target="_blank" href="//m.sbmmt.com/zh/course/812.html" title="最新ThinkPHP 5.1全球首发视频教程(60天成就PHP大牛线上培训班课)" class="wzrthreelaimg">
<img src="https://img.php.cn/upload/course/000/000/041/620debc3eab3f377.jpg" alt="最新ThinkPHP 5.1全球首发视频教程(60天成就PHP大牛线上培训班课)"/>
</a>
<div class="wzrthree-right">
<a target="_blank" title="最新ThinkPHP 5.1全球首发视频教程(60天成就PHP大牛线上培训班课)" href="//m.sbmmt.com/zh/course/812.html">最新ThinkPHP 5.1全球首发视频教程(60天成就PHP大牛线上培训班课)</a>
<div class="wzrthreerb">
<div>1425013 <b class="kclbcollectb"></b></div>
<div class="courseICollection" data-id="812">
<b class="nofollow small-nocollect"></b>
</div>
</div>
</div>
</li>
<li>
<a target="_blank" href="//m.sbmmt.com/zh/course/74.html" title="php入门教程之一周学会PHP" class="wzrthreelaimg">
<img src="https://img.php.cn/upload/course/000/000/068/6253d1e28ef5c345.png" alt="php入门教程之一周学会PHP"/>
</a>
<div class="wzrthree-right">
<a target="_blank" title="php入门教程之一周学会PHP" href="//m.sbmmt.com/zh/course/74.html">php入门教程之一周学会PHP</a>
<div class="wzrthreerb">
<div>4271257 <b class="kclbcollectb"></b></div>
<div class="courseICollection" data-id="74">
<b class="nofollow small-nocollect"></b>
</div>
</div>
</div>
</li>
<li>
<a target="_blank" href="//m.sbmmt.com/zh/course/286.html" title="JAVA 初级入门视频教程" class="wzrthreelaimg">
<img src="https://img.php.cn/upload/course/000/000/068/62590a2bacfd9379.png" alt="JAVA 初级入门视频教程"/>
</a>
<div class="wzrthree-right">
<a target="_blank" title="JAVA 初级入门视频教程" href="//m.sbmmt.com/zh/course/286.html">JAVA 初级入门视频教程</a>
<div class="wzrthreerb">
<div>2551729 <b class="kclbcollectb"></b></div>
<div class="courseICollection" data-id="286">
<b class="nofollow small-nocollect"></b>
</div>
</div>
</div>
</li>
<li>
<a target="_blank" href="//m.sbmmt.com/zh/course/504.html" title="小甲鱼零基础入门学习Python视频教程" class="wzrthreelaimg">
<img src="https://img.php.cn/upload/course/000/000/068/62590a67ce3a6655.png" alt="小甲鱼零基础入门学习Python视频教程"/>
</a>
<div class="wzrthree-right">
<a target="_blank" title="小甲鱼零基础入门学习Python视频教程" href="//m.sbmmt.com/zh/course/504.html">小甲鱼零基础入门学习Python视频教程</a>
<div class="wzrthreerb">
<div>508446 <b class="kclbcollectb"></b></div>
<div class="courseICollection" data-id="504">
<b class="nofollow small-nocollect"></b>
</div>
</div>
</div>
</li>
<li>
<a target="_blank" href="//m.sbmmt.com/zh/course/2.html" title="PHP 零基础入门教程" class="wzrthreelaimg">
<img src="https://img.php.cn/upload/course/000/000/068/6253de27bc161468.png" alt="PHP 零基础入门教程"/>
</a>
<div class="wzrthree-right">
<a target="_blank" title="PHP 零基础入门教程" href="//m.sbmmt.com/zh/course/2.html">PHP 零基础入门教程</a>
<div class="wzrthreerb">
<div>863983 <b class="kclbcollectb"></b></div>
<div class="courseICollection" data-id="2">
<b class="nofollow small-nocollect"></b>
</div>
</div>
</div>
</li>
</ul>
<ul class="two" style="display: none;">
<li>
<a target="_blank" href="//m.sbmmt.com/zh/course/812.html" title="最新ThinkPHP 5.1全球首发视频教程(60天成就PHP大牛线上培训班课)" class="wzrthreelaimg">
<img src="https://img.php.cn/upload/course/000/000/041/620debc3eab3f377.jpg" alt="最新ThinkPHP 5.1全球首发视频教程(60天成就PHP大牛线上培训班课)"/>
</a>
<div class="wzrthree-right">
<a target="_blank" title="最新ThinkPHP 5.1全球首发视频教程(60天成就PHP大牛线上培训班课)" href="//m.sbmmt.com/zh/course/812.html">最新ThinkPHP 5.1全球首发视频教程(60天成就PHP大牛线上培训班课)</a>
<div class="wzrthreerb">
<div >1425013次学习</div>
<div class="courseICollection" data-id="812">
<b class="nofollow small-nocollect"></b>
</div>
</div>
</div>
</li>
<li>
<a target="_blank" href="//m.sbmmt.com/zh/course/286.html" title="JAVA 初级入门视频教程" class="wzrthreelaimg">
<img src="https://img.php.cn/upload/course/000/000/068/62590a2bacfd9379.png" alt="JAVA 初级入门视频教程"/>
</a>
<div class="wzrthree-right">
<a target="_blank" title="JAVA 初级入门视频教程" href="//m.sbmmt.com/zh/course/286.html">JAVA 初级入门视频教程</a>
<div class="wzrthreerb">
<div >2551729次学习</div>
<div class="courseICollection" data-id="286">
<b class="nofollow small-nocollect"></b>
</div>
</div>
</div>
</li>
<li>
<a target="_blank" href="//m.sbmmt.com/zh/course/504.html" title="小甲鱼零基础入门学习Python视频教程" class="wzrthreelaimg">
<img src="https://img.php.cn/upload/course/000/000/068/62590a67ce3a6655.png" alt="小甲鱼零基础入门学习Python视频教程"/>
</a>
<div class="wzrthree-right">
<a target="_blank" title="小甲鱼零基础入门学习Python视频教程" href="//m.sbmmt.com/zh/course/504.html">小甲鱼零基础入门学习Python视频教程</a>
<div class="wzrthreerb">
<div >508446次学习</div>
<div class="courseICollection" data-id="504">
<b class="nofollow small-nocollect"></b>
</div>
</div>
</div>
</li>
<li>
<a target="_blank" href="//m.sbmmt.com/zh/course/901.html" title="Web前端开发极速入门" class="wzrthreelaimg">
<img src="https://img.php.cn/upload/course/000/000/067/64be28a53a4f6310.png" alt="Web前端开发极速入门"/>
</a>
<div class="wzrthree-right">
<a target="_blank" title="Web前端开发极速入门" href="//m.sbmmt.com/zh/course/901.html">Web前端开发极速入门</a>
<div class="wzrthreerb">
<div >216020次学习</div>
<div class="courseICollection" data-id="901">
<b class="nofollow small-nocollect"></b>
</div>
</div>
</div>
</li>
<li>
<a target="_blank" href="//m.sbmmt.com/zh/course/234.html" title="零基础精通 PS 视频教程" class="wzrthreelaimg">
<img src="https://img.php.cn/upload/course/000/000/068/62611f57ed0d4840.jpg" alt="零基础精通 PS 视频教程"/>
</a>
<div class="wzrthree-right">
<a target="_blank" title="零基础精通 PS 视频教程" href="//m.sbmmt.com/zh/course/234.html">零基础精通 PS 视频教程</a>
<div class="wzrthreerb">
<div >893596次学习</div>
<div class="courseICollection" data-id="234">
<b class="nofollow small-nocollect"></b>
</div>
</div>
</div>
</li>
</ul>
<ul class="three" style="display: none;">
<li>
<a target="_blank" href="//m.sbmmt.com/zh/course/1648.html" title="【web前端】Node.js快速入门" class="wzrthreelaimg">
<img src="https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png" alt="【web前端】Node.js快速入门"/>
</a>
<div class="wzrthree-right">
<a target="_blank" title="【web前端】Node.js快速入门" href="//m.sbmmt.com/zh/course/1648.html">【web前端】Node.js快速入门</a>
<div class="wzrthreerb">
<div >7754次学习</div>
<div class="courseICollection" data-id="1648">
<b class="nofollow small-nocollect"></b>
</div>
</div>
</div>
</li>
<li>
<a target="_blank" href="//m.sbmmt.com/zh/course/1647.html" title="国外Web开发全栈课程全集" class="wzrthreelaimg">
<img src="https://img.php.cn/upload/course/000/000/067/6628cc96e310c937.png" alt="国外Web开发全栈课程全集"/>
</a>
<div class="wzrthree-right">
<a target="_blank" title="国外Web开发全栈课程全集" href="//m.sbmmt.com/zh/course/1647.html">国外Web开发全栈课程全集</a>
<div class="wzrthreerb">
<div >6195次学习</div>
<div class="courseICollection" data-id="1647">
<b class="nofollow small-nocollect"></b>
</div>
</div>
</div>
</li>
<li>
<a target="_blank" href="//m.sbmmt.com/zh/course/1646.html" title="Go语言实战之 GraphQL" class="wzrthreelaimg">
<img src="https://img.php.cn/upload/course/000/000/067/662221173504a436.png" alt="Go语言实战之 GraphQL"/>
</a>
<div class="wzrthree-right">
<a target="_blank" title="Go语言实战之 GraphQL" href="//m.sbmmt.com/zh/course/1646.html">Go语言实战之 GraphQL</a>
<div class="wzrthreerb">
<div >5106次学习</div>
<div class="courseICollection" data-id="1646">
<b class="nofollow small-nocollect"></b>
</div>
</div>
</div>
</li>
<li>
<a target="_blank" href="//m.sbmmt.com/zh/course/1645.html" title="550W粉丝大佬手把手从零学JavaScript" class="wzrthreelaimg">
<img src="https://img.php.cn/upload/course/000/000/067/662077e163124646.png" alt="550W粉丝大佬手把手从零学JavaScript"/>
</a>
<div class="wzrthree-right">
<a target="_blank" title="550W粉丝大佬手把手从零学JavaScript" href="//m.sbmmt.com/zh/course/1645.html">550W粉丝大佬手把手从零学JavaScript</a>
<div class="wzrthreerb">
<div >707次学习</div>
<div class="courseICollection" data-id="1645">
<b class="nofollow small-nocollect"></b>
</div>
</div>
</div>
</li>
<li>
<a target="_blank" href="//m.sbmmt.com/zh/course/1644.html" title="python大神Mosh,零基础小白6小时完全入门" class="wzrthreelaimg">
<img src="https://img.php.cn/upload/course/000/000/067/6616418ca80b8916.png" alt="python大神Mosh,零基础小白6小时完全入门"/>
</a>
<div class="wzrthree-right">
<a target="_blank" title="python大神Mosh,零基础小白6小时完全入门" href="//m.sbmmt.com/zh/course/1644.html">python大神Mosh,零基础小白6小时完全入门</a>
<div class="wzrthreerb">
<div >25860次学习</div>
<div class="courseICollection" data-id="1644">
<b class="nofollow small-nocollect"></b>
</div>
</div>
</div>
</li>
</ul>
</div>
<script>
var mySwiper = new Swiper('.swiper2', {
autoplay: false,//可选选项,自动滑动
slidesPerView : 'auto',
})
$('.wzrthreeTab>div').click(function(e){
$('.wzrthreeTab>div').removeClass('check')
$(this).addClass('check')
$('.wzrthreelist>ul').css('display','none')
$('.'+e.currentTarget.dataset.id).show()
})
</script>
</div>
<div class="wzrFour">
<div class="wzrfour-title">
<div>最新下载</div>
<a href="//m.sbmmt.com/zh/xiazai">更多>
</a>
</div>
<script>
$(document).ready(function(){
var sjyx_banSwiper = new Swiper(".sjyx_banSwiperwz",{
speed:1000,
autoplay:{
delay:3500,
disableOnInteraction: false,
},
pagination:{
el:'.sjyx_banSwiperwz .swiper-pagination',
clickable :false,
},
loop:true
})
})
</script>
<div class="wzrfourList swiper3">
<div class="wzrfourlTab swiper-wrapper">
<div class="check swiper-slide" data-id="onef">网站特效 <div></div></div>
<div class="swiper-slide" data-id="twof">网站源码<div></div></div>
<div class="swiper-slide" data-id="threef">网站素材<div></div></div>
<div class="swiper-slide" data-id="fourf">前端模板<div></div></div>
</div>
<ul class="onef">
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a target="_blank" title="jQuery企业留言表单联系代码" href="//m.sbmmt.com/zh/toolset/js-special-effects/8071">[表单按钮] jQuery企业留言表单联系代码</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a target="_blank" title="HTML5 MP3音乐盒播放特效" href="//m.sbmmt.com/zh/toolset/js-special-effects/8070">[播放器特效] HTML5 MP3音乐盒播放特效</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a target="_blank" title="HTML5炫酷粒子动画导航菜单特效" href="//m.sbmmt.com/zh/toolset/js-special-effects/8069">[菜单导航] HTML5炫酷粒子动画导航菜单特效</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a target="_blank" title="jQuery可视化表单拖拽编辑代码" href="//m.sbmmt.com/zh/toolset/js-special-effects/8068">[表单按钮] jQuery可视化表单拖拽编辑代码</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a target="_blank" title="VUE.JS仿酷狗音乐播放器代码" href="//m.sbmmt.com/zh/toolset/js-special-effects/8067">[播放器特效] VUE.JS仿酷狗音乐播放器代码</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a target="_blank" title="经典html5推箱子小游戏" href="//m.sbmmt.com/zh/toolset/js-special-effects/8066">[html5特效] 经典html5推箱子小游戏</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a target="_blank" title="jQuery滚动添加或减少图片特效" href="//m.sbmmt.com/zh/toolset/js-special-effects/8065">[图片特效] jQuery滚动添加或减少图片特效</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a target="_blank" title="CSS3个人相册封面悬停放大特效" href="//m.sbmmt.com/zh/toolset/js-special-effects/8064">[相册特效] CSS3个人相册封面悬停放大特效</a>
</div>
</li>
</ul>
<ul class="twof" style="display:none">
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/zh/toolset/website-source-code/8328" title="家居装潢清洁维修服务公司网站模板" target="_blank">[前端模板] 家居装潢清洁维修服务公司网站模板</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/zh/toolset/website-source-code/8327" title="清新配色个人求职简历引导页模板" target="_blank">[前端模板] 清新配色个人求职简历引导页模板</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/zh/toolset/website-source-code/8326" title="设计师创意求职简历网页模板" target="_blank">[前端模板] 设计师创意求职简历网页模板</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/zh/toolset/website-source-code/8325" title="现代工程建筑公司网站模板" target="_blank">[前端模板] 现代工程建筑公司网站模板</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/zh/toolset/website-source-code/8324" title="教育服务机构响应式HTML5模板" target="_blank">[前端模板] 教育服务机构响应式HTML5模板</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/zh/toolset/website-source-code/8323" title="网上电子书店商城网站模板" target="_blank">[前端模板] 网上电子书店商城网站模板</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/zh/toolset/website-source-code/8322" title="IT技术解决互联网公司网站模板" target="_blank">[前端模板] IT技术解决互联网公司网站模板</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/zh/toolset/website-source-code/8321" title="紫色风格外汇交易服务网站模板" target="_blank">[前端模板] 紫色风格外汇交易服务网站模板</a>
</div>
</li>
</ul>
<ul class="threef" style="display:none">
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/zh/toolset/website-materials/3078" target="_blank" title="可爱的夏天元素矢量素材(EPS+PNG)">[PNG素材] 可爱的夏天元素矢量素材(EPS+PNG)</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/zh/toolset/website-materials/3077" target="_blank" title="四个红的的 2023 毕业徽章矢量素材(AI+EPS+PNG)">[PNG素材] 四个红的的 2023 毕业徽章矢量素材(AI+EPS+PNG)</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/zh/toolset/website-materials/3076" target="_blank" title="唱歌的小鸟和装满花朵的推车设计春天banner矢量素材(AI+EPS)">[banner图] 唱歌的小鸟和装满花朵的推车设计春天banner矢量素材(AI+EPS)</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/zh/toolset/website-materials/3075" target="_blank" title="金色的毕业帽矢量素材(EPS+PNG)">[PNG素材] 金色的毕业帽矢量素材(EPS+PNG)</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/zh/toolset/website-materials/3074" target="_blank" title="黑白风格的山脉图标矢量素材(EPS+PNG)">[PNG素材] 黑白风格的山脉图标矢量素材(EPS+PNG)</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/zh/toolset/website-materials/3073" target="_blank" title="不同颜色披风和不同姿势的超级英雄剪影矢量素材(EPS+PNG)">[PNG素材] 不同颜色披风和不同姿势的超级英雄剪影矢量素材(EPS+PNG)</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/zh/toolset/website-materials/3072" target="_blank" title="扁平风格的植树节banner矢量素材(AI+EPS)">[banner图] 扁平风格的植树节banner矢量素材(AI+EPS)</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/zh/toolset/website-materials/3071" target="_blank" title="九个漫画风格的爆炸聊天气泡矢量素材(EPS+PNG)">[PNG素材] 九个漫画风格的爆炸聊天气泡矢量素材(EPS+PNG)</a>
</div>
</li>
</ul>
<ul class="fourf" style="display:none">
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/zh/toolset/website-source-code/8328" target="_blank" title="家居装潢清洁维修服务公司网站模板">[前端模板] 家居装潢清洁维修服务公司网站模板</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/zh/toolset/website-source-code/8327" target="_blank" title="清新配色个人求职简历引导页模板">[前端模板] 清新配色个人求职简历引导页模板</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/zh/toolset/website-source-code/8326" target="_blank" title="设计师创意求职简历网页模板">[前端模板] 设计师创意求职简历网页模板</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/zh/toolset/website-source-code/8325" target="_blank" title="现代工程建筑公司网站模板">[前端模板] 现代工程建筑公司网站模板</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/zh/toolset/website-source-code/8324" target="_blank" title="教育服务机构响应式HTML5模板">[前端模板] 教育服务机构响应式HTML5模板</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/zh/toolset/website-source-code/8323" target="_blank" title="网上电子书店商城网站模板">[前端模板] 网上电子书店商城网站模板</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/zh/toolset/website-source-code/8322" target="_blank" title="IT技术解决互联网公司网站模板">[前端模板] IT技术解决互联网公司网站模板</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/zh/toolset/website-source-code/8321" target="_blank" title="紫色风格外汇交易服务网站模板">[前端模板] 紫色风格外汇交易服务网站模板</a>
</div>
</li>
</ul>
</div>
<script>
var mySwiper = new Swiper('.swiper3', {
autoplay: false,//可选选项,自动滑动
slidesPerView : 'auto',
})
$('.wzrfourlTab>div').click(function(e){
$('.wzrfourlTab>div').removeClass('check')
$(this).addClass('check')
$('.wzrfourList>ul').css('display','none')
$('.'+e.currentTarget.dataset.id).show()
})
</script>
</div>
</div>
</div>
<footer>
<div class="footer">
<div class="footertop">
<img src="/static/imghw/logo.png" alt="">
<p>公益在线PHP培训,帮助PHP学习者快速成长!</p>
</div>
<div class="footermid">
<a href="//m.sbmmt.com/zh/about/us.html">关于我们</a>
<a href="//m.sbmmt.com/zh/about/disclaimer.html">免责声明</a>
<a href="//m.sbmmt.com/zh/update/article_0_1.html">Sitemap</a>
</div>
<div class="footerbottom">
<p>
© php.cn All rights reserved
</p>
</div>
</div>
</footer>
<input type="hidden" id="verifycode" value="/captcha.html">
<script>layui.use(['element', 'carousel'], function () {var element = layui.element;$ = layui.jquery;var carousel = layui.carousel;carousel.render({elem: '#test1', width: '100%', height: '330px', arrow: 'always'});$.getScript('/static/js/jquery.lazyload.min.js', function () {$("img").lazyload({placeholder: "/static/images/load.jpg", effect: "fadeIn", threshold: 200, skip_invisible: false});});});</script>
<script src="/static/js/common_new.js"></script>
<script type="text/javascript" src="/static/js/jquery.cookie.js?1735312701"></script>
<script src="https://vdse.bdstatic.com//search-video.v1.min.js"></script>
<link rel='stylesheet' id='_main-css' href='/static/css/viewer.min.css?2' type='text/css' media='all'/>
<script type='text/javascript' src='/static/js/viewer.min.js?1'></script>
<script type='text/javascript' src='/static/js/jquery-viewer.min.js'></script>
<script type="text/javascript" src="/static/js/global.min.js?5.5.53"></script>
<!-- Matomo -->
<script>
var _paq = window._paq = window._paq || [];
/* tracker methods like "setCustomDimension" should be called before "trackPageView" */
_paq.push(['trackPageView']);
_paq.push(['enableLinkTracking']);
(function() {
var u="https://tongji.php.cn/";
_paq.push(['setTrackerUrl', u+'matomo.php']);
_paq.push(['setSiteId', '9']);
var d=document, g=d.createElement('script'), s=d.getElementsByTagName('script')[0];
g.async=true; g.src=u+'matomo.js'; s.parentNode.insertBefore(g,s);
})();
</script>
<!-- End Matomo Code -->
</body>
</html>



