

上海交大、上海AI Lab和港中文大学的研究人员推出Visual-RFT(视觉强化微调)开源项目,该项目仅需少量数据即可显着提升视觉语言大模型(LVLM)性能。 Visual-RFT巧妙地将DeepSeek-R1的基于规则奖励的强化学习方法与OpenAI的强化微调(RFT)范式相结合,成功地将这一方法从文本领域扩展到视觉领域。

通过为视觉细分类、目标检测等任务设计相应的规则奖励,Visual-RFT克服了DeepSeek-R1方法仅限于文本、数学推理等领域的局限性,为LVLM训练提供了新的途径。

Visual-RFT的优势:
与传统的视觉指令微调(SFT)方法相比,Visual-RFT具有以下显着优势:
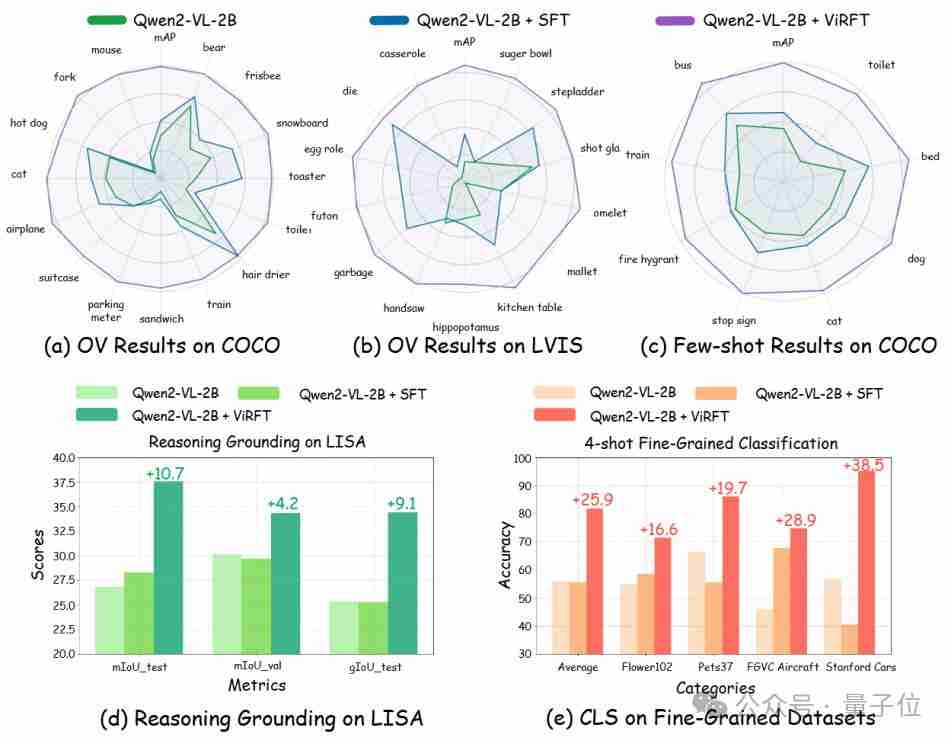
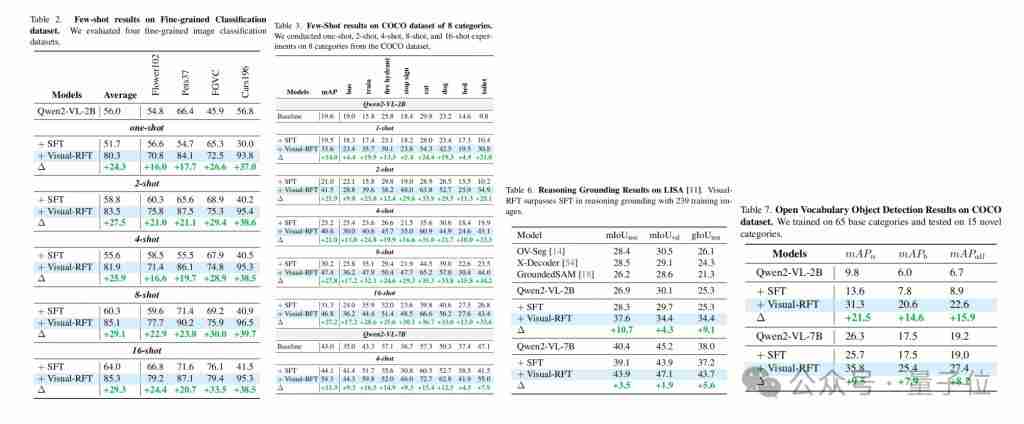
研究人员在多个视觉感知任务(检测、分类、定位等)上对Visual-RFT进行了验证,结果表明,即使在开放词汇和少样本学习的设定下,Visual-RFT也能取得显着的性能提升,轻松实现能力迁移。
研究人员针对不同的任务设计了相应的可验证奖励:基于IoU的奖励用于检测和定位任务,基于分类正确性的奖励用于分类任务。
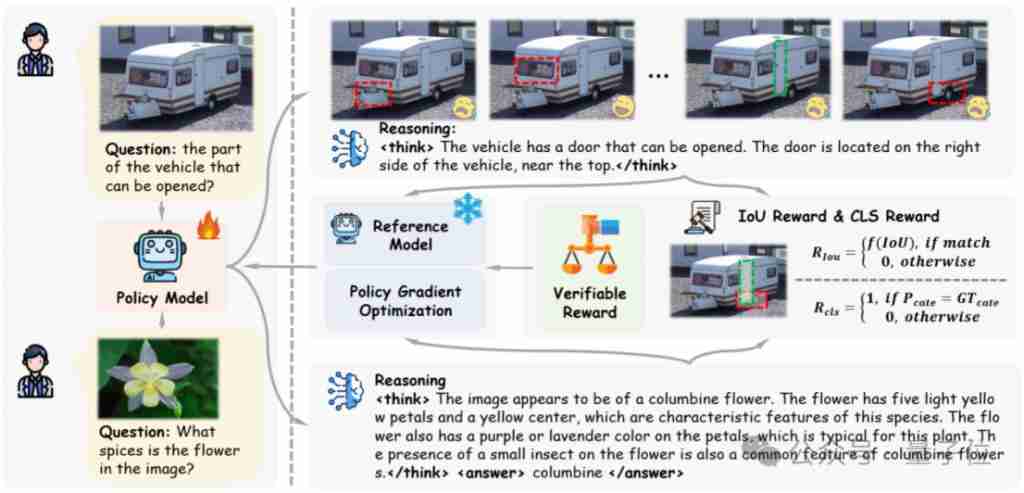
在推理定位任务中,Visual-RFT展现出强大的视觉推理能力,例如,准确识别图片中运动员需要佩戴的防水眼镜。


实验结果:
基于QWen2-VL 2B/7B模型进行的实验表明,Visual-RFT在开放目标检测、少样本检测、细粒度分类和推理定位任务上均优于SFT。 即使是检测特定动漫角色(例如史莱姆),Visual-RFT也只需少量数据即可实现。
开源信息:
Visual-RFT项目已开源,包含训练、评测代码和数据。
项目地址: //m.sbmmt.com/link/ec56522bc9c2e15be17d11962eeec453

以上是显着超越 SFT,o1/DeepSeek-R1 背后秘诀也能用于多模态大模型了的详细内容。更多信息请关注PHP中文网其他相关文章!





















