


批量、小批量和随机梯度下降

请我喝杯咖啡☕
*备忘录:
- 我的文章解释了 PyTorch 中使用 DataLoader() 进行批量、小批量和随机梯度下降。
- 我的文章解释了 PyTorch 中不使用 DataLoader() 的批量梯度下降。
- 我的文章解释了 PyTorch 中的优化器。
有批量梯度下降(BGD)、小批量梯度下降(MBGD)和随机梯度下降(SGD),它们是如何从数据集中获取数据使用梯度下降的方法优化器,例如 Adam()、SGD()、RMSprop()、Adadelta()、Adagrad() 等PyTorch。
*备忘录:
- PyTorch 中的 SGD() 只是基本的梯度下降,没有特殊功能(经典梯度下降(CGD)),而不是随机梯度下降(SGD)。
- 例如,使用下面这些方式,您可以灵活地使用 Adam() 执行 BGD、MBGD 或 SGD Adam,使用 SGD() 执行 CGD,使用 RMSprop() 执行 RMSprop,使用 Adadelta() 执行 Adadelta,使用 Adagrad() 执行 Adagrad, PyTorch 中的等。
- 基本上,BGD、MBGD 或 SGD 是通过 DataLoader() 对数据集进行混洗来完成的:
*备注:
- 改组数据集可以缓解过度拟合。 *基本上,只有训练数据被打乱,因此测试数据不会被打乱。
- 我的帖子解释了过度拟合和欠拟合。
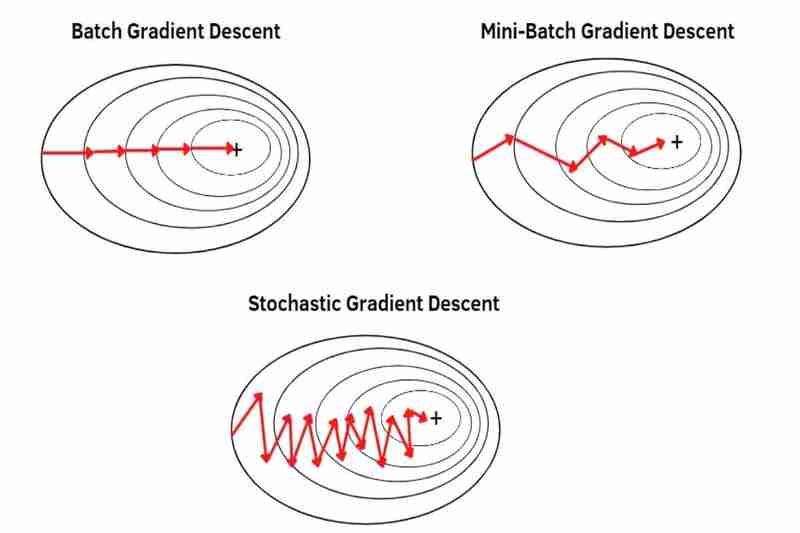
(1) 批量梯度下降(BGD):
- 可以对整个数据集进行梯度下降,在一个时期内只采取一步。例如,整个数据集有 100 个样本(1x100),那么梯度下降在一个 epoch 中只发生一次,这意味着模型的参数在一个 epoch 中只更新一次。
- 使用整个数据集的平均值,因此每个样本不如 MBGD 和 SGD 那么突出(不太强调)。因此,收敛比 MBGD 和 SGD 更稳定(波动更小),并且比 MBGD 和 SGD 的噪声(噪声数据)更强,导致比 MBGD 和 SGD 更少的超调,并且创建比 MBGD 和 SGD 更准确的模型,如果没有陷入局部最小值,但 BGD 比 MBGD 和 SGD 更不容易逃脱局部最小值或鞍点,因为正如我之前所说,收敛比 MBGD 和 SGD 更稳定(波动更小)正如我之前所说,BGD 比 MBGD 和 SGD 更容易导致过拟合,因为每个样本都比 MBGD 和 SGD 不那么突出(不太强调)。
*备注:
- 收敛表示初始权重通过梯度下降向函数的全局最小值移动。
- 噪声(噪声数据) 表示离群值、异常或有时重复的数据。
- 超调意味着跳过函数的全局最小值。
- 的优点:
- 收敛比 MBGD 和 SGD 更稳定(波动更小)。
- 它的噪声(噪声数据)比 MBGD 和 SGD 强。
- 它比 MBGD 和 SGD 更少导致过冲。
- 如果没有陷入局部最小值,它会创建比 MBGD 和 SGD 更准确的模型。
- 的缺点:
- 它不擅长在线学习等大型数据集,因为它需要大量内存,减慢收敛速度。 *在线学习是模型从数据集流中实时增量学习的方式。
- 如果你想更新模型,需要重新准备整个数据集。
- 与 MBGD 和 SGD 相比,它更不容易逃脱局部最小值或鞍点。
- 比 MBGD 和 SGD 更容易导致过拟合。
(2)小批量梯度下降(MBGD):
- 可以用分割的数据集(整个数据集的小批量)一小批一小批地进行梯度下降,在一个时期内采取与整个数据集的小批量相同的步数。例如,将具有 100 个样本(1x100)的整个数据集分为 5 个小批次(5x20),然后梯度下降在一个 epoch 内发生 5 次,这意味着模型的参数在一个 epoch 内更新 5 次。
使用从整个数据集中分割出来的每个小批次的平均值,因此每个样本比 BDG 更突出(更强调)。 *将整个数据集分成更小的批次可以使每个样本越来越突出(越来越强调)。因此,收敛比 BGD 更不稳定(波动更大),并且噪声(噪声数据)也比 BGD 弱,比 BGD 更容易导致过冲,并且即使没有陷入局部极小值,也会创建比 BGD 更不准确的模型,但MBGD 比 BGD 更容易逃脱局部最小值或鞍点,因为正如我之前所说,收敛比 BGD 更不稳定(波动更大),MBGD 比 BGD 更不容易导致过拟合,因为每个样本都更稳定正如我之前所说,out(更强调)比 BGD 更重要。
-
的优点:
- 在在线学习等大型数据集上,它比 BGD 更好,因为它比 BGD 占用更少的内存,比 BGD 更不会减慢收敛速度。
- 如果你想更新模型,不需要重新准备整个数据集。
- 它比 BGD 更容易逃脱局部最小值或鞍点。
- 比 BGD 更不容易导致过拟合。
-
的缺点:
- 收敛性比 BGD 更不稳定(波动更大)。
- 它的噪声(噪声数据)不如 BGD 强。
- 它比 BGD 更容易导致过冲。
- 即使没有陷入局部最小值,它也会创建一个不如 BGD 准确的模型。
(3) 随机梯度下降(SGD):
- 可以对整个数据集的每个样本进行梯度下降,一个样本一个样本,在一个时期内采取与整个数据集的样本相同的步数。例如,整个数据集有 100 个样本(1x100),那么梯度下降在一个 epoch 内发生 100 次,这意味着模型的参数在一个 epoch 内更新 100 次。
使用整个数据集的每一个样本逐个样本而不是平均值,因此每个样本比 MBGD 更突出(更强调)。因此,收敛比 MBGD 更不稳定(更波动),并且噪声(噪声数据)也比 MBGD 弱,比 MBGD 更容易导致过冲,并且即使没有陷入局部极小值,也会创建比 MBGD 更不准确的模型,但SGD 比 MBGD 更容易逃脱局部极小值或鞍点,因为正如我之前所说,收敛比 MBGD 更不稳定(波动更大),而且 SGD 比 MBGD 更不容易导致过拟合,因为每个样本都更稳定正如我之前所说,out(更强调)比MBGD。
-
的优点:
- 在大型数据集(例如在线学习)上它比 MBGD 更好,因为它比 MBGD 需要更小的内存,比 MBGD 更不会减慢收敛速度。
- 如果你想更新模型,不需要重新准备整个数据集。
- 它比 MBGD 更容易逃脱局部最小值或鞍点。
- 比 MBGD 更不容易导致过拟合。
-
的缺点:
- 收敛性比 MBGD 更不稳定(波动更大)。
- 它的噪声(噪声数据)不如 MBGD 强。
- 它比 MBGD 更容易导致过冲。
- 如果没有陷入局部最小值,它会创建一个不如 MBGD 准确的模型。
以上是批量、小批量和随机梯度下降的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undress AI Tool
免费脱衣服图片

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 Python类可以有多个构造函数吗?
Jul 15, 2025 am 02:54 AM
Python类可以有多个构造函数吗?
Jul 15, 2025 am 02:54 AM
Yes,aPythonclasscanhavemultipleconstructorsthroughalternativetechniques.1.Usedefaultargumentsinthe__init__methodtoallowflexibleinitializationwithvaryingnumbersofparameters.2.Defineclassmethodsasalternativeconstructorsforclearerandscalableobjectcreati
 用于量子机学习的Python
Jul 21, 2025 am 02:48 AM
用于量子机学习的Python
Jul 21, 2025 am 02:48 AM
要入门量子机器学习(QML),首选工具是Python,需安装PennyLane、Qiskit、TensorFlowQuantum或PyTorchQuantum等库;接着通过运行示例熟悉流程,如使用PennyLane构建量子神经网络;然后按照数据集准备、数据编码、构建参数化量子线路、经典优化器训练等步骤实现模型;实战中应避免一开始就追求复杂模型,关注硬件限制,采用混合模型结构,并持续参考最新文献和官方文档以跟进发展。
 从Python中的Web API访问数据
Jul 16, 2025 am 04:52 AM
从Python中的Web API访问数据
Jul 16, 2025 am 04:52 AM
使用Python调用WebAPI获取数据的关键在于掌握基本流程和常用工具。1.使用requests发起HTTP请求是最直接的方式,通过get方法获取响应并用json()解析数据;2.对于需要认证的API,可通过headers添加token或key;3.需检查响应状态码,推荐使用response.raise_for_status()自动处理异常;4.面对分页接口,可通过循环依次请求不同页面并加入延时避免频率限制;5.处理返回的JSON数据时需根据结构提取信息,复杂数据可用pandas转换为Data
 python一行,如果还有
Jul 15, 2025 am 01:38 AM
python一行,如果还有
Jul 15, 2025 am 01:38 AM
Python的onelineifelse是三元操作符,写法为xifconditionelsey,用于简化简单的条件判断。它可用于变量赋值,如status="adult"ifage>=18else"minor";也可用于函数中直接返回结果,如defget_status(age):return"adult"ifage>=18else"minor";虽然支持嵌套使用,如result="A"i
 成品python大片在线观看入口 python免费成品网站大全
Jul 23, 2025 pm 12:36 PM
成品python大片在线观看入口 python免费成品网站大全
Jul 23, 2025 pm 12:36 PM
本文为您精选了多个顶级的Python“成品”项目网站与高水平“大片”级学习资源入口。无论您是想寻找开发灵感、观摩学习大师级的源代码,还是系统性地提升实战能力,这些平台都是不容错过的宝库,能帮助您快速成长为Python高手。
 python如果还有示例
Jul 15, 2025 am 02:55 AM
python如果还有示例
Jul 15, 2025 am 02:55 AM
写Python的ifelse语句关键在于理解逻辑结构与细节。1.基础结构是if条件成立执行一段代码,否则执行else部分,else可选;2.多条件判断用elif实现,顺序执行且一旦满足即停止;3.嵌套if用于进一步细分判断,建议不超过两层;4.简洁场景可用三元表达式替代简单ifelse。注意缩进、条件顺序及逻辑完整性,才能写出清晰稳定的判断代码。
 python seaborn关节图示例
Jul 26, 2025 am 08:11 AM
python seaborn关节图示例
Jul 26, 2025 am 08:11 AM
使用Seaborn的jointplot可快速可视化两个变量间的关系及各自分布;2.基础散点图通过sns.jointplot(data=tips,x="total_bill",y="tip",kind="scatter")实现,中心为散点图,上下和右侧显示直方图;3.添加回归线和密度信息可用kind="reg",并结合marginal_kws设置边缘图样式;4.数据量大时推荐kind="hex",用
 python run shell命令示例
Jul 26, 2025 am 07:50 AM
python run shell命令示例
Jul 26, 2025 am 07:50 AM
使用subprocess.run()可安全执行shell命令并捕获输出,推荐以列表传参避免注入风险;2.需要shell特性时可设shell=True,但需警惕命令注入;3.使用subprocess.Popen可实现实时输出处理;4.设置check=True可在命令失败时抛出异常;5.简单场景可直接链式调用获取输出;日常应优先使用subprocess.run(),避免使用os.system()或已弃用模块,以上方法覆盖了Python中执行shell命令的核心用法。
