

Hello, I'm a Sales Engineer at Snowflake. I'd like to share some of my experiences and experiments with you through various posts. In this article, I'll show you how to create an app using Streamlit in Snowflake to check token counts and estimate costs for Cortex LLM.
Note: This post represents my personal views and not those of Snowflake.
Streamlit is a Python library that allows you to create web UIs with simple Python code, eliminating the need for HTML/CSS/JavaScript. You can see examples in the App Gallery.
Streamlit in Snowflake enables you to develop and run Streamlit web apps directly on Snowflake. It's easy to use with just a Snowflake account and great for integrating Snowflake table data into web apps.
About Streamlit in Snowflake (Official Snowflake Documentation)
Snowflake Cortex is a suite of generative AI features in Snowflake. Cortex LLM allows you to call large language models running on Snowflake using simple functions in SQL or Python.
Large Language Model (LLM) Functions (Snowflake Cortex) (Official Snowflake Documentation)
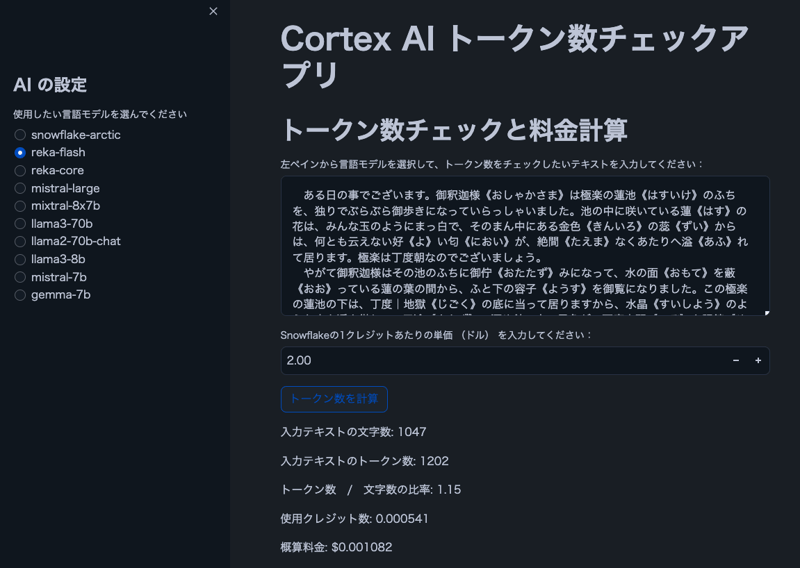
Note: The text in the image is from "The Spider's Thread" by Ryunosuke Akutagawa.
Note: Cortex LLM pricing table (PDF)
Note: Cortex LLM region availability (Official Snowflake Documentation)
import streamlit as st from snowflake.snowpark.context import get_active_session import snowflake.snowpark.functions as F # Get current session session = get_active_session() # Application title st.title("Cortex AI Token Count Checker") # AI settings st.sidebar.title("AI Settings") lang_model = st.sidebar.radio("Select the language model you want to use", ("snowflake-arctic", "reka-core", "reka-flash", "mistral-large2", "mistral-large", "mixtral-8x7b", "mistral-7b", "llama3.1-405b", "llama3.1-70b", "llama3.1-8b", "llama3-70b", "llama3-8b", "llama2-70b-chat", "jamba-instruct", "gemma-7b") ) # Function to count tokens (using Cortex's token counting function) def count_tokens(model, text): result = session.sql(f"SELECT SNOWFLAKE.CORTEX.COUNT_TOKENS('{model}', '{text}') as token_count").collect() return result[0]['TOKEN_COUNT'] # Token count check and cost calculation st.header("Token Count Check and Cost Calculation") input_text = st.text_area("Select a language model from the left pane and enter the text you want to check for token count:", height=200) # Let user input the price per credit credit_price = st.number_input("Enter the price per Snowflake credit (in dollars):", min_value=0.0, value=2.0, step=0.01) # Credits per 1M tokens for each model (as of 2024/8/30, mistral-large2 is not supported) model_credits = { "snowflake-arctic": 0.84, "reka-core": 5.5, "reka-flash": 0.45, "mistral-large2": 1.95, "mistral-large": 5.1, "mixtral-8x7b": 0.22, "mistral-7b": 0.12, "llama3.1-405b": 3, "llama3.1-70b": 1.21, "llama3.1-8b": 0.19, "llama3-70b": 1.21, "llama3-8b": 0.19, "llama2-70b-chat": 0.45, "jamba-instruct": 0.83, "gemma-7b": 0.12 } if st.button("Calculate Token Count"): if input_text: # Calculate character count char_count = len(input_text) st.write(f"Character count of input text: {char_count}") if lang_model in model_credits: # Calculate token count token_count = count_tokens(lang_model, input_text) st.write(f"Token count of input text: {token_count}") # Ratio of tokens to characters ratio = token_count / char_count if char_count > 0 else 0 st.write(f"Token count / Character count ratio: {ratio:.2f}") # Cost calculation credits_used = (token_count / 1000000) * model_credits[lang_model] cost = credits_used * credit_price st.write(f"Credits used: {credits_used:.6f}") st.write(f"Estimated cost: ${cost:.6f}") else: st.warning("The selected model is not supported by Snowflake's token counting feature.") else: st.warning("Please enter some text.")
This app makes it easier to estimate costs for LLM workloads, especially when dealing with languages like Japanese where there's often a gap between character count and token count. I hope you find it useful!
I'm sharing Snowflake's What's New updates on X. Please feel free to follow if you're interested!
Snowflake What's New Bot (English Version)
https://x.com/snow_new_en
Snowflake What's New Bot (Japanese Version)
https://x.com/snow_new_jp
(20240914) Initial post
https://zenn.dev/tsubasa_tech/articles/4dd80c91508ec4
以上是I made a token count check app using Streamlit in Snowflake (SiS)的详细内容。更多信息请关注PHP中文网其他相关文章!


































