

Dify 是一个开源 SaaS 平台,用于在线构建 LLM 工作流程。我正在使用 API 在我的应用程序上创建对话式 AI 体验。我一直在努力获取 TTS 流作为 API 响应并播放它。这里我演示如何处理音频流并正确播放。
我使用 API 端点 https://api.dify.ai/v1/chat-messages 进行文本聊天。如果我们在 Dify 应用程序中启用“文本转语音”功能,它会在与文本响应相同的流中返回音频数据。
按添加功能按钮并添加文本到语音功能。
您可以使用以下curl命令检查API的响应。
我用 TypeScript / JavaScript 进行演示,但您可以将相同的逻辑应用于您的编程语言。
首先,让我们了解一下 Dify 使用什么样的数据进行流。
Dify 使用以下文本数据格式。它类似于 JSON 行,但并不完全相同。
在响应中,Dify 推送文本答案和音频数据。
文本答案示例行
音频数据示例行
我们可以通过检查事件属性来区分音频数据的 JSON 行。音频 JSON 将 tts_message 作为值。音频 mp3 二进制文件以 Base64 格式存储在 JSON 的音频属性中。
实时播放 TTS 音频时遇到的第一个问题是 JSON 行被分成数据包,并且每个数据包都不是有效的 JSON 数据。
从中间切开的示例包
数据包从 JSON 行的中间开始。我们必须组合多个数据包才能获得有效的 JSON 行。
第二个问题是 JSON 中的音频数据块不是有效的音频数据。数据在 mp3 帧的中间被剪切。
为了处理 JSON 和 mp3 的分割数据,我们必须采取一些聪明的方法。流程如下:
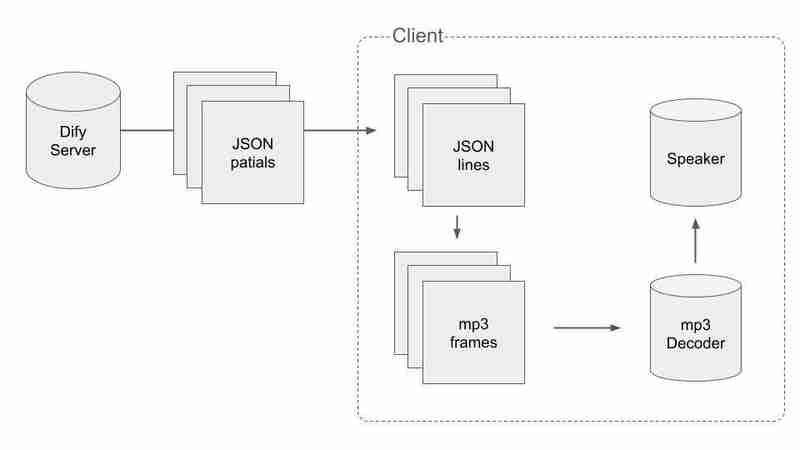
首先,我们必须获取有效的 JSON 数据,并在接收数据包时将其拆分为 JSON。当我们得到一个以 n 结尾的数据包时,我们可以说到目前为止收到的数据包的串联没有在中间被切断。伪代码是这样的。
其次,我们必须将音频块分割成 mp3 帧。我们将音频块连接成二进制文件并找到其中的每个 mp3 帧。
这不是分割成 mp3 帧的完整实现。在实际过程中,我们必须考虑当我们从音频二进制文件中提取 mp3 帧时存在剩余字节并在下一次迭代中使用剩余字节作为音频字节的开头的情况。请检查我的 Github 存储库以了解完整的实施。
以上是如何使用Dify API实现实时语音的详细内容。更多信息请关注PHP中文网其他相关文章!


































