

处理的是一个.js文件,中间包含大量insert命令和update命令。一个命令占一行。
文件大小为222M.
错误信息如下: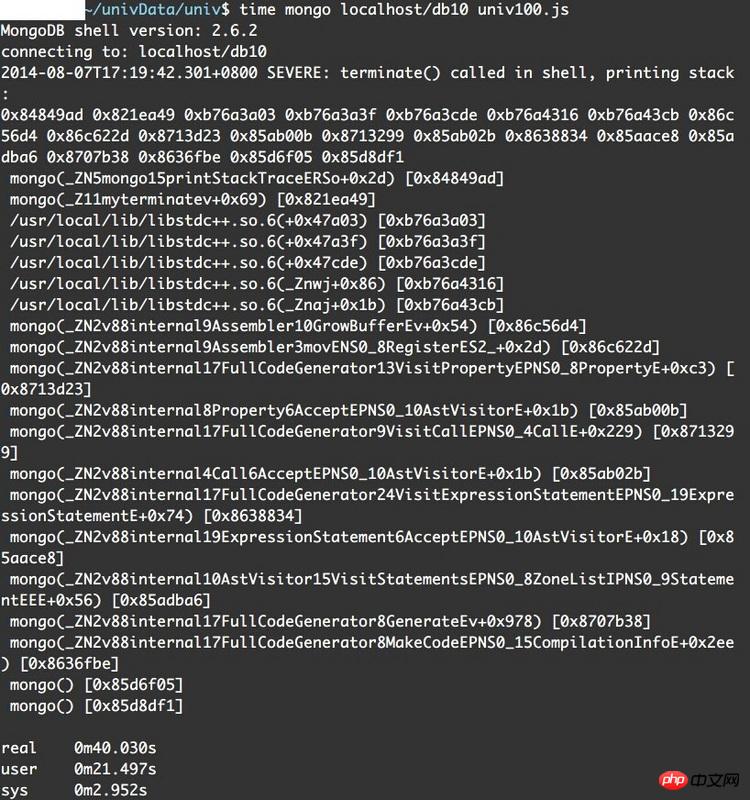
我猜测可能是因为单条命令太长的缘故,但是用mongo直接处理.js文件按理说不会有这样的问题才对吧
系统是debian 32位,版本2.6.32-5-386
在stackoverflow和segmentfault找,也只看到有人遇到堆栈信息中是_ZN5开头的。
在64位mongodb上运行成功了。
但是64位加载2.3G文件的时候又有错误,好在这次有明确信息了。
拆成200多M的文件就能处理了。
很奇怪,我在mongodb文档中没看到说有这种限制啊
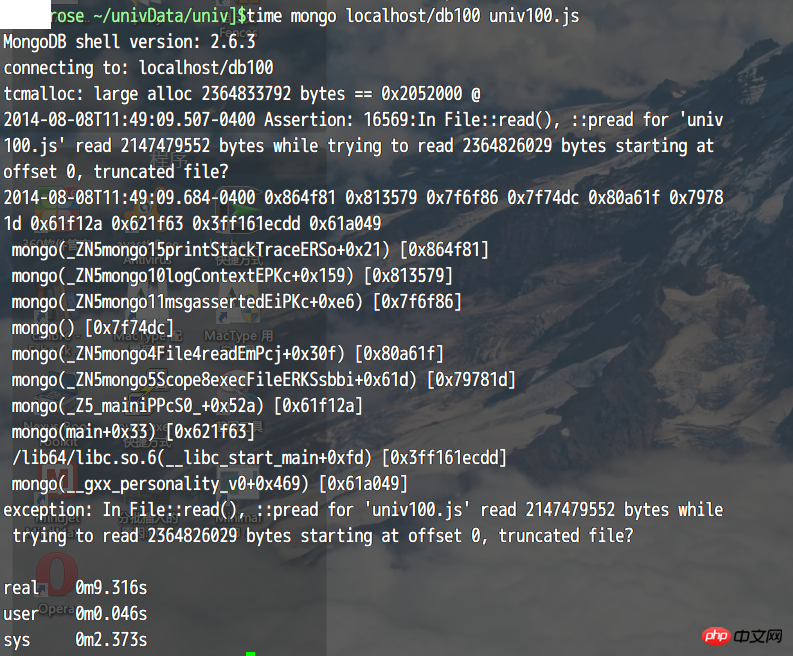
connecting to: localhost/test
tcmalloc: large alloc 2364833792 bytes == 0x2658000 @
2014-08-19T21:49:28.069-0400 Assertion: 16569:In File::read(), ::pread for 'univ100-100.js' read 2147479552 bytes while trying to read 2364826029 bytes starting at offset 0, truncated file?
2014-08-19T21:49:28.164-0400 0x864f81 0x813579 0x7f6f86 0x7f74dc 0x80a61f 0x79781d 0x61f12a 0x621f63 0x3ff161ecdd 0x61a049
mongo(_ZN5mongo15printStackTraceERSo+0x21) [0x864f81]
mongo(_ZN5mongo10logContextEPKc+0x159) [0x813579]
mongo(_ZN5mongo11msgassertedEiPKc+0xe6) [0x7f6f86]
mongo() [0x7f74dc]
mongo(_ZN5mongo4File4readEmPcj+0x30f) [0x80a61f]
mongo(_ZN5mongo5Scope8execFileERKSsbbi+0x61d) [0x79781d]
mongo(_Z5_mainiPPcS0_+0x52a) [0x61f12a]
mongo(main+0x33) [0x621f63]
/lib64/libc.so.6(__libc_start_main+0xfd) [0x3ff161ecdd]
mongo(__gxx_personality_v0+0x469) [0x61a049]
exception: In File::read(), ::pread for 'univ100-100.js' read 2147479552 bytes while trying to read 2364826029 bytes starting at offset 0, truncated file?
real 0m7.922s
user 0m0.045s
sys 0m2.477s

































非常感謝你的報告。
首先,stack trace是gcc mangle過的,可以用 demangler 反過來看到。
假設你的server跟shell一樣是2.6.3, 問題直接出在這裡,shell會把整個script檔讀入記憶體然後編譯,2.3G的檔案在32位元機器上有問題就可以解釋了。但是在64位元機器上也會出問題就不該了。
這裡有兩個問題。
1. 應該限制JS檔案大小為 2G 以相容32位元作業系統。現在的邏輯正確,但是上限太大了,跟描述不符。
2. 在讀取檔案時,系統不總是保證一次
pread呼叫讀完,所以在 file.cpp 中最好多次讀取,直至結束或錯誤。希望我把問題講明白了。臨時辦法是如你所做,把文件分成小份。如果你能在 Jira 中提交這個問題就再好不過了,用英語簡單地描述你遇到的問題就好了。 Kernel工程師會在以後的開發中改進,你也可以在Jira上追蹤這個問題。如果你不方便,我可以幫你提交。
更好的方法是在Jira上提交報告之後,到 Github 上 fork MongoDB的程式碼,修改然後提交 Pull Request,由 Kernel 工程師進行 code reivew, 最終合併進程式碼庫裡。因為這個問題比較罕見,相對獨立,又比較清晰,很適合作為小任務完成後提交Pull Request。然後全世界的 MongoDB 用戶都運行著你寫的程式碼啦。我覺得既然MongoDB中國用戶這麼多,我們有能力為MongoDB社群貢獻力量。如果還有什麼問題就跟我說。
P.S. 我很好奇你為什麼需要一個2.3G的腳本,如果你能告訴我你要做的事情,可能有更優雅的解決方案。