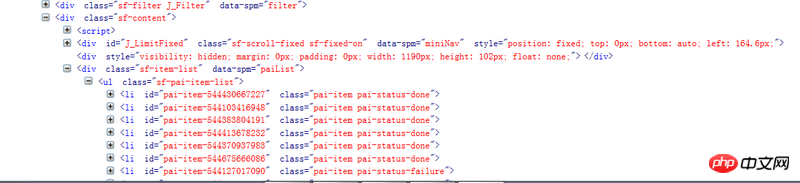
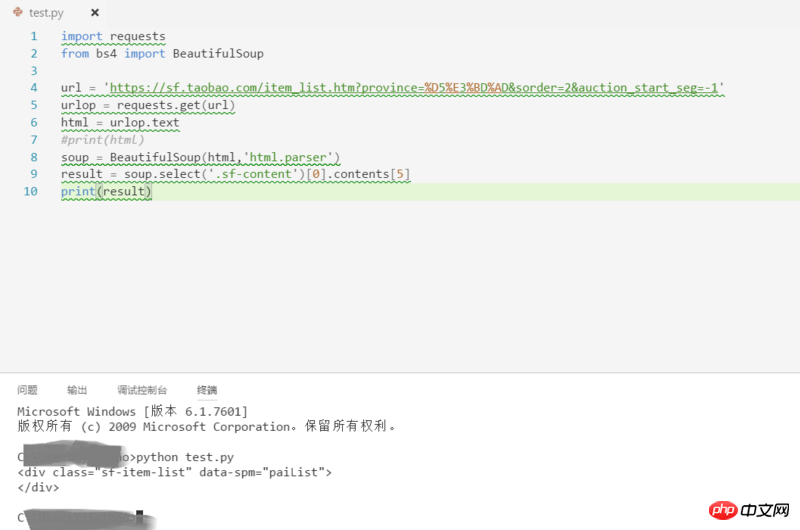
待解析页面的部分代码如第一幅图所示,我自己写的代码及运行结果如第二幅图所示。看到已经有答主提问解析页面丢失是因为用的是lxml的解析方式,我想说我一直用的是html.parser的方式。希望各位大神不吝赐教~
人生最曼妙的风景,竟是内心的淡定与从容!
你們從來都不考慮javascript動態載入的嗎?
題主,如果你用Chrome F12看的話,裡面是會有動態載入的內容的,而這些內容你直接請求頁面的url是拿不到的。建議你點右鍵查看網頁原始碼,對照F12裡面的內容來看,原始碼裡沒有的內容,就去查看Network裡的其他請求,看有沒有你需要的資料。






















你們從來都不考慮javascript動態載入的嗎?
題主,如果你用Chrome F12看的話,裡面是會有動態載入的內容的,而這些內容你直接請求頁面的url是拿不到的。建議你點右鍵查看網頁原始碼,對照F12裡面的內容來看,原始碼裡沒有的內容,就去查看Network裡的其他請求,看有沒有你需要的資料。