




 0
0


这是问题:Find out how much time and over how many separate days did R.Lennon work on administering the Jira Server between August and September.
csv里是这样的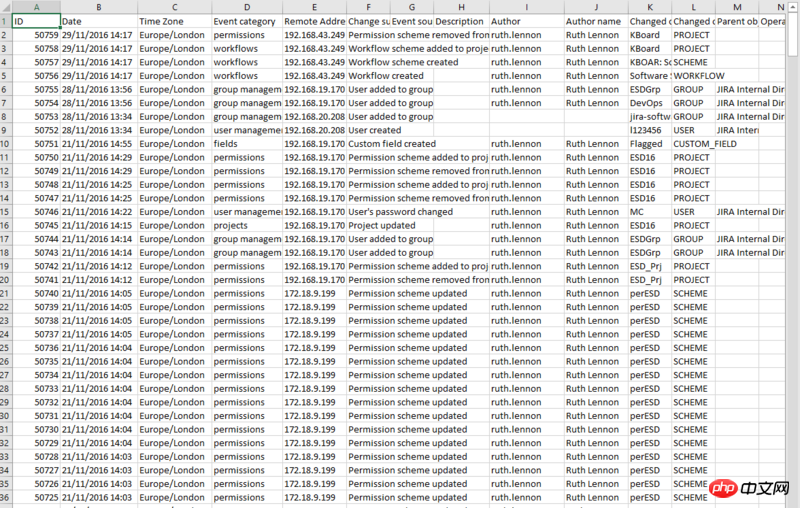
我才开始学习timeseries部分,大概逻辑有了,但是不知道怎么用代码表达。请大神帮忙提一点建议,谢谢!
Your Answer
2 個答案
0
使用re.split拆分Date欄位
import csv,re
with open('xxx.csv','rb') as rf:
reader = csv.reader(rf)
with open('xxx_new.csv','wb') as wf:
writer = csv.writer(wf)
headers = reader.next()
writer.writerow(headers)
for row in reader:
t = re.split('\W+',row[1])
# row[1]为Date字段,被拆为['1', '11', '2016', '14', '17']
if int(t[1]) == 11: # 假设你想要11月数据
writer.writerow(row)
2017-04-18 10:18:45
0
你說timeseries,是用pandas麼?
如果是pandas,其實還蠻簡單的。假設datefrmae的名字是df
首先確保Date那列轉換為DatetimeIndex,這個可以用df['newdate']=pd.DatetimeIndex(df['date'])完成
然後就是篩選了df[df['newdate' ].dt.month==9]就能篩選出所有9月的資料了,

2017-04-18 10:18:45




Hot Questions
function_exists()無法判定自訂函數
2024-04-29 11:01:01
google 瀏覽器 手機版顯示的怎麼實現
2024-04-23 00:22:19
子窗口操作父窗口,輸出沒反應
2024-04-19 15:37:47
父視窗沒有輸出
2024-04-18 23:52:34
關於CSS心智圖的課件在哪?
2024-04-16 10:10:18

Hot Tools

vc9-vc14(32+64位元)運行庫合集(連結在下方)
phpStudy安裝所需運行函式庫集合下載
VC9 32位
VC9 32位元 phpstudy整合安裝環境運行庫
php程式設計師工具箱完整版
程式設計師工具箱 v1.0 php整合環境
VC11 32位
VC11 32位元 phpstudy整合安裝環境運行庫
SublimeText3漢化版
中文版,非常好用
熱門話題
抖音等級價目表1-75
 20337
7
20337
7
 20337
20337
 7
7
wifi顯示無ip分配
13531
4
13531
4
虛擬手機號碼接收驗證碼
11851
4
11851
4
gmail信箱登陸入口在哪裡
8836
17
8836
17
windows安全中心怎麼關閉
8420
7
8420
7
熱門文章
2025年加密貨幣市場十大趨勢預測:下一個風口在哪裡?
2025-11-07
By DDD
幣圈土狗項目如何識別?避免歸零幣的陷阱與風險預警
2025-11-07
By DDD
解決CSS @media 查詢優先級與規則覆蓋問題的教程
2025-11-07
By DDD
win10字體安裝後在軟件裡找不到怎麼辦_win10字體安裝與識別方法
2025-11-07
By DDD
鐵路12306支付失敗訂單還在嗎_鐵路12306支付失敗訂單處理方法
2025-11-07
By DDD