84669 人學習
152542 人學習
20005 人學習
5487 人學習
7821 人學習
359900 人學習
3350 人學習
180660 人學習
48569 人學習
18603 人學習
40936 人學習
1549 人學習
1183 人學習
32909 人學習
本人最近在特运通的电脑客户端内发现了感兴趣的信息,我现在想把里面的数据信息通过爬虫的形式获取下来,我想问下可以通过什么样的思路实现?
现在的基本思路是,通过fiddle或者Wireshark抓包,通过抓包的信息查看数据原链接,然后找规律去用python爬取,但是抓包的数据不知道如何使用,所以求大神指教~~
下图是抓包数据
认证高级PHP讲师
還是沒有回答麼~~~~
自己帶參數去請求,生成url,獲取url的內容就行了看你的截圖,返回的json數據,這個很好解析。不知道你現在哪一步遇到困難。



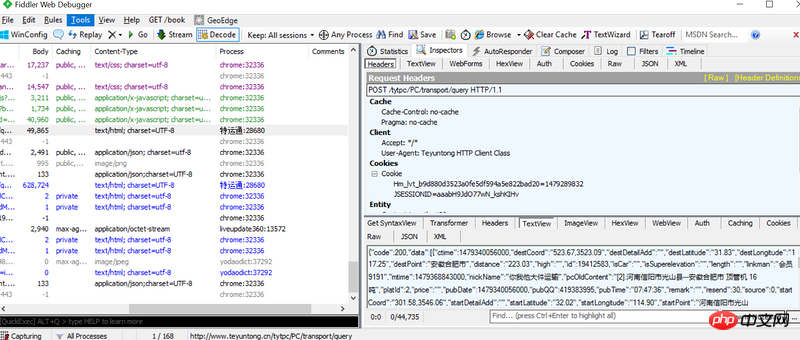
































還是沒有回答麼~~~~
自己帶參數去請求,生成url,獲取url的內容就行了
看你的截圖,返回的json數據,這個很好解析。不知道你現在哪一步遇到困難。