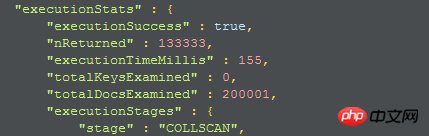
當我直接用find回傳全部欄位時,結果如下,查詢時間為155
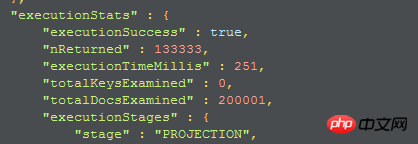
##如果限定傳回字段,查詢時間反而更長了,查詢時間為251
##為什麼?如果我限定回傳的字段,查詢的字元位元組變少,傳輸不應該更快麼?
光阴似箭催人老,日月如移越少年。
您貼出的執行計畫主要透露出的資訊如下:
1、第一個執行計劃:
因為沒有使用到索引,所以collscan透露是全collection掃描,所以可以考慮建立索引
2、第二個執行計畫:
仍然是全collection掃描,並將滿足條件的documents掃描到內存,並在內存中完成projection,選出指定的field,並返回field。這樣子看來,時間會消耗的更多。
儘管是只回傳指定的field,但是讀取儲存的時候,全collection掃描的時候,只能回傳整個documents。這大概是資料庫方面的一些基本原理:按照文件來讀寫的;補充說明,有些列式資料庫是按列保存的,就是您設想的那種情形;但很多資料庫是按照行,或者按照文件保存的。
如果您在指定的field上建立covered index,並且只傳回指定的field,這樣子的效率最佳,因為僅掃描索引就可以傳回指定的field。
供參考。
Love MongoDB! Have fun!
























您貼出的執行計畫主要透露出的資訊如下:
1、第一個執行計劃:
因為沒有使用到索引,所以collscan透露是全collection掃描,所以可以考慮建立索引
2、第二個執行計畫:
仍然是全collection掃描,並將滿足條件的documents掃描到內存,並在內存中完成projection,選出指定的field,並返回field。這樣子看來,時間會消耗的更多。
儘管是只回傳指定的field,但是讀取儲存的時候,全collection掃描的時候,只能回傳整個documents。這大概是資料庫方面的一些基本原理:按照文件來讀寫的;補充說明,有些列式資料庫是按列保存的,就是您設想的那種情形;但很多資料庫是按照行,或者按照文件保存的。
如果您在指定的field上建立covered index,並且只傳回指定的field,這樣子的效率最佳,因為僅掃描索引就可以傳回指定的field。
供參考。
Love MongoDB! Have fun!