一,開頭分析
檔案系統模組是一個簡單包裝的標準 POSIX 檔案 I/O 操作方法集。可以透過呼叫 require("fs") 來取得該模組。文件系統模組中的所有方法均有非同步和同步版本。
(1),檔案系統模組中的非同步方法需要一個完成時的回呼函數作為最後一個傳入形參。
(2),回呼函數的構成是由呼叫的非同步方法決定,通常情況下回呼函數的第一個形參為傳回的錯誤訊息。
(3),如果非同步操作執行正確並傳回,則該錯誤形參則為null或undefined。如果使用的是同步版本的操作方法,一旦發生錯誤,會以通常的拋出錯誤的形式傳回錯誤。
(4),可以用try和catch等語句來攔截錯誤並使程式繼續進行。
我們先看一個簡單的例子,讀取檔案("bb.txt"):
(1),建立文件"bb.txt“,如下內容(”大家好,我是大雄君!(*^__^*) 嘻嘻…“)。
(2),讀取檔案操作如下程式碼:
var fs = require("fs") ;
fs.readFile("bb.txt","utf8",function (error,data){
if(error) throw error ;
console.log(data) ;
}) ;
運行結果:

這裡要注意的是:讀取檔案一定要設定編碼,否則預設是 」buffer「 形式出現。
再看沒設定的運作效果,差別還是很明顯的。如下:

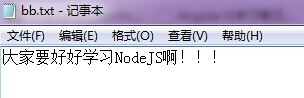
再來一個寫入操作,如下:
var fs = require("fs") ;
var txt = "大家要好好學習NodeJS啊!!!" ;
//寫入檔案
fs.writeFile("bb.txt",txt,function (err) {
if (err) throw err ;
console.log("File Saved !"); //檔案已儲存
}) ;
運行結果:
在列舉一些常用的實例:
// 刪除檔案
fs.unlink('bb.txt', function(){
console.log('success') ;
}) ;
// 修改檔案名稱
fs.rename('bb.txt','bigbear.txt',function(err){
console.log('rename success') ;
});
// 查看檔案狀態
fs.stat('bb.txt', function(err, stat){
console.log(stat);
});
// 判斷檔案是否存在
fs.exists('bb.txt', function( exists ){
console.log( exists ) ;
}) ;
二,Fs與Stream之間的聯繫
"Stream" 具有非同步的特性。我麼可以將一個檔案或一段內容分成未知個制定大小的 "chunk" 去讀取,每讀取到一個 "chunk" 我們就將他輸出。直到文件讀完。這就像 "http1.1" 種支援的 "Transfer-Encoding: chunked" 那樣。 ("chunk"可以以任何的形式存在,NodeJS預設是以 "Buffer" 的形式存在,這樣更有效率)。 NodeJS中的"Stream"具備Unix系統上的一個超級特性就是 ("pipe" ------ 管道)。
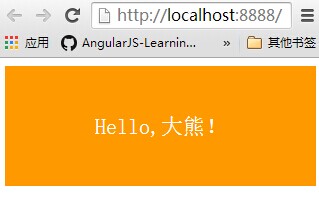
還記得 “Http模組那篇” 第一個NodeJS程序, "Hello,大熊!" 嗎?我們基於那個小程式做一下修改,如下程式碼:
(1),建立「bb.html」
(2),修改之前的程序如下:
var http = require('http') ;
var fs = require("fs") ;
var server = http.createServer(function(req,res){
fs.readFile("bb.html","utf-8", function(err, data){
if(err) {
res.writeHead(500, {'Context-Type': 'text/plain'});
res.end('specify file not exists! or server error!');
}
else{
res.writeHead(200, {'Context-Type': 'text/html'});
res.write(data);
res.end();
}
})
}) ;
server.listen(8888) ;
console.log("http server running on port 8888 ...") ;
以下是運行結果:
現在我們需要思考一下,如果我們要發送的不是一個單純的文本文件而是超媒體文件比如說 Google 2014 IO 大會 的全程高清視頻文件。 mp4 格式。長度2個多小時1080p。
大概4個多GB。已知 "readFile" 的工作方式是將檔案讀取到記憶體。那麼這麼大一個文件顯然是不能這麼做的。那該怎麼辦呢?是之後就需要使用 stream 的來做。那麼是這樣的。
程式碼如下像這樣:
fs.createReadStream(__dirname '/vedio.mp4').pipe(res) ;
總結一下:
這些程式碼可以實現需要的功能,但是服務在發送文件資料之前需要緩存整個文件資料到內存,如果"bb.html"文件很
大且並發量很大的話,會浪費很多記憶體。因為使用者需要等到整個檔案快取到記憶體才能接受的檔案數據,這樣導致
用戶體驗相當不好。不過還好 "(req, res)" 兩個參數都是Stream,這樣我們可以用fs.createReadStream()來取代"fs.readFile()"。
三,實例
來一個文件上傳的小栗子:
(1),建立「server.js」
var http = require('http');
var url = require('url');
函數開始(路線,處理程序){
函數onRequest(請求,回應){
var pathname = url.parse(request.url).pathname;
// 路由至對應的業務邏輯
路線(路徑名稱、處理程序、回應、請求);
}
http.createServer(onRequest).listen(3000);
console.log('伺服器正在啟動');
}
Exports.start = 開始;
(2),建立「route.js」
函數路由(路徑名稱、處理程序、回應、請求){
console.log('即將路由'路徑名的請求);
if (typeof handler[路徑名] === '函數') {
返回處理程序[路徑名稱](回應,請求);
} 其他 {
console.log('未找到'路徑名稱的請求處理程序);
response.writeHead(404, {'Content-Type': 'text/html'});
response.write('404 找不到!');
回應.end();
}
}
Exports.route = 路線;
(3),建立「requestHandler.js」
var querystring = require('querystring'),
fs = require('fs'),
強大 = require('強大');
函數開始(回應,請求){
console.log('啟動模組');
var body = ''
''
'
'內容=“text/html;字符集=UTF-8”/>'
'頭>'
''
''
''
''
'表單>'
''
'























