

推薦系統對於應對資訊過載挑戰重要,它們根據使用者的個人偏好提供客製化推薦。近年來深度學習技術大大推動了推薦系統的發展,提升了對使用者行為和偏好的洞察力。
然而,由於資料稀疏性的問題,傳統的監督學習方法在實際應用中臨挑戰,這限制了它們有效學習使用者表現的能力。
為了保護克服這個難題,自監督學習(SSL)技術應用於生,其利用資料的內在結構產生監督訊號,不完全依賴標記資料。
這種方法使用得推薦系統能夠足夠利用未標記的資料來提取有意義的信息,即使在資料稀缺的情況下也能做出準確的預測和推薦。

文章網址:https://arxiv.org/abs/2404.03354
開源資料庫:https://github.com/HKUDS/Awesome-SSLRec-Papers
開原始碼庫:https://github.com/HKUDS/SSLRec
本文綜述了專為推薦系統設計的自監督學習框架,並深入分析了超過170篇相關論文。我們探討了九種不同的應用場景,全面了解SSL在不同情境下如何增強推薦系統。
對於每個領域,我們都詳細討論了不同的自監督學習範式,包括對比學習、生成學習和對抗學習,展示了SSL如何在不同情境下提升推薦系統的性能。
#推薦系統的研究涵蓋了不同場景下的各種任務,如協同過濾、序列推薦和多行為推薦等等。這些任務擁有不同的資料範式和目標。這裡,我們首先提供一個通用的定義,不深入不同推薦任務的具體變體。在推薦系統中,有兩個主要的集合:使用者集合,記為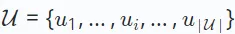 ,和物品集合,記為
,和物品集合,記為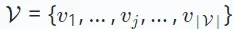 。
。
然後,使用一個互動矩陣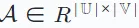 來表示使用者和物品之間的記錄互動。在這個矩陣中,如果使用者ui與物品vj有過交互,則矩陣的條目Ai,j被賦予值1,否則為0。
來表示使用者和物品之間的記錄互動。在這個矩陣中,如果使用者ui與物品vj有過交互,則矩陣的條目Ai,j被賦予值1,否則為0。
互動的定義可以根據不同的情境和資料集進行調整(例如,觀看電影、在電子商務網站上點擊或進行購買)。
此外,在不同的推薦任務中,存在不同的輔助觀察數據,記為X,例如在知識圖譜增強推薦中,X包含了包含外部物品屬性的知識圖譜,這些屬性包括不同的實體類型和相應的關係。
而在社群推薦中, X包含了使用者層級的關係,如友誼。基於上述定義,推薦模型優化了一個預測函數f(⋅),旨在準確估計任何用戶u和物品v之間的偏好分數:
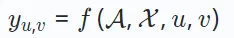
偏好分數yu,v表示使用者u和物品v互動的可能性。
基於這個分數,推薦系統可以透過根據估計的偏好分數提供物品的排名列表,向每個使用者推薦未互動的物品。在綜述中,我們進一步探討不同推薦情境下(A,X)的資料形式以及自監督學習其中的角色。
過去幾年中,深度神經網路在監督學習中表現出色,這在包括電腦視覺、自然語言處理和推薦系統在內的各領域都有所體現。然而由於對標記資料的重度依賴,監督學習在處理標籤稀疏性問題時面臨挑戰,這也是推薦系統中的常見問題。
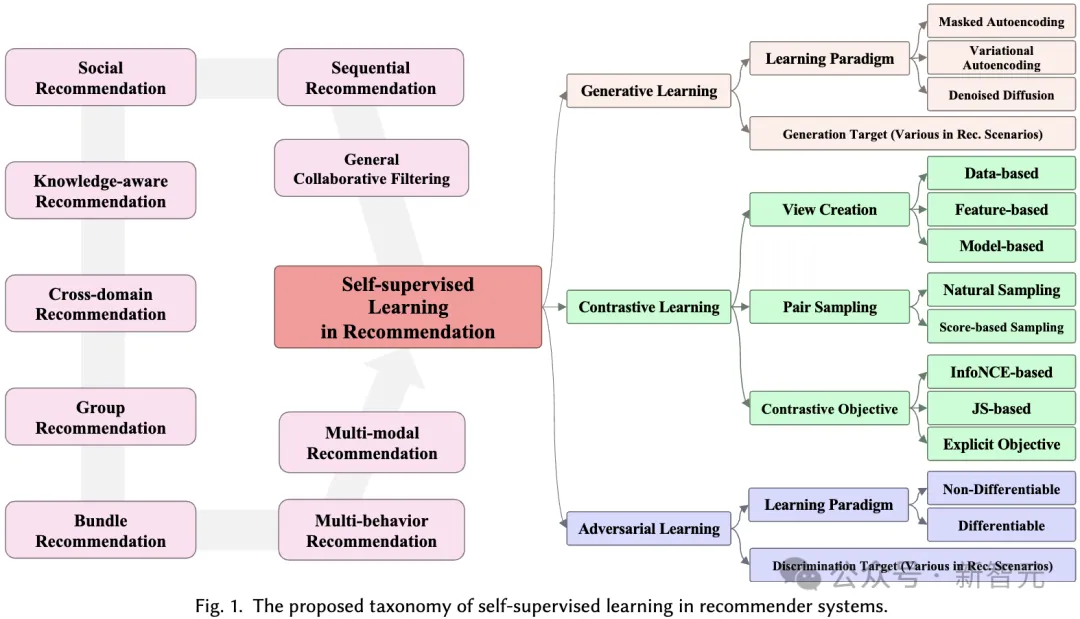
為了解決這個限制,自監督學習作為一種有前景的方法應運而生,它利用資料本身作為學習的標籤。推薦系統中的自監督學習包含三種不同的典範:對比學習、生成學習和對抗學習。
##對比學習作為一種突出的自監督學習方法,其主要目標是最大化從資料中增強的不同視圖之間的一致性。在推薦系統的比較學習中,目標是最小化以下損失函數:
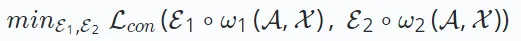
E∗∘ω∗表示對比視圖創建操作,不同的基於對比學習的推薦演算法有不用的創建過程。每個視圖的構造由資料增強過程ω∗(可能涉及在增強圖中的節點/邊)以及嵌入編碼過程E∗組成。
最小化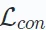 的目標是獲得穩健的編碼函數,最大化視圖之間的一致性。這種跨視圖的一致性可以透過互資訊最大化或實例判別等方法來實現。
的目標是獲得穩健的編碼函數,最大化視圖之間的一致性。這種跨視圖的一致性可以透過互資訊最大化或實例判別等方法來實現。
編碼器
從輸入建立潛在表示,而解碼器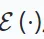 從編碼器輸出重建原始資料。目標是最小化重建和原始資料之間的差異,具體如下所示:
從編碼器輸出重建原始資料。目標是最小化重建和原始資料之間的差異,具體如下所示: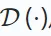
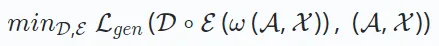
的格式取決於資料類型,例如連續資料使用均方誤差,對於分類資料使用交叉熵損失。 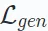
因此,對抗學習的學習目標可以定義如下:
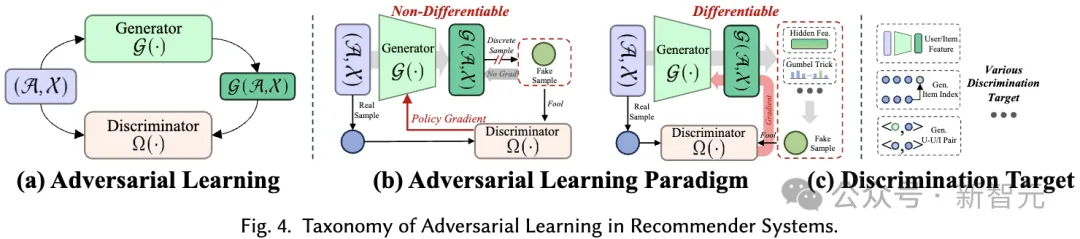
這裡,變數x表示從底層資料分佈得到的真實樣本,而 #在本節中,我們提出了自監督學習在推薦系統中的應用的全面分類體系。如前所述,自監督學習範式可以分為對比學習、生成學習、對抗學習三個類別。因此,我們的分類體系基於這三個類別構建,提供了每個類別更深入的見解。 對比學習(CL)的基本原理是最大化不同視圖之間的一致性。因此,我們提出了一個以視圖為中心的分類體系,包含應用對比學習時考慮的三個關鍵組成部分:建立視圖、配對視圖以最大化一致性,以及優化一致性。 視圖建立(View Creation)。 所建立的視圖強調了模型要關注的多種資料面向。它可以結合全域協同資訊以改善推薦系統處理全域關係的能力,或引入隨機雜訊以增強模型的穩健性。 我們將輸入資料(例如,圖、序列、輸入特徵)的增強視為資料層面的視圖創建,而隱藏特徵在推理過程中的增強則視為特徵層面的視圖建立。我們提出了一個層次化的分類體系,包括從基本資料層面到神經模型層面的視圖創建技術。 配對取樣(Pair Sampling)。 視圖建立過程為資料中的每個樣本產生至少兩個不同的視圖。對比學習的核心在於最大化地對齊某些視圖(即拉近它們),同時推開其他視圖。 為此,關鍵在於確定應拉近的正樣本對,並識別形成負樣本對的其他視圖。這種策略稱為配對取樣,它主要由兩種配對取樣方法組成: 比較學習目標(Contrastive Objective)。 對比學習中的學習目標是最大化正樣本對之間的互信息,這反過來又可以提高學習推薦模型的性能。由於直接計算互資訊不可行,通常使用可行的下界作為對比學習中的學習目標。然而,也有直接將正樣本對拉近的明確目標。 在生成式自監督學習中,主要目標是最大化真實資料分佈的似然估計。這允許學習到的有意義的表示捕獲資料中的底層結構和模式,然後可以用於下游任務。在我們的分類體系中,我們考慮了兩個面向來區分不同的基於生成學習的建議方法:產生學習範式和生成目標。 #產生學習範式(Generative Learning Paradigm)。 在建議的背景下,採用生成學習的自監督方法可以被分類為三個範式: 產生目標(Generation Target)。 在生成學習中,將資料的哪種模式視為產生的標籤,是另一個需要考慮的問題,以帶來有意義的輔助自監督訊號。一般來說,生成目標對於不同的方法以及在不同的推薦場景中各不相同。例如,在序列推薦中,產生目標可以是序列中的物品,目的是模擬序列中物品之間的關係。在交互圖推薦中,產生目標可以是圖中的節點/邊,目的是捕捉圖中的高階拓樸相關性。 在在推薦系統的對抗學習中,鑑別器在區分生成的虛假樣本和真實樣本中起著至關重要的作用。與生成學習類似,我們提出的分類體系從學習範式和鑑別目標兩個角度涵蓋了推薦系統中的對抗學習方法: 對抗學習範式(Adversarial Learning Paradigm)。 在推薦系統中,對抗學習包含兩種不同的範式,這取決於鑑別器的判別損失是否可以以可微的方式反向傳播到生成器。 鑑別目標(Discrimination Target)。 不同推薦演算法導致生成器產生不同的輸入,這些輸入隨後被饋送到鑑別器進行鑑別。這個過程旨在增強生成器生成高品質內容的能力,從而接近真實情況。具體的鑑別目標是根據特定的推薦任務設計的。 在本綜述中,我們從九種不同的推薦場景深入討論不同的自監督學習方法在其中的設計方式,這九種推薦場景分別為(具體內容歡迎到文中了解): #本文全面綜述了自監督學習(SSL)在推薦系統中的應用,深入分析了逾170篇論文。我們提出了一個涵蓋九大推薦情境的自監督分類體系,詳細探討了對比學習、生成學習和對抗學習三種SSL範式,並在文中討論了未來研究方向。 我們強調了SSL在處理資料稀疏性、提升推薦系統效能方面的重要性,並指出了將大型語言模型整合到推薦系統中、自適應動態推薦環境以及為SSL範式建立理論基礎等潛在研究方向。希望本綜述能為研究者提供寶貴的資源,並激發新的研究思路,推動推薦系統的進一步發展。 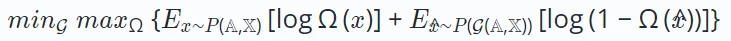
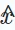 表示由生成器G(⋅)產生的合成樣本。在訓練過程中,生成器和鑑別器都透過競爭性互動來提高它們的能力。最終,生成器致力於產生高品質的輸出,這些輸出對於下游任務是有利的。
表示由生成器G(⋅)產生的合成樣本。在訓練過程中,生成器和鑑別器都透過競爭性互動來提高它們的能力。最終,生成器致力於產生高品質的輸出,這些輸出對於下游任務是有利的。 3 分類體系(Taxonomy)
3.1 推薦系統中的對比學習
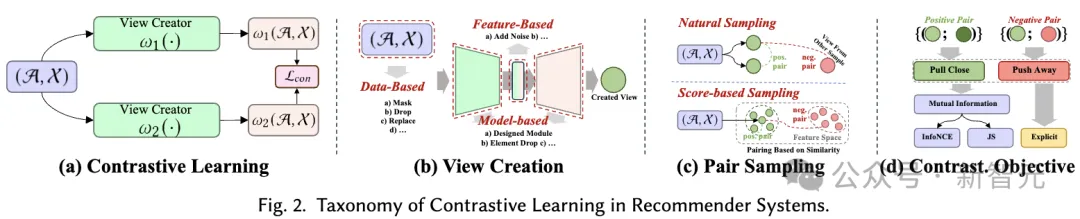
3.2 推薦系統中的生成學習

3.3 推薦系統中的對抗學習
3.4 多元的建議情境
4 結語
以上是綜述170篇「自監督學習」推薦演算法,港大發表SSL4Rec:程式碼、資料庫全面開源!的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















