

最新國產開源MoE大模型,剛亮相就火了。
DeepSeek-V2效能達GPT-4級別,但開源、可免費商用、API價格僅為GPT-4-Turbo的百分之一。
因此一經發布,立刻引發不小討論。
 圖片
圖片
透過公佈的效能指標來看,DeepSeek V2的中文綜合能力超越一眾開源模型,同時GPT-4 Turbo、文字快4.0等閉源模型同處第一梯隊。
英文綜合能力也和LLaMA3-70B同處第一梯隊,並且超過了同是MoE的Mixtral 8x22B。
在知識、數學、推理、程式設計等方面也表現出不錯性能。並支援128K上下文。
 圖片
圖片
這些能力,一般使用者都能直接免費使用。現在內測已開啟,註冊後立刻就能體驗。
 圖片
圖片
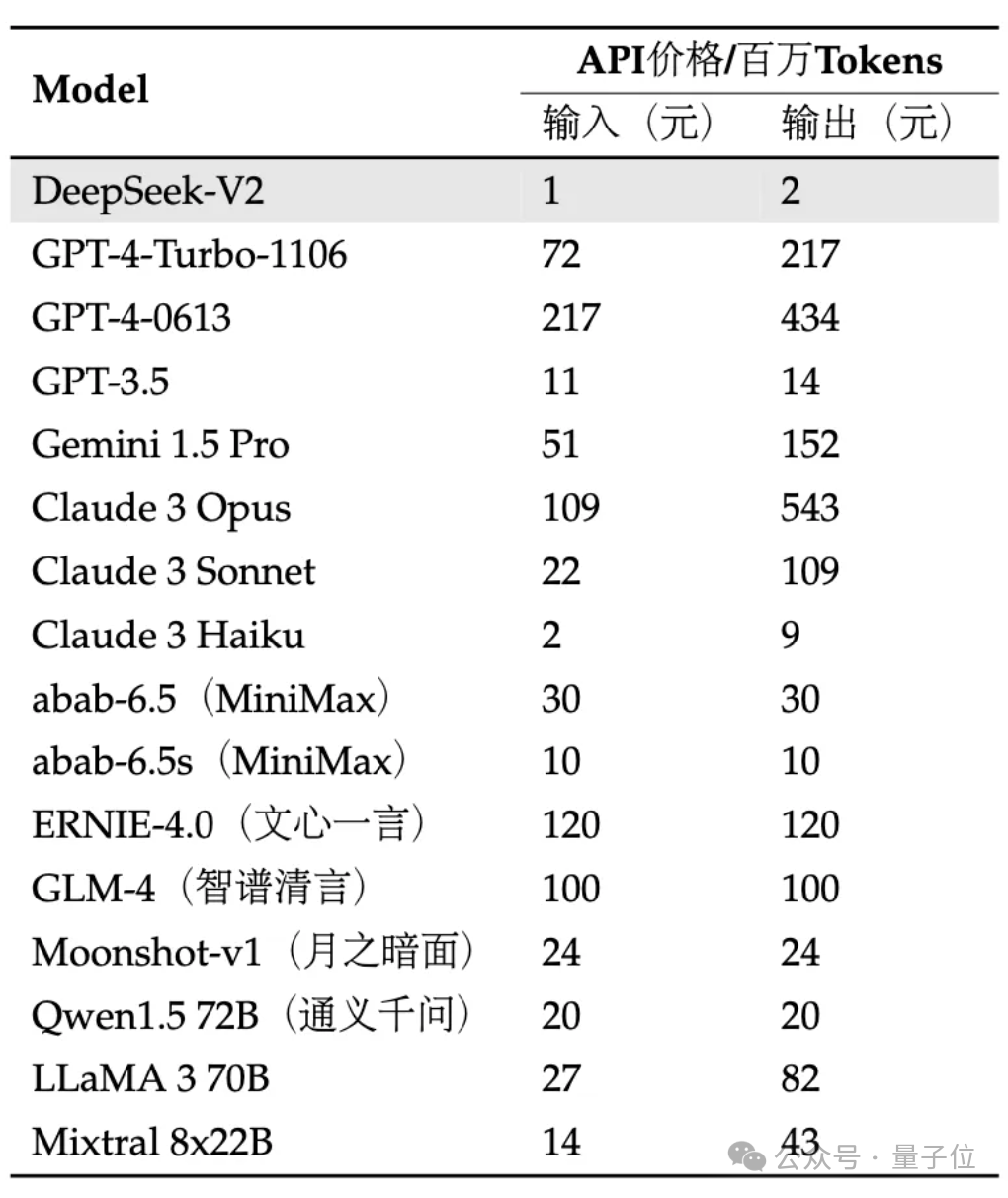
API更是骨折價:每百萬tokens輸入1元、輸出2元(32K上下文)。價格僅為GPT-4-Turbo的近百分之一。
同時在模型架構也進行創新,採用了自研的MLA(Multi-head Latent Attention)和Sparse結構,可大幅減少模型計算量、推理顯存。
網友感嘆:DeepSeek總是給人驚喜!
 圖片
圖片
具體效果如何,我們已搶先體驗!
目前V2內測版可以體驗通用對話和程式碼助理。
 圖片
圖片
在通用對話中可以測試大模型的邏輯、知識、生成、數學等能力。
例如可以要求它模仿《甄嬛傳》的文風寫口紅種草文案。
 圖片
圖片
還可以簡單解釋什麼是量子糾纏。
 圖片
圖片
數學方面,能回答高數微積分問題,例如:
使用微積分證明自然對數的底e 的無窮級數表示。
 圖片
圖片
也能規避一些語言邏輯陷阱。
 圖片
圖片
測試顯示,DeepSeek-V2的知識內容更新到2023年。
 圖片
圖片
程式碼方面,內測頁面顯示是使用DeepSeek-Coder-33B回答問題。
在產生較簡單程式碼上,實測幾次都沒有出錯。
 圖片
圖片
也能針對給定的程式碼做出解釋和分析。
 圖片
圖片
 圖片
圖片
不過測試中也有回答錯誤的情況。
如下邏輯題目,DeepSeek-V2在計算過程中,錯誤將一支蠟燭從兩端同時點燃、燃燒完的時間,計算成了從一端點燃燒完的四分之一。
 圖片
圖片
根據官方介紹,DeepSeek-V2以236B總參數、21B激活,大致達到70B~110B Dense的模型能力。
 圖片
圖片
和先前的DeepSeek 67B相比,它的表現更強,同時訓練成本更低,可節省42.5%訓練成本,減少93.3%的KV緩存,最大吞吐量提高到5.76倍。
官方表示這意味著DeepSeek-V2消耗的顯存(KV Cache)只有同級Dense模型的1/5~1/100,每token成本大幅降低。
專門針對H800規格做了大量通訊優化,實際部署在8卡H800機器上,輸入吞吐量超過每秒10萬tokens,輸出超過每秒5萬tokens。
 圖片
圖片
在某些基礎Benchmark上,DeepSeek-V2基礎模型表現如下:
 圖片
圖片
DeepSeek-V2 採用了創新的架構。
提出MLA(Multi-head Latent Attention)架構,大幅減少運算量與推理顯存。
同時自研了Sparse結構,使其計算量進一步降低。
 圖片
圖片
有人就表示,這些升級對於資料中心大型運算可能非常有幫助。
 圖片
圖片
而且在API定價上,DeepSeek-V2幾乎低於市面上所有明星大模型。
 圖片
圖片
團隊表示,DeepSeek-V2模型和論文也將完全開源。模型權重、技術報告都給。
現在登入DeepSeek API開放平台,註冊即贈送1000萬輸入/500萬輸出Tokens。普通試玩則完全免費。
以上是國產開源MoE指標爆炸:GPT-4等級能力,API價格僅百分之一的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















