

多模態 AI 系統的特點在於能夠處理和學習包括自然語言、視覺、音訊等各種類型的數據,從而指導其行為決策。近期,將視覺資料納入大型語言模型(如 GPT-4V)的研究取得了重要進展,但如何有效地將影像資訊轉化為 AI 系統的可執行操作仍面臨挑戰。 為了實現圖像資訊的轉化,一種常見的方法是將圖像資料轉化為對應的文字描述,然後由 AI 系統根據描述進行操作。這可以透過在現有的圖像資料集上進行監督學習,讓 AI 系統自動學習圖像到文字的映射關係。此外,還可以利用強化學習方法,透過與環境互動來學習如何根據影像資訊進行決策。 另一種方法是直接將圖像資訊與語言模型結合,建構
在最近的一篇論文中,研究者提出了一種專為AI 應用設計的多模態模型,引入了「functional token”的概念。
論文標題:Octopus v3: Technical Report for On-device Sub-billion Multimodal AI Agent
論文連結:https://arxiv .org/pdf/2404.11459.pdf
模型權重與推理程式碼:https://www.nexa4ai.com/apply
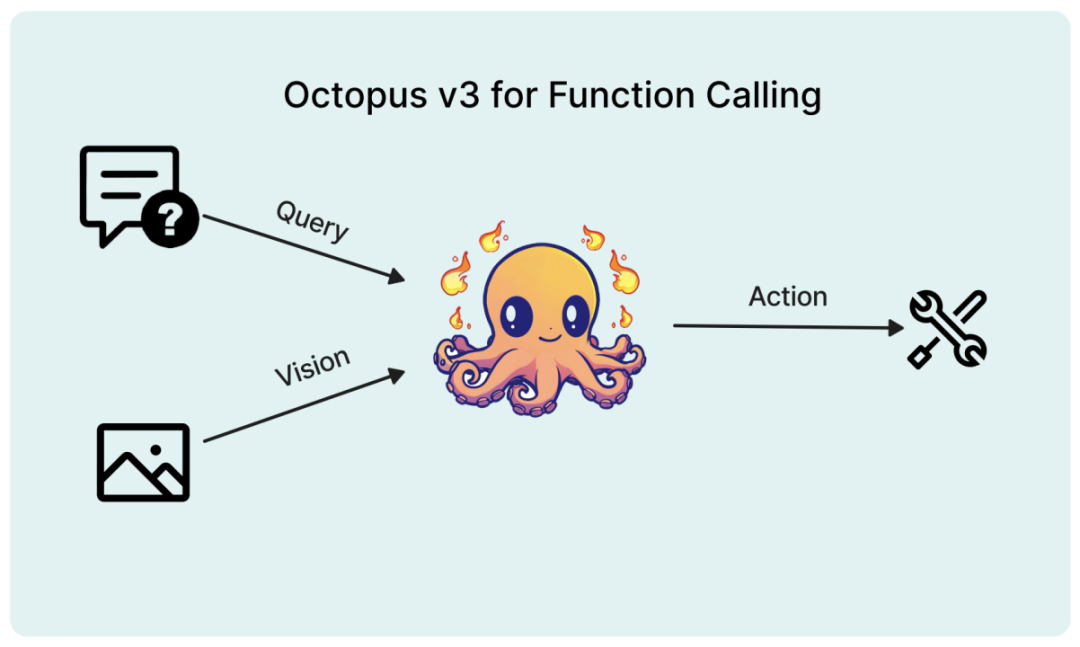
#此模型能完整支援邊緣設備,研究者將其參數量優化至10億以內。與GPT-4類似,此模型能同時處理英文和中文。實驗證明,模型能在包括樹莓派等各類資源受限的終端設備上高效運作。
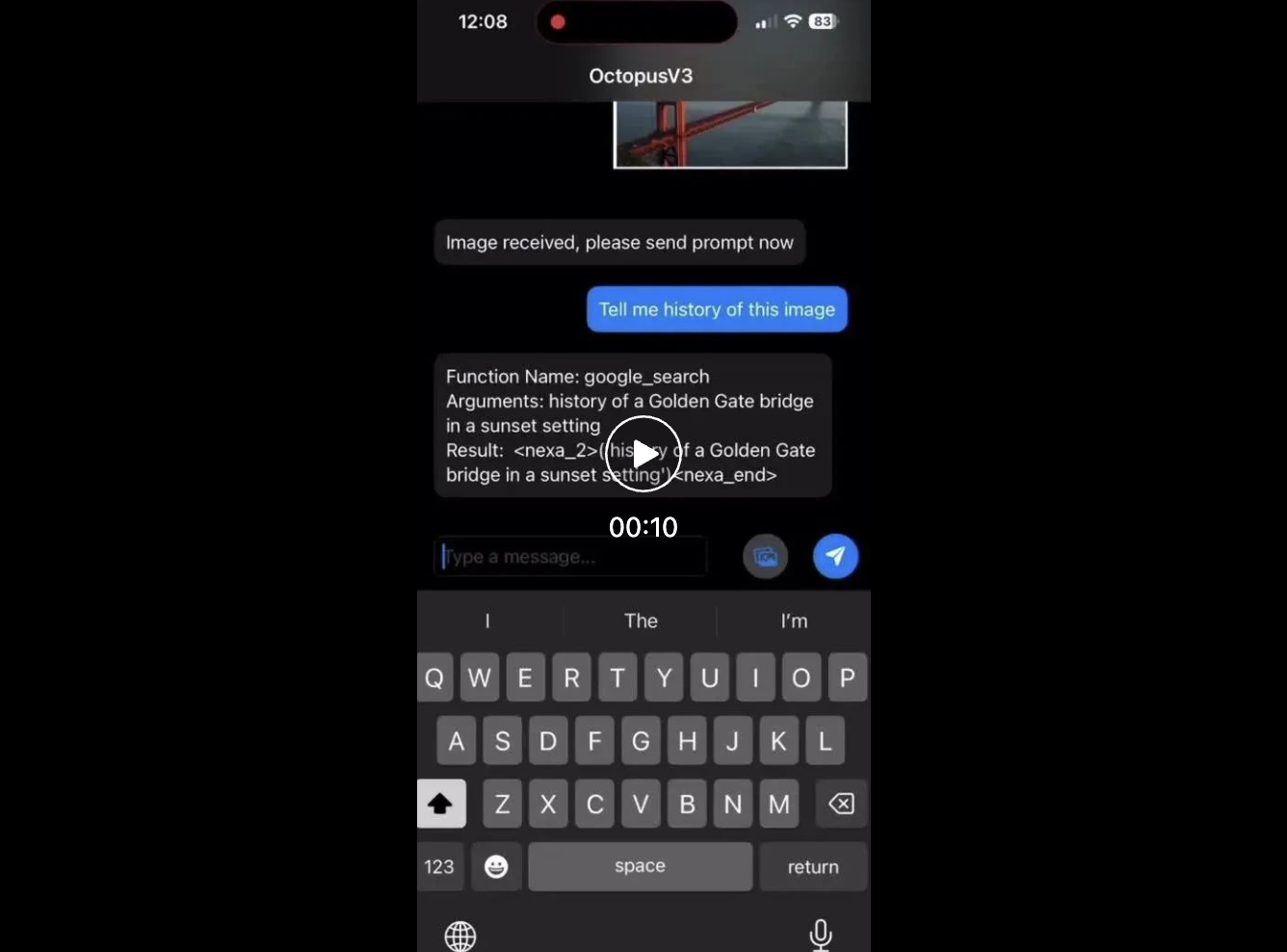
###研究背景#######
人工智慧技術的快速發展徹底改變了人機互動的方式,催生出一批能夠根據自然語言、視覺等多種形式的輸入執行複雜任務、做出決策的智慧 AI 系統。這些系統有望實現從影像辨識、語言翻譯等簡單任務到醫療診斷、自動駕駛等複雜應用的自動化。多模態語言模型是這些智慧系統的核心,使其能夠透過處理整合文字、影像乃至音視頻等多模態數據,理解並產生近乎人類的回應。相較於主要關注文本處理和產生的傳統語言模型,多模態語言模型是一大躍進。透過納入視覺訊息,這些模型能夠更好地理解輸入資料的脈絡和語義,從而給出更準確、相關的輸出。處理和整合多模態資料的能力,對於開發多模態 AI 系統至關重要,使其能夠同時理解語言和視覺資訊的任務,例如視覺問答、影像導航、多模態情緒分析等。
開發多模態語言模型的一大挑戰在於,如何將視覺訊息有效地編碼為模型可處理的格式。這通常藉助神經網路架構,例如視覺變換器(ViT)和卷積神經網路(CNN),從影像中提取層次化特徵的能力,在電腦視覺任務中得到廣泛應用。使用這些架構作為模型,可以學習從輸入資料中提取更複雜的表徵。此外,基於transformer的架構不僅能夠捕捉長距離依賴關係,在理解影像中物體之間關係方面表現出色。近年來備受青睞。這些架構使模型能夠從輸入圖像中提取有意義的特徵,並將其轉換為可與文字輸入結合的向量表示。
編碼視覺訊息的另一種方法是影像符號化 (tokenization), 即將影像分割為更小的離散單元或 token。這種方法讓模型能以類似處理文字的方式來處理影像,實現兩種模態的更無縫融合。圖像 token 資訊可與文字輸入一同送入模型,使其能同時關注兩種模態並產生更準確、更契合上下文的輸出。例如,OpenAI 開發的 DALL-E 模型採用 VQ-VAE (向量量化變分自編碼器) 的變體對圖像進行符號化,使模型能根據文字描述產生新穎圖像。開發出能夠根據使用者提供的查詢和圖像採取行動的小型高效模型,對 AI 系統的未來發展影響深遠。這些模型可部署於智慧型手機、物聯網設備等資源受限的裝置上,擴大其應用範圍與場景。借助多模態語言模型的威力,這些小型系統能以更自然、直觀的方式理解和回應使用者的問詢,同時考慮使用者提供的視覺脈絡。這為實現更具吸引力、個性化的人機互動開啟了可能,例如根據用戶喜好提供視覺推薦的虛擬助手,或根據用戶面部表情調節設置的智慧家居設備。
此外,多模態 AI 系統的發展有望實現人工智慧技術的民主化,讓更廣泛的使用者和產業受益。更小巧高效的模型可在算力較弱的硬體上訓練,降低部署所需的運算資源和能耗。這可能帶來 AI 系統在醫療、教育、娛樂、電商等各個領域的廣泛應用,最終改變人們的生活和工作方式。
相關工作
多模態模型由於能夠處理和學習文字、圖像、音訊等多種資料類型而備受關注。這類模型能捕捉不同模態間複雜的交互,並利用它們的互補資訊來提升各類任務的表現。視覺 - 語言預訓練 (VLP) 模型如 ViLBERT、LXMERT、VisualBERT 等,透過跨模態注意力學習視覺和文字特徵的對齊,產生豐富的多模態表徵。多模態 transformer 架構如 MMT、ViLT 等則對 transformer 做了改進,以高效處理多種模態。研究者也嘗試將音訊、臉部表情等其他模態納入模型,如多模態情緒分析 (MSA) 模型、多模態情緒辨識 (MER) 模型等。透過利用不同模態的互補訊息,多模態模型相比單模態方法取得了更優的效能和泛化能力。
終端語言模型定義為參數量少於 70 億的模型,因為研究者發現即使採用量化,在邊緣設備上運行 130 億參數的模型也非常困難。這一領域近期的進展包括 Google 的 Gemma 2B 和 7B、Stable Diffusion 的 Stable Code 3B 以及 Meta 的 Llama 7B。有趣的是,Meta 的研究表明,與大型語言模型不同,小型語言模型採用深而窄的架構會有更好的表現。其他對終端模型有益的技術還包括 MobileLLM 中提出的 embedding 共享、分組 query 注意力以及即時分塊權重共享等。這些發現凸顯了在開發終端應用的小型語言模型時,需要考慮不同於大模型的最佳化方法和設計策略。
Octopus 方法
Octopus v3 模型開發中採用的主要技術。多模態模型開發的兩個關鍵方面是:將圖像資訊與文字輸入相整合,以及優化模型預測動作的能力。
視覺訊息編碼
影像處理中存在多種視覺訊息編碼方法,常用隱藏層的 embedding。例如,VGG-16 模型的隱藏層 embedding 被用於風格遷移任務。 OpenAI 的 CLIP 模型展示了對齊文字和圖像 embedding 的能力,利用其圖像編碼器來嵌入圖像。 ViT 等方法則採用了圖像 tokenization 等更先進的技術。研究者評估了多種影像編碼技術,發現 CLIP 模型的方法最有效。因此,本文採用基於 CLIP 的模型進行影像編碼。
Functional token
與套用於自然語言和映像的 tokenization 類似,特定 function 也可封裝為 functional token。研究者為這些 token 引入了一種訓練策略,借鑒了自然語言模型處理未見詞的技術。這方法與 word2vec 類似,透過 token 的脈絡環境來豐富其語意。例如,高階語言模型最初可能難以應對 PEGylation 和 Endosomal Escape 等複雜化學術語。但透過因果語言建模,尤其是在包含這些術語的資料集上訓練,模型能夠習得這些術語。類似地,functional token 也可透過平行策略習得,其中 Octopus v2 模型可為此類學習過程提供強大的平台。研究表明,functional token 的定義空間是無限的,從而能夠將任意特定 function 表示為 token。
多階段訓練
為開發出高效能的多模態 AI 系統,研究者採用了整合因果語言模型和影像編碼器的模型架構。此模型的訓練過程分為多個階段。首先,因果語言模型和圖像編碼器分別訓練,建立基礎模型。隨後,將這兩個部件合併,並進行對齊訓練以同步圖像和文字處理能力。在此基礎上,借鏡 Octopus v2 的方法來促進 functional token 的學習。在最後一個訓練階段中,這些能夠與環境互動的 functional token 提供回饋,用於進一步最佳化模型。因此,最後階段研究者採用強化學習,並選擇另一個大型語言模型作為獎勵模型。這種迭代訓練方式增強了模型處理和整合多模態資訊的能力。
模型評估
本節介紹模型的實驗結果,並與整合 GPT-4V 和 GPT-4 模型的效果進行比較。在對比實驗中,研究者首先採用 GPT-4V (gpt-4-turbo) 處理影像資訊。然後將提取的資料輸入 GPT-4 框架 (gpt-4-turbo-preview), 將所有 function 描述納入上下文並應用小樣本學習以提升效能。在演示中,研究者將 10 個常用的智慧型手機 API 轉換為 functional token 並評估其表現,詳見後續小節。
值得注意的是,雖然本文僅展示了 10 個 functional token, 但該模型可以訓練更多 token 以創建更通用的 AI 系統。研究者發現,對於選定的 API, 參數量不到 10 億的模型作為多模態 AI 表現可與 GPT-4V 和 GPT-4 的組合相媲美。
此外,本文模型的可擴展性允許納入廣泛的 functional token, 從而能夠打造高度專業化的 AI 系統,適用於特定領域或場景。這種適應性使本文方法在醫療、金融、客戶服務等產業尤為有價值,這些領域中 AI 驅動的解決方案可顯著提升效率和使用者體驗。
在下面的所有function 名稱中,Octopus 僅輸出functional token 如,...,
發送郵件

#發送簡訊

Google 搜尋
亞馬遜購物
智慧回收
#失物招領
###室內設計# #####

Instacart 购物

DoorDash 外卖

宠物护理

社会影响
在 Octopus v2 的基础上,更新后的模型纳入了文本和视觉信息,从其前身纯文本方法迈出了重要一步。这一显著进展实现了视觉和自然语言数据的同步处理,为更广泛的应用铺平了道路。Octopus v2 引入的 functional token 可适应多个领域,如医疗和汽车行业。随着视觉数据的加入,functional token 的潜力进一步扩展到自动驾驶、机器人等领域。此外,本文的多模态模型让树莓派等设备实际转化为 Rabbit R1 、Humane AI Pin 之类的智能硬件成为可能,它采用终端模型而非基于云的方案。
Functional token 目前已获得授权,研究者鼓励开发者参与本文框架,在遵守许可协议的前提下自由创新。在未来的研究中,研究者旨在开发一个能够容纳音频、视频等额外数据模态的训练框架。此外,研究者发现视觉输入可能带来相当大的延迟,目前正在优化推理速度。
以上是參數量不到10億的OctopusV3,如何媲美GPT-4V和GPT-4?的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















