

語言模型是否會規劃未來 token?這篇論文給你答案。
「別讓 Yann LeCun 看見了。」
Yann LeCun 表示太遲了,他已經看到了。今天要介紹的這篇 「LeCun 非要看」的論文探討的問題是:Transformer 是深謀遠慮的語言模型嗎?當它在某個位置執行推理時,它會預先考慮後面的位置嗎?
這項研究得出的結論是:Transformer 有能力這樣做,但在實踐中不會這樣做。
我們都知道,人類會思考而後言。十年的語言學研究顯示:人類在使用語言時,內心會預測即將出現的語言輸入、單字或句子。
不同於人類,現在的語言模型在「說話」時會為每個 token 分配固定的計算量。那麼我們不禁要問:語言模型會和人類一樣預先性地思考嗎?
根據最近的一些研究已經顯示:可以透過探查語言模型的隱藏狀態來預測下一 token。有趣的是,透過在模型隱藏狀態上使用線性探針,可以在一定程度上預測模型在未來 token 上的輸出,並且可以對未來輸出進行可預測的修改。 近期的一些研究已經表明,可以透過探查語言模型的隱藏狀態來預測下一 token。有趣的是,透過在模型隱藏狀態上使用線性探針,可以在一定程度上預測模型在未來 token 上的輸出,並且可以對未來輸出進行可預測的修改。
這些發現表明在給定時間步驟的模型活化至少在一定程度上可以預測未來輸出。
但是,我們還不清楚原因:這只是資料的偶然屬性,還是因為模型會刻意為未來時間步驟準備資訊(但這會影響模型在目前位置的表現)?
為了解答這個問題,近日科羅拉多大學博爾德分校和康乃爾大學的三位研究者發布了一篇題為《語言模型是否會規劃未來 token? 》的論文。

論文標題:Do Language Models Plan for Future Tokens?
論文地址:https://arxiv.org/pdf/2404.00859.pdf
研究概覽
他們觀察到,在訓練期間的梯度既會為當前token 位置的損失優化權重,也會為該序列後面的token 進行優化。他們又進一步問:目前的 transformer 權重會以怎樣的比例為目前 token 和未來 token 分配資源?
他們考慮了兩種可能性:預先快取假設(pre-caching hypothesis)和麵包屑假設(breadcrumbs hypothesis)。

預先快取假設是指transformer 會在時間步驟t 計算與當前時間步驟的推理任務無關但可能對未來時間步驟t τ 有用的特徵,而麵包屑假設是指與時間步驟t 最相關的特徵已經等同於將在時間步驟t τ 最有用的特徵。
為了評估哪個假設是正確的,團隊提出了一種短視型訓練方案(myopic training scheme),該方案不會將當前位置的損失的梯度傳播給先前位置的隱藏狀態。
上述假設和方案的數學定義和理論描述請參考原文。
實驗結果
為了了解語言模型是否可能直接實現預先緩存,他們設計了一種合成場景,其中只能透過明確的預先緩存完成任務。他們配置了一個任務,其中模型必須為下一 token 預先計算訊息,否則就無法在一次單向通過中準確計算出正確答案。

時定義中所建立的合成資料集定義。
在這個合成場景中,團隊發現了明顯的證據可以說明 transformer 可以學習預先快取。當基於 transformer 的序列模型必須預先計算資訊來最小化損失時,它們就會這樣做。
之後,他們又探究了自然語言模型(預先訓練的 GPT-2 變體)是會展現出麵包屑假設還是會展現出預先緩存假設。他們的短視型訓練方案實驗顯示在這種設定中,預先緩存出現的情況少得多,因此結果更偏向於麵包屑假設。
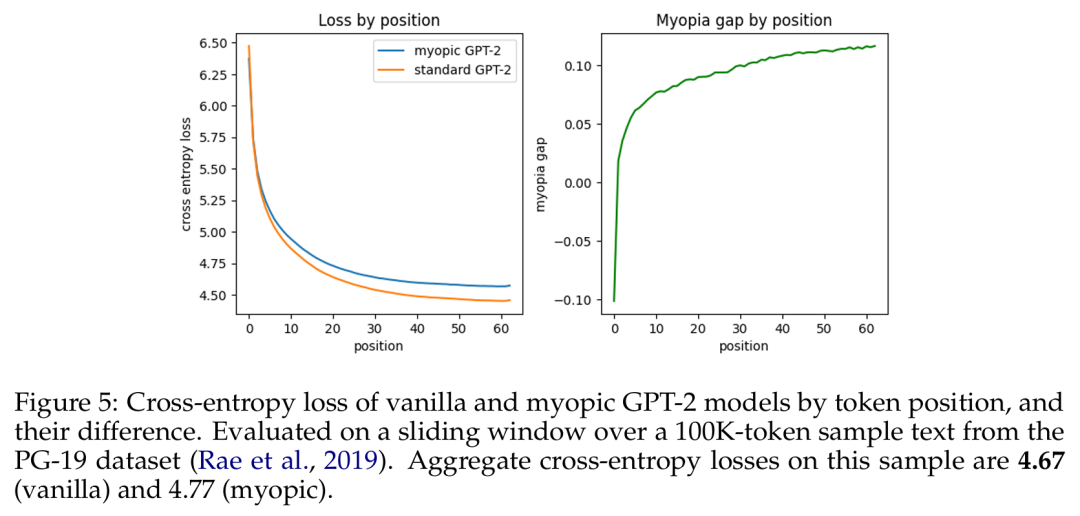
基于 token 位置的原始 GPT-2 模型与短视型 GPT-2 模型的交叉熵损失及其差异。
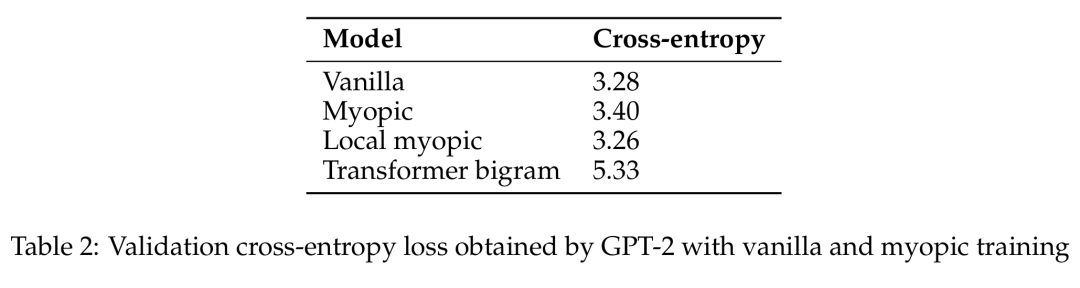
GPT-2 通过原始和短视型训练获得的验证交叉熵损失。
于是该团队声称:在真实语言数据上,语言模型并不会在显著程度上准备用于未来的信息。相反,它们是计算对预测下一个 token 有用的特征 —— 事实证明这对未来的步骤也很有用。
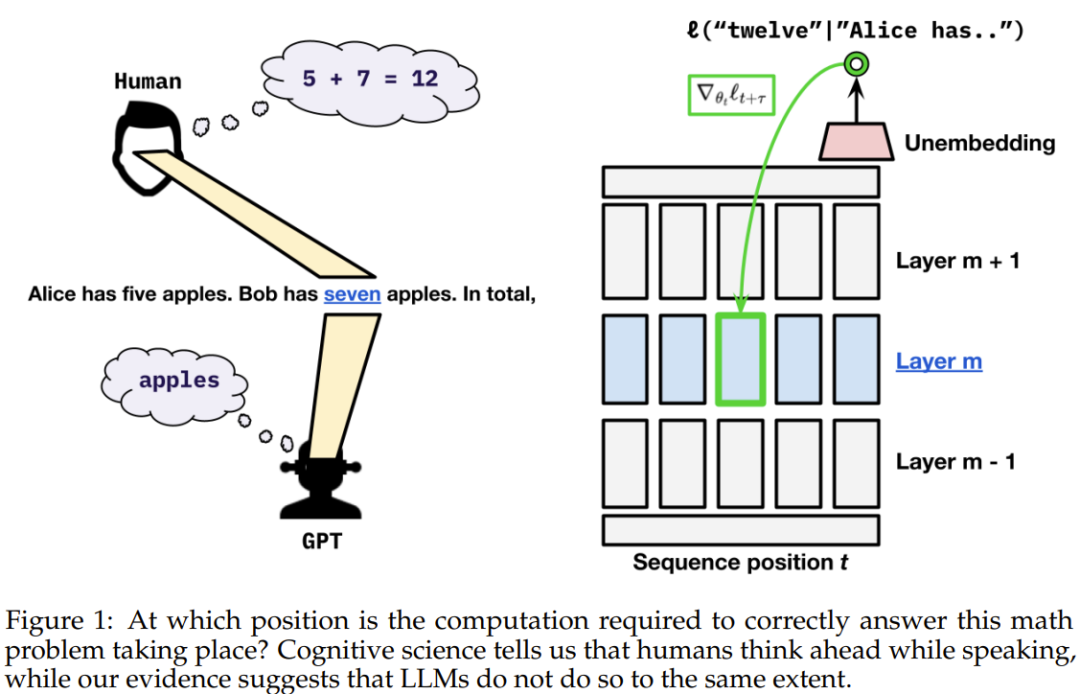
该团队表示:「在语言数据中,我们观察到贪婪地针对下一 token 损失进行优化与确保未来预测性能之间并不存在显著的权衡。」
因此我们大概可以看出来,Transformer 能否深谋远虑的问题似乎本质上是一个数据问题。

可以想象,也许未来我们能通过合适的数据整理方法让语言模型具备人类一样预先思考的能力。
以上是Transformer本來可以深謀遠慮,但就是不做的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















