

编辑|伊风
出品 | 51CTO技术栈(微信号:blog51cto)
谷歌终于出手了!我们将不再忍受大模型的“健忘症”。
TransformerFAM横空出世,放话要让大模型拥有无限记忆力!
话不多说,先来看看TransformerFAM的“疗效”:
 图片
图片
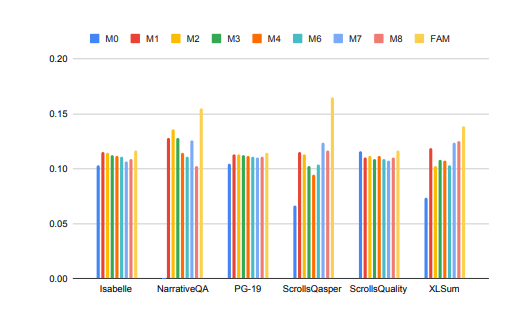
大模型在处理长上下文任务时的性能得到了显著提升!
在上图中,Isabelle、NarrativeQA等任务要求模型理解和处理大量上下文信息,并对特定问题给出准确的回答或摘要。在所有任务中,FAM配置的模型都优于所有其他BSWA配置,并且能够看到当超过某个点时,BSWA记忆段数量的增加已经无法继续提升其记忆能力。
看来,在卷长文本、长对话的路上,FAM这颗大模型的“忘不了”确实有点东西。
Google的研究人员介绍了FAM这种新颖的Transformer架构——Feedback Attention Memory。它利用反馈循环使网络能够关注自身的漂移表现,促进Transformer内部工作记忆的出现,并使其能够处理无限长的序列。
简单点说,这个策略有点像我们人工对抗大模型“失忆”的策略:每次和大模型对话前都再输入一次prompt。只不过FAM的做法更高阶一些,在模型处理新的数据块时,它会将之前处理过的信息(即FAM)作为一个动态更新的上下文,再次整合到当前的处理过程中。
这样就能很好地应对“爱忘事”的问题了。更妙的是,尽管引入了反馈机制来维持长期的工作记忆,但FAM的设计旨在保持与预训练模型的兼容性,不需要额外的权重。所以理论上说,大模型的强大记忆力,没有使其变得迟钝或者消耗更多的算力资源。
那么,这么妙的TransformerFAM是如何被探索出来的?相关技术又是啥?
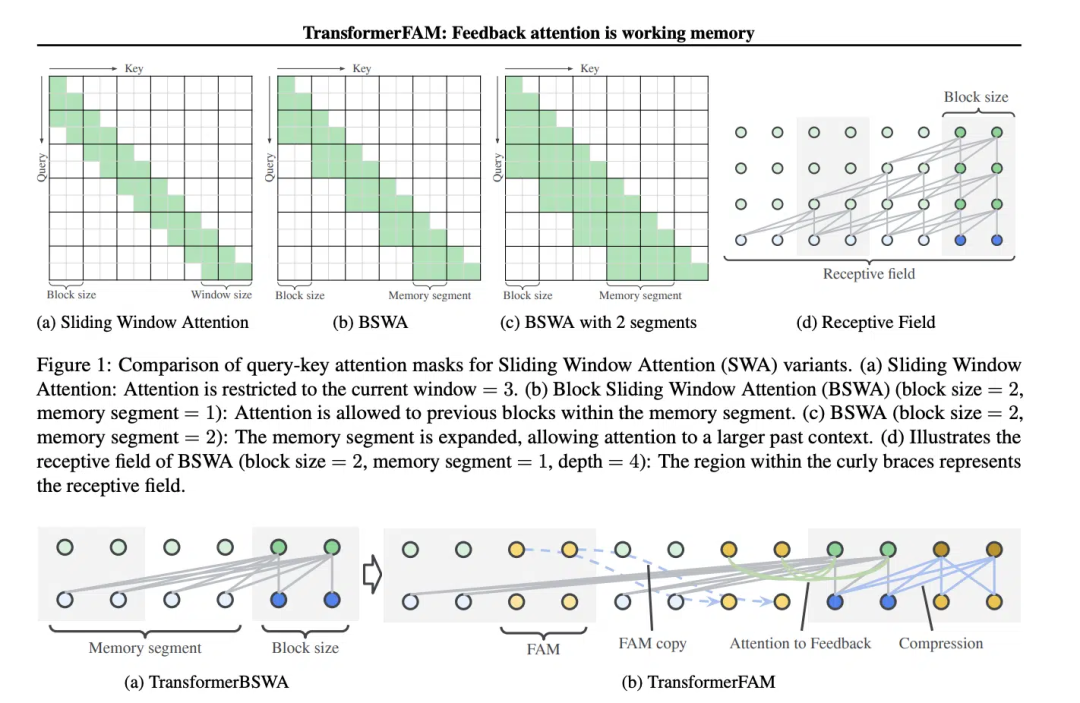
滑动窗口注意力(Sliding Window Attention, SWA)这个概念,对TransformerFAM的设计至关重要。
在传统的Transformer模型中,自注意力(Self-Attention)的复杂度随着序列长度的增加而呈二次方增长,这限制了模型处理长序列的能力。
“在电影《记忆碎片》(2000 年)中,主角患有顺行性遗忘症,这意味着他无法记住过去 10 分钟发生的事情,但他的长期记忆是完好的,他不得不将重要信息纹在身上以记住它们。这与当前大型语言模型(LLMs)的状态类似,”论文中这样写道。
 《记忆碎片》电影截图,图片源于网络
《记忆碎片》电影截图,图片源于网络
滑动窗口注意力(Sliding Window Attention),它是一种改进的注意力机制,用于处理长序列数据。它受到了计算机科学中滑动窗口技术(sliding window technique)的启发。在处理自然语言处理(NLP)任务时,SWA允许模型在每个时间步骤上只关注输入序列的一个固定大小的窗口,而不是整个序列。因此,SWA的优点在于它可以显著减少计算量。
 图片
图片
但是SWA有局限性,因为它的注意力范围受限于窗口大小,这导致模型无法考虑到窗口之外的重要信息。
TransformerFAM通过添加反馈激活,将上下文表示重新输入到滑动窗口注意力的每个区块中,从而实现了集成注意力、区块级更新、信息压缩和全局上下文存储。
在TransformerFAM中,改进通过反馈循环实现。具体来说,模型在处理当前序列块时,不仅关注当前窗口内的元素,还会将之前处理过的上下文信息(即之前的“反馈激活”)作为额外的输入重新引入到注意力机制中。这样,即使模型的注意力窗口在序列上滑动,它也能够保持对之前信息的记忆和理解。
于是,经过这番改进,TransformerFAM就给了LLMs能够处理无限长度序列的潜力!
TransformerFAM has shown positive prospects in research, which will undoubtedly improve AI's ability to understand and generate long text tasks Performance, such as processing document summarization, story generation, Q&A, etc.
 Picture
Picture
At the same time, whether it is an intelligent assistant or an emotional companion, an AI with unlimited memory sounds more attractive.
Interestingly, the design of TransformerFAM is inspired by the memory mechanism in biology, which coincides with the natural intelligence simulation pursued by AGI. This paper is an attempt to integrate a concept from neuroscience—attention-based working memory—into the field of deep learning.
TransformerFAM introduces working memory into large models through feedback loops, allowing the model to not only remember short-term information, but also maintain the memory of key information in long-term sequences.
Through bold imagination, researchers build hypothetical bridges between the real world and abstract concepts. As innovative achievements like TransformerFAM continue to emerge, technological bottlenecks will be broken through again and again, and a more intelligent and interconnected future is slowly unfolding towards us.
To learn more about AIGC, please visit:
51CTO AI.x Community
https://www.51cto.com/aigc/
以上是谷歌出手整頓大模型「健忘症」!回饋注意力機制幫你「更新」上下文,大模型無限記憶力時代將至的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















