大模型與 AI 資料庫雙劍合璧,成為大模型降本增效,大數據真正智慧的致勝法寶。

大模型(LLM)的浪潮已經湧動一年多了,尤其是以GPT-4、Gemini-1.5、Claude-3等為代表的模型你方唱罷我登場,成為當之無愧的風口。在LLM 這條賽道上,有的研究專注於增加模型參數,有的瘋狂捲多模態… 這當中,LLM 處理上下文長度的能力成為了評估模型的一個重要指標,更強的上下文意味著模型擁有更強的檢索效能。例如有些模型一口氣可以處理高達 100 萬 token 的能力讓不少研究者開始思考,RAG (Retrieval-Augmented Generation,檢索增強生成)方法還有存在的必要嗎? 有人認為 RAG 要被長上下文模型殺死了,但這種觀點遭到了許多研究者和架構師的反駁。他們認為一方面資料結構複雜、定期變化,許多資料具有重要的時間維度,這些資料對 LLM 來說可能太複雜。另一方面,企業、產業的海量異質數據,都放到上下文視窗中也不現實。而大模型和 AI 資料庫結合,為生成式 AI 系統注入專業、精準和即時的訊息,大幅降低了幻覺,並提高了系統的實用性。同時,Data-centric LLM 的方法也可以利用 AI 資料庫海量資料管理、查詢的能力,大幅降低大模型訓練、微調的開銷,並支援在系統不同場景的小樣本調優。總結來說,大模型和 AI 資料庫雙劍合璧,既給大模型降本增效,又讓大數據真正實現智能。 RAG 的出現使得LLM 能從大規模的知識庫中精確地抽取訊息,並產生即時、專業、富有洞察力的答案。伴隨而來的是RAG 系統的核心功能向量資料庫也得到了迅速發展,按照向量資料庫的設計概念我們可以將其大致分為三類:專用向量資料庫,關鍵字和向量結合的檢索系統,以及SQL 向量資料庫.
- 以Pinecone/Weaviate/Milvus 為代表的專用向量資料庫,一開始即為向量檢索設計打造,向量檢索性能出色,不過通用的數據管理功能較弱。
- 以Elasticsearch/OpenSearch 為代表的關鍵字與向量檢索系統,因其完善的關鍵字檢索功能而廣泛生產應用,不過系統資源佔用較多,關鍵字與向量的聯合查詢精度和效能不盡人如意。
- 以 pgvector(PostgreSQL 的向量搜尋外掛程式)和 MyScale AI 資料庫為代表的 SQL 向量資料庫,基於 SQL 且資料管理功能強大。不過因為 PostgreSQL 行存的劣勢和向量演算法的局限性,pgvector 在複雜向量查詢中精確度較低。
MyScale AI 資料庫(MyScaleDB)基於高效能的SQL 列式儲存資料庫打造,自研高效能和高資料密度的向量索引演算法,並針對SQL 和向量的聯合查詢對檢索和儲存引擎進行了深度的研發和最佳化,是全球第一個綜合效能和性價比大幅超越了專用向量資料庫的SQL 向量資料庫產品。 得益於SQL 資料庫在海量結構化資料場景長期的打磨,MyScaleDB 同時支援海量向量和結構化資料,包括字串、 JSON、空間、時序等多種資料類型的高效儲存和查詢,並將在近期推出功能強大的倒排表和關鍵字檢索功能,進一步提高RAG 系統的精確度並取代Elasticsearch 等系統。 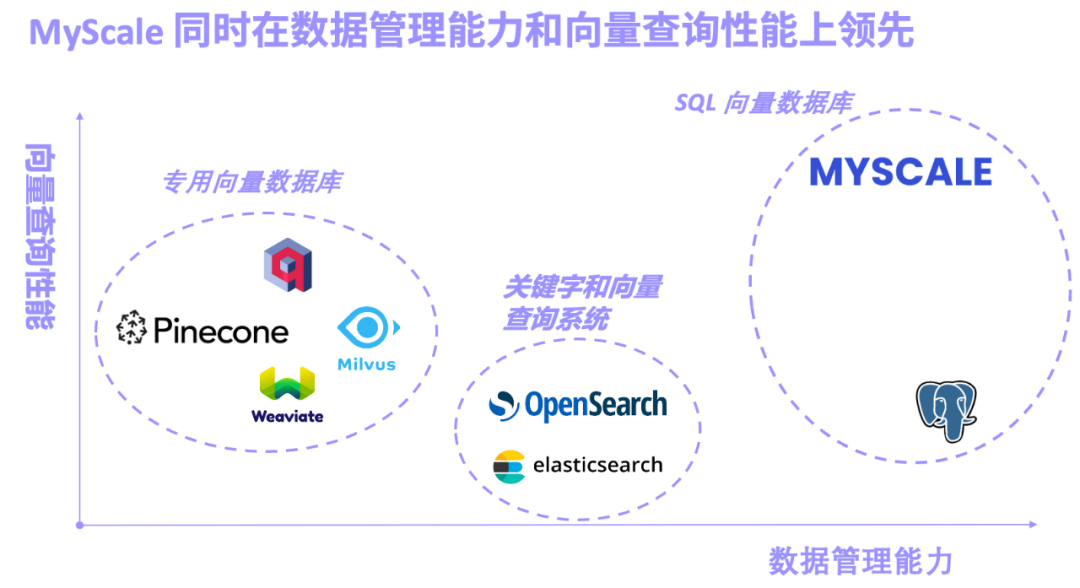
經過近 6 年的開發和數次版本迭代,MyScaleDB 已於近期開源,歡迎所有開發者和企業用戶在 GitHub 上 Star,並開啟使用 SQL 構建生產級 AI 應用的新玩法! 專案網址:https://github.com/myscale/myscaledb借助完善的SQL 資料管理能力,強大且有效率的結構化、向量和異質資料儲存和查詢能力,MyScaleDB 有望成為第一款真正面向大模型和大數據的AI 資料庫。 #自從SQL 誕生半個世紀以來,儘管其中經歷了NoSQL、大數據等浪潮,不斷進化的SQL 資料庫還是佔據了資料管理市場主要份額,甚至Elasticsearch、Spark 等檢索和大數據系統也陸續支援了SQL 介面。而專用的向量資料庫儘管為向量做了最佳化和系統設計,但其查詢介面通常缺乏規範性,沒有高階的查詢語言。這導致了介面的泛化能力較弱,例如 Pinecone 的查詢介面甚至不包括指定要檢索的字段,更不用說分頁、聚合等資料庫常見的功能。 介面的泛化能力弱意味著其變化頻繁,增加了學習成本。 MyScale 團隊則認為,經過系統性最佳化的SQL 和向量系統是可以既保持完整的SQL 支持,又保證向量檢索高效能的,而他們的開源評測的結果已經充分論證了這一點。 在實際複雜 AI 應用場景中,SQL 和向量結合可以大幅增加資料建模的靈活性,並簡化開發流程。例如MyScale 團隊與北京科學智能研究院合作的Science Navigator 專案中,利用MyScaleDB 對於海量的科學文獻資料做檢索和智慧問答,其主要的SQL 表結構就有10 多個,其中多張表結構建立了向量和倒排表索引,並利用主鍵和外鍵做了關聯。系統在實際查詢中,也會涉及結構化、向量和關鍵字資料的共同查詢,以及幾張表格的關聯查詢。在專用的向量資料庫中這些建模和關聯是難以實現的,也會導致最終的系統迭代緩慢、查詢低效和維護困難。 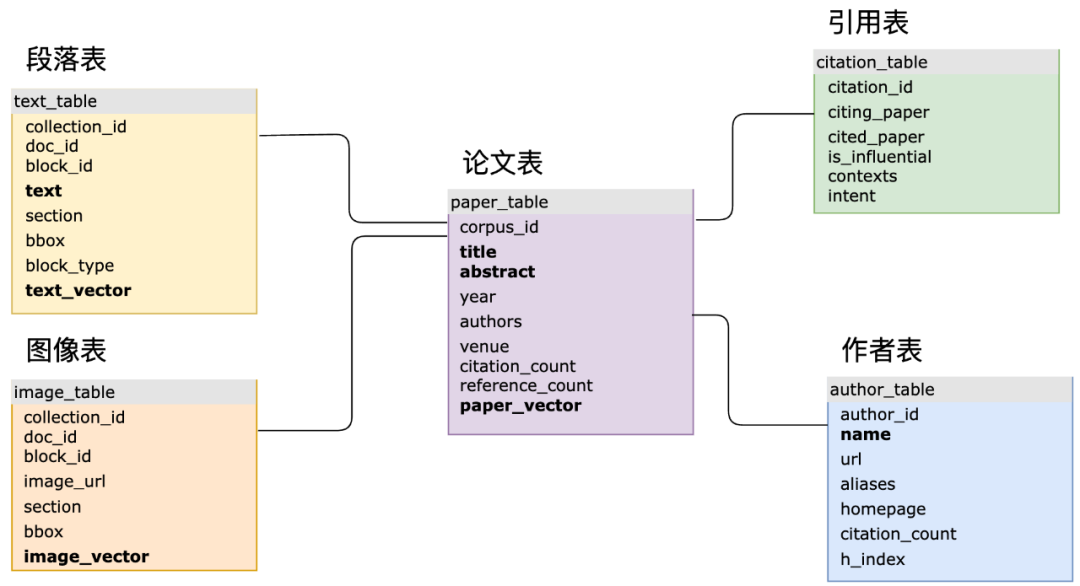
Science Navigator 主表結構示意圖(加粗體的列建立了向量索引或倒排索引)# #支援結構化、向量和關鍵字等資料聯合查詢在實際RAG 系統中,檢索的精確度和效果是限制其落地的主要瓶頸。這需要 AI 資料庫高效支援結構化、向量和關鍵字等資料聯合查詢,綜合提高檢索精確度。 例如在金融場景中,使用者需要針對文件庫查詢“某公司2023 年全球各項業務的收入情況如何?”,“某公司”,“2023年” 等結構化元資訊並不能被向量很好的抓取,甚至不一定在對應的段落中有直接的體現。直接在全庫上執行向量檢索會得到大量的干擾訊息,並降低系統最終的準確性。另一方面,公司名稱,年份等通常是可以作為文檔的元資訊被獲取的,我們可以將WHERE year=2023 AND company ILIKE "%
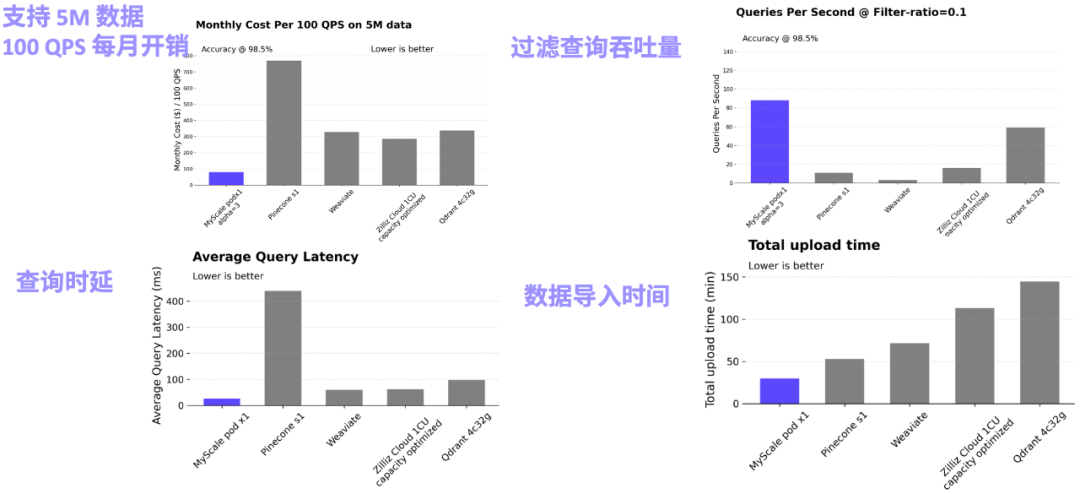
%" 作為向量查詢的過濾條件,從而精準的定位到相關訊息,大幅提升了系統的可靠性。在金融、製造業、科學研究等場景中,MyScale 團隊都觀察到異質資料建模和關聯查詢的威力,許多場景下甚至有 精確度到 儘管傳統的資料庫產品都已經陸續意識到了向量查詢在AI 時代的重要性,並開始在資料庫中增加向量能力,其聯合查詢的精確度仍然存在顯著的問題。例如,在過濾查詢的場景下,Elasticsearch 在過濾比例為0.1 時,QPS 會降到只有5 左右,而PostgresSQL(使用pgvector 插件)在過濾比例是0.01 時,檢索精度只有50% 左右,不穩定的查詢精度/ 性能極大限制了其應用的場景。而 MyScale 只使用了 pgvector 36% 的成本和 ElasticSearch 12% 的成本,就能夠在各種不同過濾比例的場景下都實現高效能和高精度 在不同過濾比例場景下,MyScale 都用低成本實現了高精度和高性能查詢正因為向量檢索在大模型應用中的重要性和高關注度,越來越多的團隊投入了向量資料庫這個賽道。大家一開始的關注點都是努力提升純向量搜尋場景下的 QPS,但純向量搜尋是遠遠不夠的!在實戰的場景中,資料建模、查詢的靈活性和精準度以及平衡資料密度、查詢效能和成本是更重要的議題。 在RAG 場景中,純向量查詢效能有10x 的過剩,向量佔用資源龐大,聯合查詢功能缺乏、效能和精確度不佳往往是當下專有向量資料庫的常態。 MyScaleDB 致力於在真實海量資料場景下AI 資料庫的綜合效能提升,其推出的MyScale Vector Database Benchmark 也是業界首個在五百萬向量規模,不同查詢情境下比較主流向量資料庫系統綜合性能、性價比的開源評測系統,歡迎大家來追蹤和提issue。 MyScale 團隊表示,AI 資料庫在真實應用場景下還存在著很大的優化空間,他們也希望在實踐中不斷打磨產品並完善評測系統。 MyScale Vector Database Benchmark 專案位址:https://github.com/myscale/vector-db-benchmark#展望:AI 資料庫支撐的大模型大數據Agent 平台機器學習大數據驅動了互聯網和上一代資訊系統的成功,而在大模型的時代背景下,MyScale 團隊也致力於提出新一代的大模型大數據方案。以高效能的SQL 向量資料庫為堅實的支撐,MyScaleDB 提供了大規模資料處理、知識查詢、可觀測性、資料分析和小樣本學習的關鍵能力,建構了AI 和資料閉環,成為下一代大模型大數據Agent 平台的關鍵基座。 MyScale 團隊已經在科學研究、金融、工業、醫療等領域探索這套方案的落地。 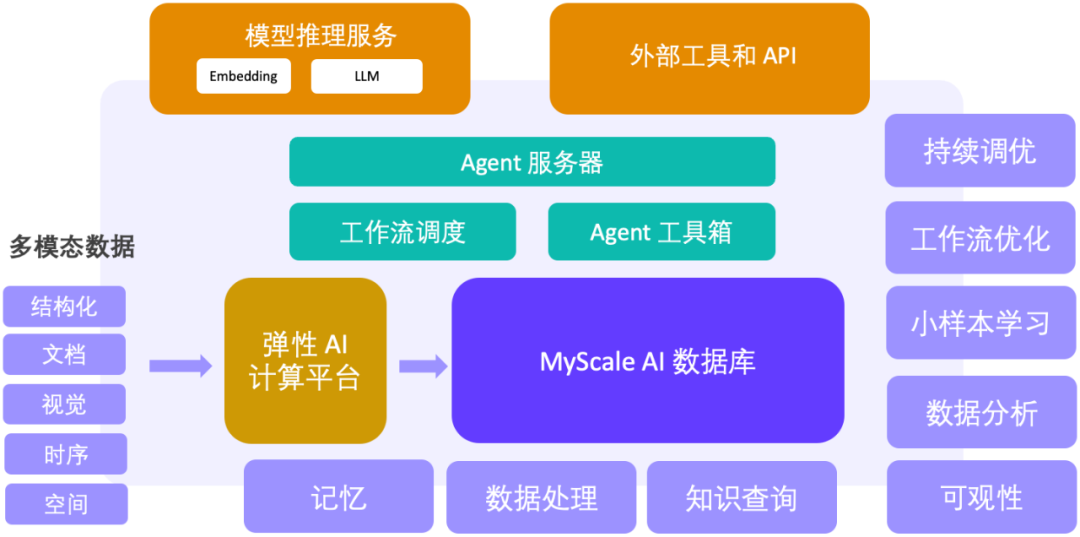
隨著科技的快速發展,某種意義上的通用人工智慧 (AGI) 有望在未來 5-10 年內出現。關於這個問題,我們不禁要思考:是需要一個靜態、虛擬且與人類競爭的大模型,還是其他更全面的解決方案?數據無疑是連結大模型、世界與使用者的重要紐帶,MyScale 團隊的願景是將大模型和大數據有機結合,打造更專業、即時、高效協作,同時也充滿人性溫度和價值的 AI 系統。 以上是長文本殺不死RAG:SQL+向量驅動大模型與大數據新範式,MyScale AI資料庫正式開源的詳細內容。更多資訊請關注PHP中文網其他相關文章!




































