


3 月28 日消息,根據LMSYS Org 公佈的最新基準測試報告,Claude-3 得分以微弱優勢超越GPT-4,成為該平台“最佳”大語言模型。
本網站首先介紹下LMSYS Org,該機構是由加州大學柏克萊分校、加州大學聖地牙哥分校和卡內基美隆大學合作創建的研究組織。
該系統推出Chatbot Arena,這是一個針對大型語言模型(LLM)的基準平台,以眾包方式匿名、隨機對抗測試大模型產品,其評級基於國際象棋等競技遊戲中廣泛使用的Elo評分系統。
透過用戶投票產生的評分結果,系統每次都會隨機選擇兩個不同的大模型機器人和用戶聊天,並讓用戶在匿名的情況下選擇哪款大模型產品的表現更好一些,整體而言相對公正。
Chatbot Arena 自去年上線以來,GPT-4 一直穩居頭把交椅,甚至成為了評估大模型的黃金標準。
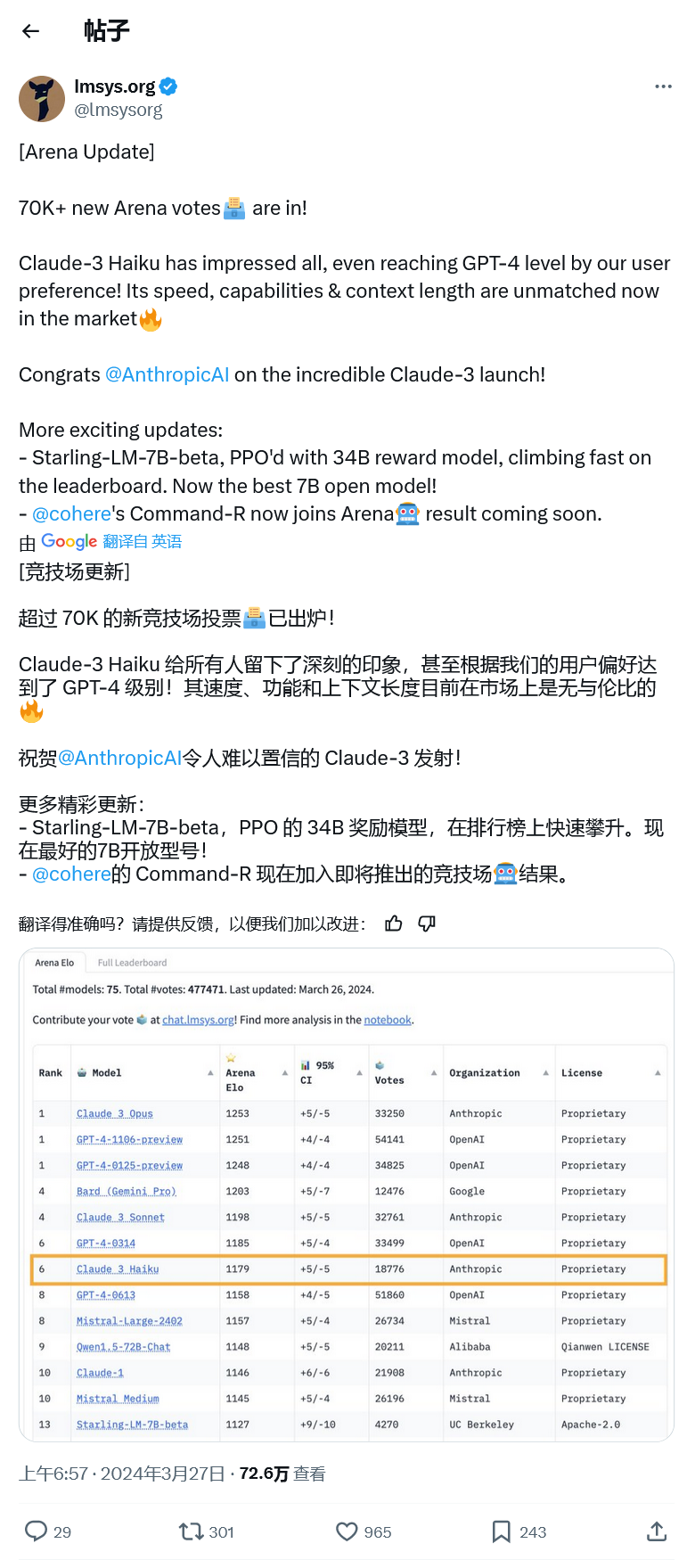
不過昨天 Anthropic 的 Claude 3 Opus 以 1253 比 1251 的微弱優勢擊敗了 GPT-4,OpenAI 的 LLM 被擠下了榜首位置。由於比分過於接近,出於誤差率的考量,該機構讓 Claude 3 和 GPT-4 並列第一,GPT-4 的另一個預覽版也並列第一。
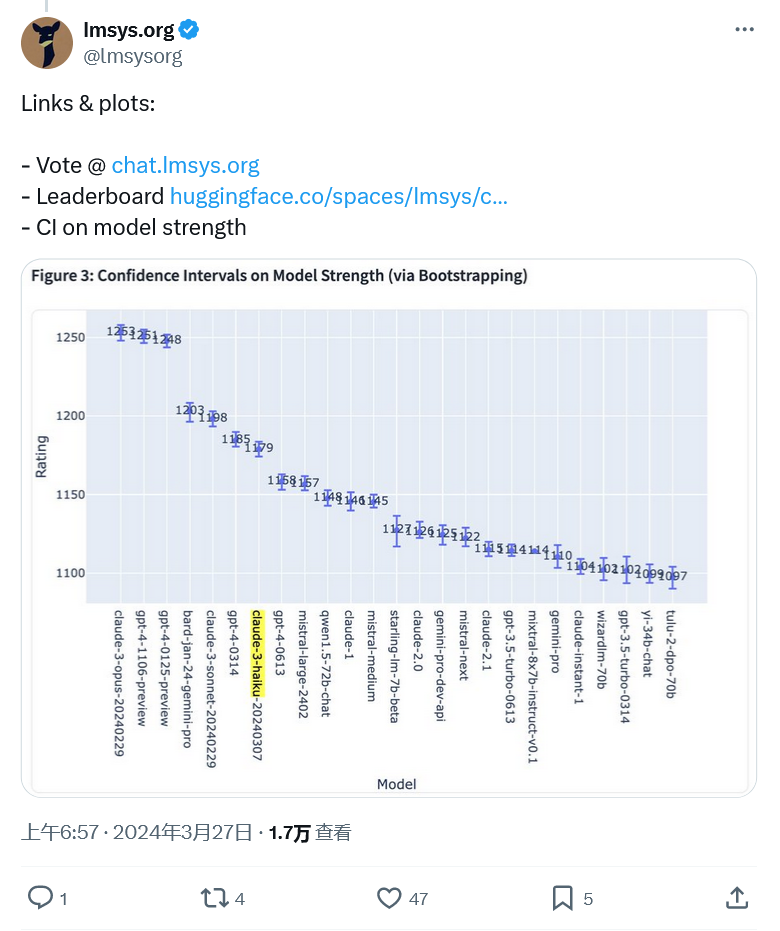
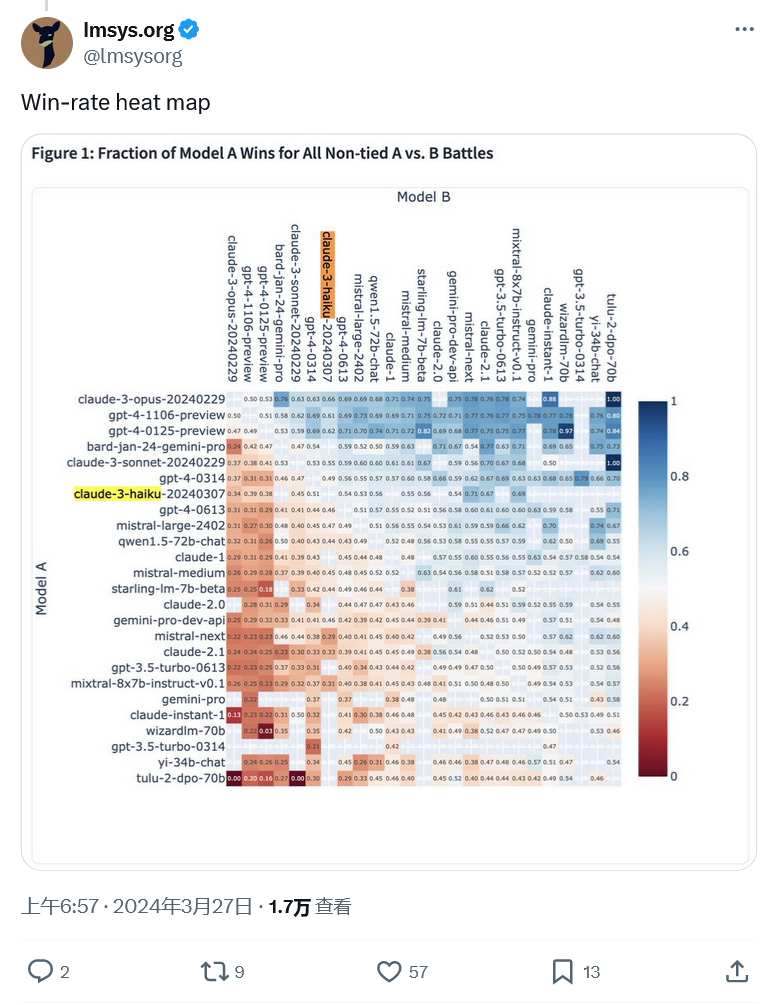
更令人印象深刻的是 Claude 3 Haiku 進入前十名。 Haiku 是 Anthropic 的 local size 模型,相當於Google的 Gemini Nano。
它比擁有數萬億參數的 Opus 要小得多,因此相比之下速度要快得多。根據 LMSYS 的數據,Haiku 在排行榜上名列第七,有媲美 GPT-4 的表現。
以上是和 GPT-4 並列第一,LMSYS 基準測試顯示 Claude-3 模型表現優異的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















