

CLIP stands for Contrastive Language-Image Pre-training, which is a pre-training method or model based on contrastive text-image pairs. It is a multimodal model that relies on contrastive ling . consists of text-image pairs, where an image is paired with its corresponding text description. Through contrastive learning, the model aims to understand the relationship between text and image p#s.
Open AI在2021年1月發布了DALL-E和CLIP,這兩個模型都是多模態模型,能夠結合圖像和文字。 DALL-E是一種基於文字生成圖像的模型,而CLIP則是利用文字作為監督訊號來訓練可遷移的視覺模型。 
在Stable Diffusion模型中,透過cross attention將CLIP文字編碼器擷取的文字特徵嵌入擴散模型的UNet中。具體來說,文本特徵被用作attention的key和value,而UNet的特徵則被用作query。換句話說,CLIP實際上是將文字和圖片之間建立連接的關鍵橋樑,將文字訊息與圖像訊息有機地結合。這種結合方式使得模型能夠更好地理解和處理不同模態之間的訊息,從而在處理複雜任務時取得更好的效果。透過這種方式,Stable Diffusion模型能夠更有效地利用CLIP的文字編碼能力,進而提升整體效能並拓展應用領域。
CLIP
#這是OpenAI21年最早發布的論文,要理解CLIP,我們需要將縮寫解構為三個組成部分:(1)Contrastive ,(2)Language-Image,(3)Pre-training。 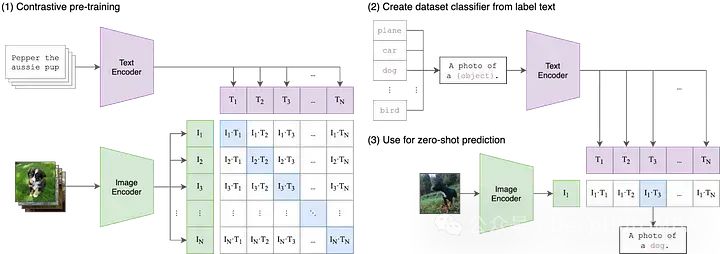
我們先從Language-Image開始。
在傳統機器學習模型中,通常只能接受單一模態的輸入數據,例如文字、圖像、表格數據或音訊。如果需要使用不同模態的資料來進行預測,就必須訓練多個不同的模型。而在CLIP中,「Language-Image」表示模型可以同時接受文字(語言)和圖像兩種類型的輸入資料。這種設計使得CLIP能夠更靈活地處理不同模態的訊息,從而提高了其預測能力和應用範圍。CLIP透過使用兩個不同的編碼器處理文字和圖像輸入,分別是文字編碼器和圖像編碼器。這兩個編碼器將輸入資料映射到較低維度的潛在空間中,為每個輸入產生相應的嵌入向量。一個重要的細節是,文字和圖像編碼器將資料嵌入到相同的空間中,即原始的CLIP空間是一個512維向量空間。這種設計使得文字和圖像之間可以進行直接的比較和匹配,無需額外的轉換或處理。這樣一來,CLIP可以在同一個向量空間中表示文字描述和圖像內容,從而實現了跨模態的語義對齊和檢索功能。這種共享的嵌入空間的設計使得CLIP具有更好的泛化能力和適應性,使其能夠在各種任務和資料集上表現出色。
雖然將文字和圖像資料嵌入到同一向量空間可能是一個有用的起點,但僅僅做到這一點並不能確保模型能夠有效地比較文字和圖像的表示。舉例來說,建立文本中「狗」或「一張狗的照片」的嵌入與狗圖像的嵌入之間的合理且可解釋的關係是很重要的。然而,我們需要一種方法來彌合這兩種模式之間的差距。
在多模態機器學習中,有各種各樣的技術來對齊兩個模態,但目前最流行的方法是對比。對比技術從兩種模式中獲取成對的輸入:例如一張圖像和它的標題並訓練模型的兩個編碼器盡可能接近地表示這些輸入的資料對。同時,該模型被激勵去接受不配對的輸入(如狗的圖像和“汽車的照片”的文本),並儘可能遠地表示它們。 CLIP並不是第一個圖像和文字的對比學習技術,但它的簡單性和有效性使其成為多模式應用的支柱。
Pre-training
#雖然CLIP本身對於零樣本分類、語意搜尋和無監督資料探索等應用程式很有用,但CLIP也被用作大量多模式應用程式的構建塊,從Stable Diffusion和DALL-E到StyleCLIP和OWL-ViT。對於大多數這些下游應用程序,初始CLIP模型被視為「預訓練」的起點,整個模型針對其新用例進行微調。
雖然OpenAI從未明確指定或共享用於訓練原始CLIP模型的數據,但CLIP論文提到該模型是在從互聯網收集的4億對圖像-文本上進行訓練的。
//m.sbmmt.com/link/7c1bbdaebec5e20e91db1fe61221228f

#使用CLIP, OpenAI使用了4億對圖像-文本,因為沒有提供細節,所以我們不可能確切地知道如何建立資料集。但在描述新的資料集時,他們參考了Google的Google's Conceptual Captions 作為靈感——一個相對較小的資料集(330萬個影像描述對,這個資料集使用了昂貴的過濾和後處理技術,雖然這些技術很強大,但不是特別可擴展)。
所以高品質的資料集就成為了研究的方向,在CLIP之後不久,ALIGN透過規模過濾來解決這個問題。 ALIGN不依賴小的、精心標註的、精心策劃的圖像字幕資料集,而是利用了18億對圖像和替代文字。
雖然這些替代文字描述平均而言比標題雜訊大得多,但資料集的絕對規模足以彌補這一點。作者使用基本的過濾來去除重複的,有1000多個相關的替代文本的圖像,以及沒有信息的替代文本(要么太常見,要么包含罕見的標記)。透過這些簡單的步驟,ALIGN在各種零樣本和微調任務上達到或超過了當時最先進的水平。
https://arxiv.org/abs/2102.05918

#與ALIGN一樣,K-LITE也在解決用於對比預訓練的高品質圖像-文字對數量有限的問題。
K-LITE專注於解釋概念,即將定義或描述作為上下文以及未知概念可以幫助發展廣義理解。一個通俗的解釋就是人們第一次介紹專業術語和不常用詞彙時,他們通常會簡單地定義它們!或者使用一個大家都知道的事物作為類比。
為了實現這種方法,微軟和加州大學柏克萊分校的研究人員使用WordNet和維基字典來增強圖像-文字對中的文字。對於一些孤立的概念,例如ImageNet中的類別標籤,概念本身被增強,而對於標題(例如來自GCC),最不常見的名詞短語被增強。透過這些額外的結構化知識,對比預訓練模型在遷移學習任務上表現出實質的改進。
https://arxiv.org/abs/2204.09222
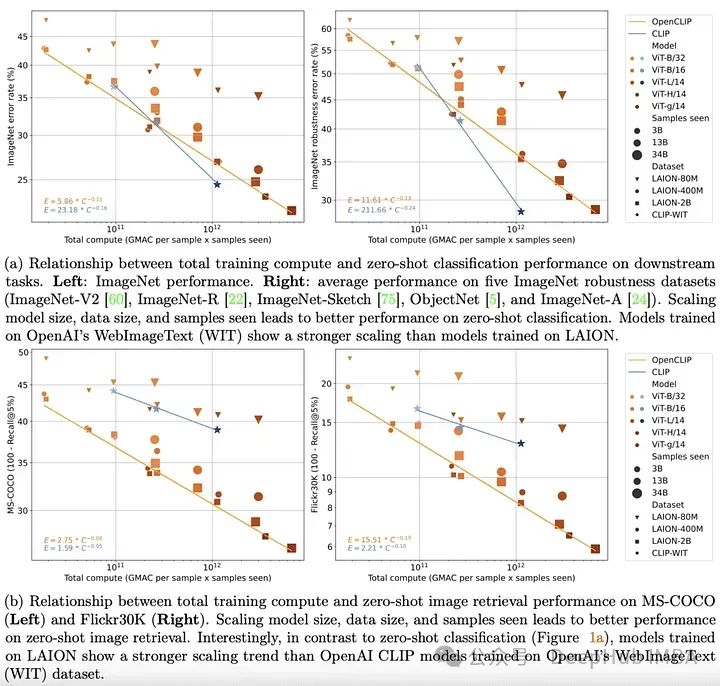
#############################################################################################################################1 ###########到2022年底,transformer 模型已經在文字和視覺領域建立起來。在這兩個領域的開創性經驗工作也清楚地表明,transformer 模型在單峰任務上的表現可以透過簡單的縮放定律來很好地描述。也就是說隨著訓練資料量、訓練時間或模型大小的增加,人們可以相當準確地預測模型的表現。 ############OpenCLIP透過使用迄今為止發布的最大的開源圖像-文字對資料集(5B)將上面的理論擴展到多模式場景,系統地研究了訓練資料對模型在零樣本和微調任務中的表現的影響。與單模態情況一樣,該研究揭示了模型在多模態任務上的性能在計算、所見樣本和模型參數數量方面按冪律縮放。 ############比冪律的存在更有趣的是冪律縮放和預訓練資料之間的關係。保留OpenAI的CLIP模型架構和訓練方法,OpenCLIP模型在樣本影像檢索任務上表現出更強的縮放能力。對於ImageNet上的零樣本影像分類,OpenAI的模型(在其專有資料集上訓練)表現出更強的縮放能###力。這些發現突顯了資料收集和過濾程式對下游效能的重要性。 ######https://arxiv.org/abs/2212.07143#########但是在OpenCLIP發布不久,LAION資料集因包含非法圖像已從互聯網上被下架了。 ############MetaCLIP: Demystifying CLIP Data#####################OpenCLIP試圖理解下游任務的效能如何隨資料量、計算量和模型參數數量的變化而變化,而MetaCLIP關注的是如何選擇資料。正如作者所說,「我們認為CLIP成功的主要因素是它的數據,而不是模型架構或預訓練目標。」######
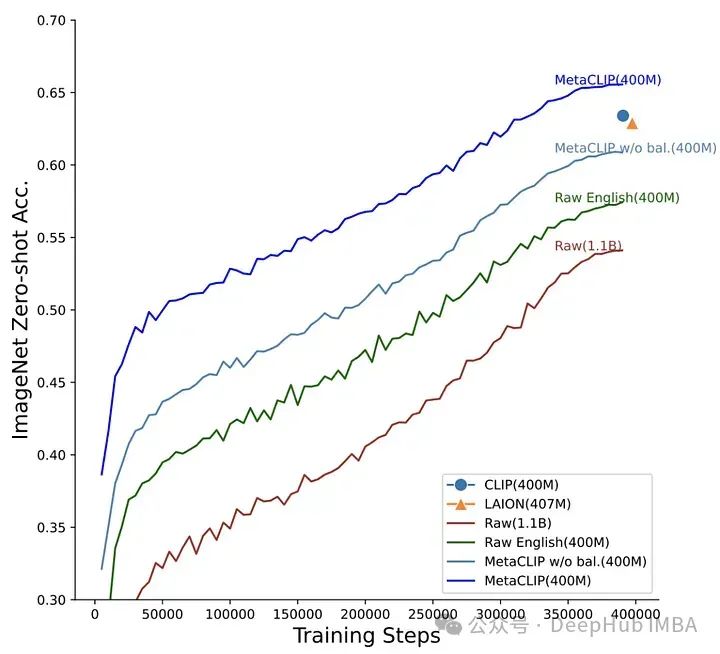
為了驗證這個假設,作者固定了模型架構和訓練步驟並進行了實驗。 MetaCLIP團隊測試了與子字串匹配、過濾和平衡資料分佈相關的多種策略,發現當每個文本在訓練資料集中最多出現20,000次時,可以實現最佳性能,為了驗證這個理論他們甚至將在初始資料池中出現5,400萬次的單字「photo」在訓練資料中也被限制為20,000對圖像-文字。使用這種策略,MetaCLIP在來自Common Crawl資料集的400M圖像-文字對上進行了訓練,在各種基準測試中表現優於OpenAI的CLIP模型。
https://arxiv.org/abs/2309.16671
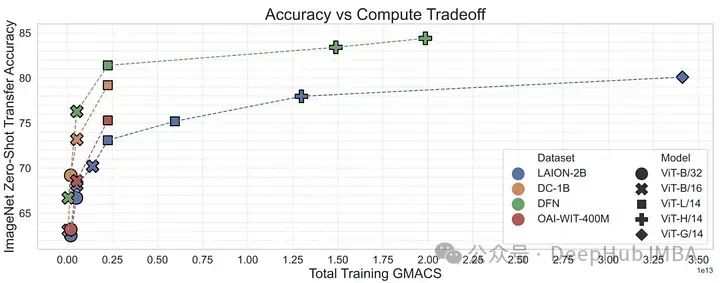
#有了MetaCLIP的研究,可以說明資料管理可能是訓練高性能多模態模型(如CLIP)的最重要因素。 MetaCLIP的過濾策略非常成功,但它也主要基於啟發式的方法。研究人員將研究目標變成是否可以訓練一個模型來更有效地進行這種過濾。
為了驗證這一點,作者使用來自概念性12M的高品質資料來訓練CLIP模型,從低品質資料中過濾高品質資料。這個資料過濾網路(DFN)被用來建構一個更大的高品質資料集,方法是只從一個未經管理的資料集(在本例中是Common Crawl)中選擇高品質資料。在過濾後的資料上訓練的CLIP模型優於僅在初始高品質資料上訓練的模型和在大量未過濾資料上訓練的模型。
https://arxiv.org/abs/2309.17425
OpenAI的CLIP模型顯著地改變了我們處理多模態資料的方式。但是CLIP只是一個開始。從預訓練資料到訓練方法和對比損失函數的細節,CLIP家族在過去幾年中取得了令人難以置信的進步。 ALIGN縮放雜訊文本,K-LITE增強外部知識,OpenCLIP研究縮放定律,MetaCLIP最佳化資料管理,DFN增強資料品質。這些模型加深了我們對CLIP在多模態人工智慧發展中的作用的理解,展示了在連接圖像和文字方面的進步。
以上是文生圖的基石CLIP模型的發展綜述的詳細內容。更多資訊請關注PHP中文網其他相關文章!


































