

大语言模型(Large Language Models, LLMs)在过去两年内迅速发展,涌现出一些现象级的模型和产品,如 GPT-4、Gemini、Claude 等,但大多数是闭源的。研究界目前能接触到的大部分开源 LLMs 与闭源 LLMs 存在较大差距,因此提升开源 LLMs 及其他小模型的能力以减小其与闭源大模型的差距成为了该领域的研究热点。
LLM 的强大能力,特别是闭源 LLM,使得科研人员和工业界的从业者在训练自己的模型时都会利用到这些大模型的输出和知识。这一过程本质上是知识蒸馏(Knowledge, Distillation, KD)的过程,即从教师模型(如 GPT-4)中蒸馏知识到较小的模型(如 Llama)中,显著提升了小模型的能力。可以看出,大语言模型的知识蒸馏技术无处不在,且对于研究人员来说是一种性价比高、有效的方法,有助于训练和提升自己的模型。
那么,当前的工作如何利用闭源 LLM 进行知识蒸馏和获取数据?如何有效地将这些知识训练到小模型中?小模型能够获取教师模型的哪些强大技能?在具有领域特点的工业界,LLM 的知识蒸馏如何发挥作用?这些问题值得深入思考和研究。
在 2020 年,陶大程团队发表了《Knowledge Distillation: A Survey》,全面探讨了知识蒸馏在深度学习中的应用。该技术主要用于模型的压缩和加速。随着大型语言模型的兴起,知识蒸馏的应用领域得到了不断拓展,不仅能够提升小型模型的性能,还能实现模型自我提升。
2024 年初,陶大程团队与香港大学和马里兰大学等合作,发表了最新综述《A Survey on Knowledge Distillation of Large Language Models》,总结了 374 篇相关工作,探讨了如何从大语言模型中获取知识,训练较小模型,以及知识蒸馏在模型压缩和自我训练中的作用。同时,该综述也涵盖了对大语言模型技能的蒸馏以及垂直领域的蒸馏,帮助研究者全面了解如何训练和提升自己的模型。

论文题目:A Survey on Knowledge Distillation of Large Language Models
论文链接:https://arxiv.org/abs/2402.13116
项目链接:https://github.com/Tebmer/Awesome-Knowledge-Distillation-of-LLMs
综述架构
大语言模型知识蒸馏的整体框架总结如下图所示:
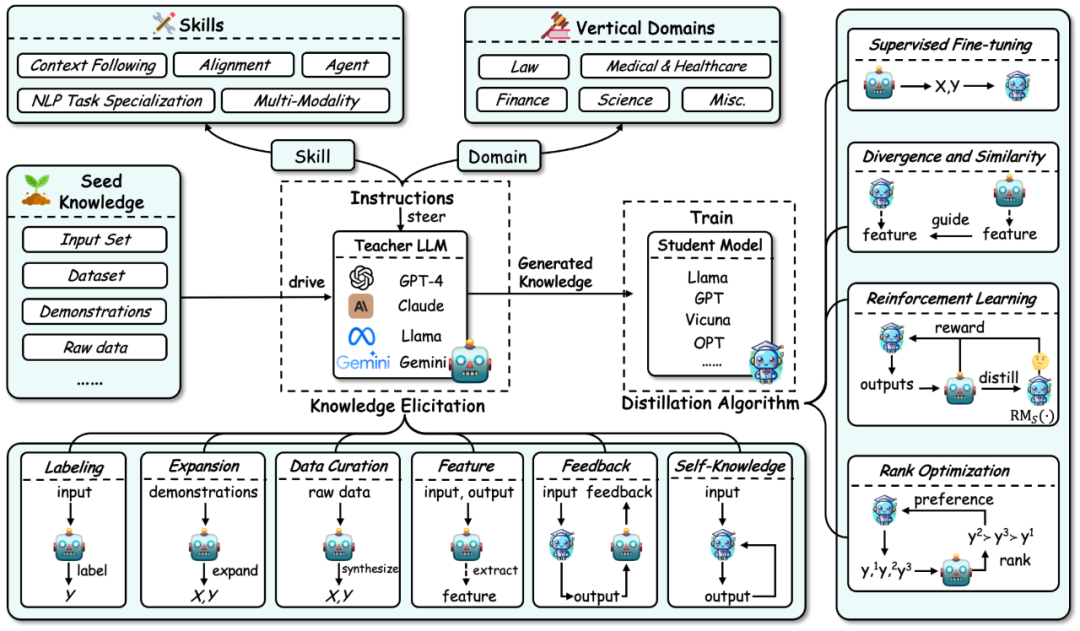
首先,根据大语言模型知识蒸馏的流程,该综述将知识蒸馏分解为了两个步骤:
1. 知识获取(Knowledge Elicitation):即如何从教师模型中获取知识。其过程主要包括:
a) 首先构建指令来确定要从教师模型中蒸馏的技能或垂直领域的能力。
b) 然后使用种子知识(如某个数据集)作为输入来驱动教师模型,生成对应的回应,从而将相应的知识引导出来。
c) 同时,知识的获取包含一些具体技术:标注、扩展、合成、抽取特征、反馈、自身知识。
2. 蒸馏算法(Distillation Algorithms):即如何将获取的知识注入到学生模型中。该部分具体算法包括:有监督微调、散度及相似度、强化学习(即来自 AI 反馈的强化学习,RLAIF)、排序优化。
此綜述的分類方法根據此過程,將相關工作從三個維度進行了總結:知識蒸餾的演算法、技能蒸餾、以及垂直領域的蒸餾。後兩者都基於知識蒸餾演算法來進行蒸餾。此分類的細節以及對應的相關工作總結如下圖所示。
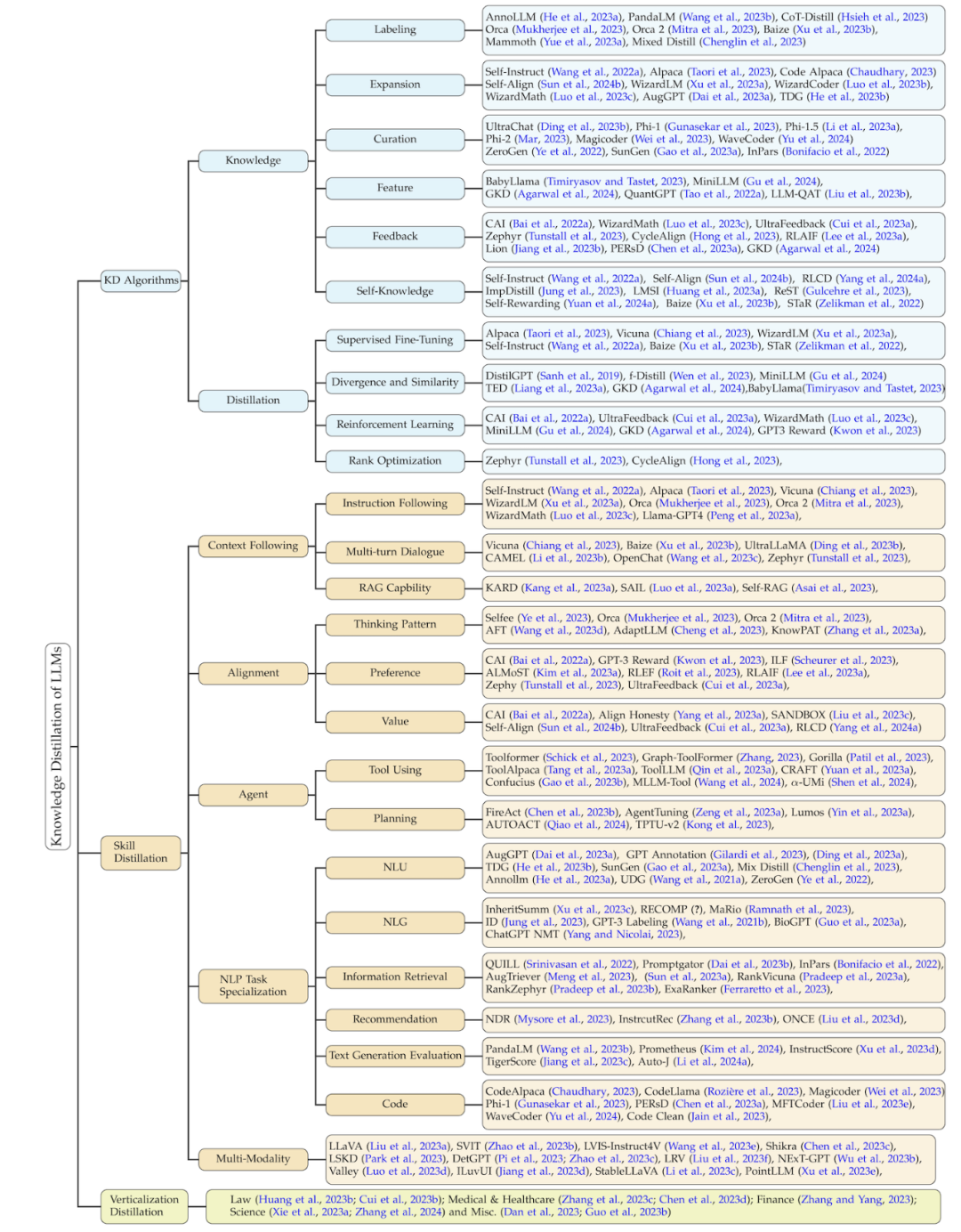
知識蒸餾演算法
#知識獲取(Knowledge Elicitation)
根據從教師模型中獲取知識的方式,此綜述將其技術分為標註(Labeling)、擴展(Expansion)、資料合成(Data Curation)、特徵抽取(Feature)、回饋(Feedback)、自生成的知識(Self- Knowledge)。每個方式的範例如下圖所示:
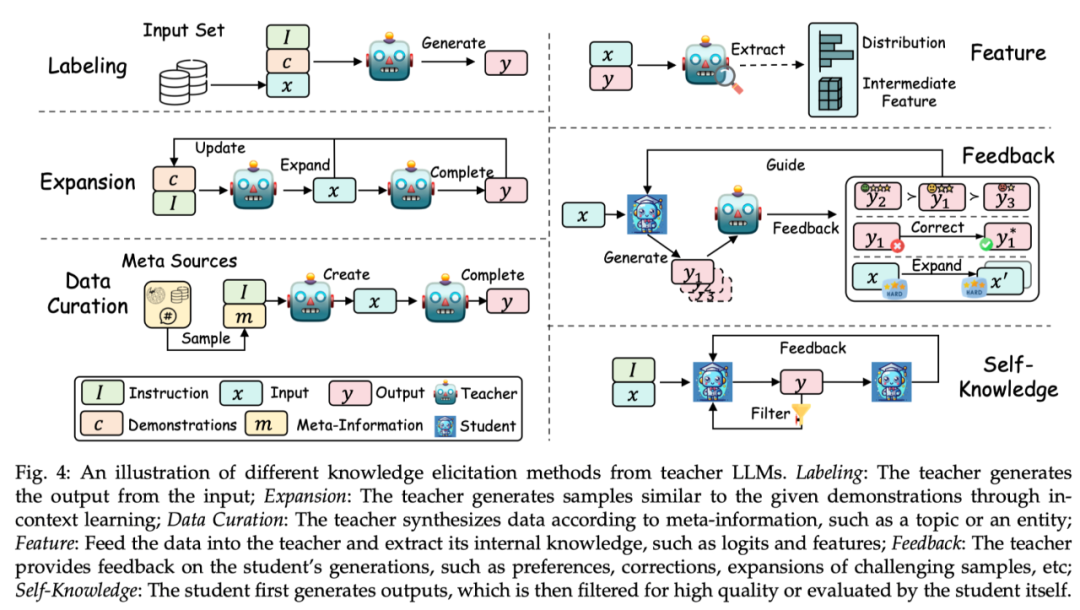
標註(Labeling):知識標註是指由教師LLMs 根據指令或範例,對給定的輸入作為種子知識,產生對應的輸出。例如,種子知識為某一個資料集的輸入,教師模型標註思維鏈輸出。
擴充(Expansion):此技術的關鍵特徵是利用 LLMs 的上下文學習能力,根據提供的種子範例,來產生與範例相似的資料。其優點在於透過範例能產生更加多樣化和廣泛的資料集。但是隨著產生資料的持續增大,可能會造成資料同質化問題。
資料合成(Data Curation):資料合成的一個顯著特徵是其從零開始合成資料。其利用大量且多樣的元資訊(如主題、知文件、原始資料等)來作為多樣且巨量的種子知識,以從教師 LLMs 中獲取規模龐大且品質高的資料集。
特徵獲取(Feature):獲取特徵知識的典型方法主要為將輸入輸出序列輸出到教師 LLMs 中,然後抽取其內部表示。此方式主要適用於開源的 LLMs,常用於模型壓縮。
回饋(Feedback):回饋知識通常為教師模型對學生的輸出提供回饋,例如提供偏好、評估或修正資訊來指導學生產生更好輸出。
自生成知識(Self-Knowledge):知識也可以從學生本身獲取,稱之為自生成知識。在這種情況下,同一個模型既充當教師又充當學生,透過蒸餾技術以及改進自己先前生成的輸出來迭代地改進自己。該方式非常適用於開源 LLMs。
總結:目前,擴展方法仍然被廣泛應用,資料合成方式因為能夠產生大量高品質的資料而逐漸成為主流。回饋方法能夠提供有利於學生模型提升對齊能力的知識。特徵獲取和自生成知識的方式因為將開源大模型作為教師模型而變得流行。特徵獲取方式有助於壓縮開源模型,而自生成知識的方式能夠持續提升大語言模型。重要的是,以上方法可以有效地組合,研究人員可以探索不同方式的組合來引導出更有效的知識。
蒸餾演算法(Distilling Algorithms)
在取得知識之後,就需要將知識蒸餾到學生模型中。蒸餾的演算法有:有監督微調、散度及相似度、強化學習,以及排序最佳化。範例如下圖所示:
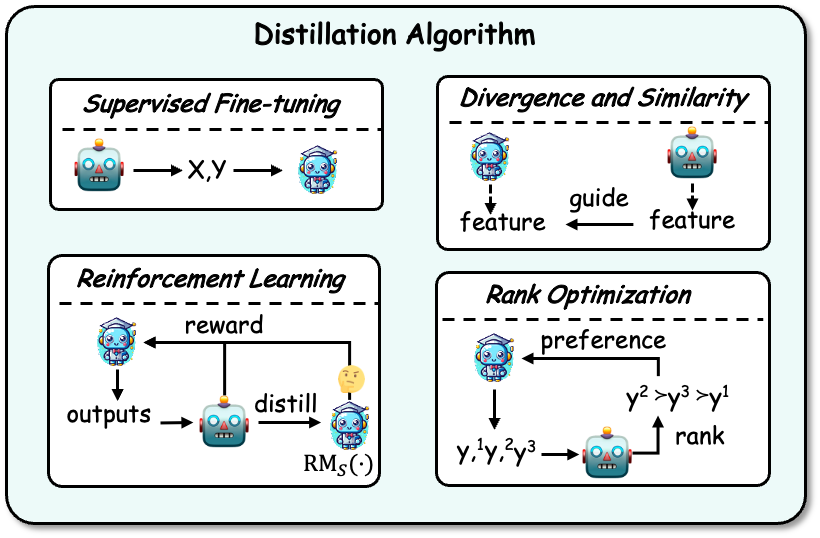
有監督微調:監督微調(SFT)透過最大化教師模型產生的序列的似然性來微調學生模型,讓學生模型來模仿教師模型。這是目前 LLMs 知識蒸餾中最常用的技術。
散度及相似度(Divergence and Similarity):此演算法將教師模型內部的參數知識作為學生模型訓練的監督訊號,適用於開源教師模型。基於散度與相似度的方法分別對齊機率分佈以及隱藏狀態。
強化學習(Reinforcement Learning):此演算法適用於利用教師的回饋知識來訓練學生模型,即 RLAIF 技術。主要有兩個面向:(1)使用教師產生的回饋資料訓練一個學生獎勵模型,(2)透過訓練好的獎勵模型,以最大化預期獎勵來優化學生模型。教師也可以直接作為獎勵模式。
排序最佳化(Rank Optimization):排序最佳化也可以將偏好知識注入到學生模型中,其優點在於穩定且計算效率高,一些經典演算法如 DPO,RRHF 等。
技能蒸餾
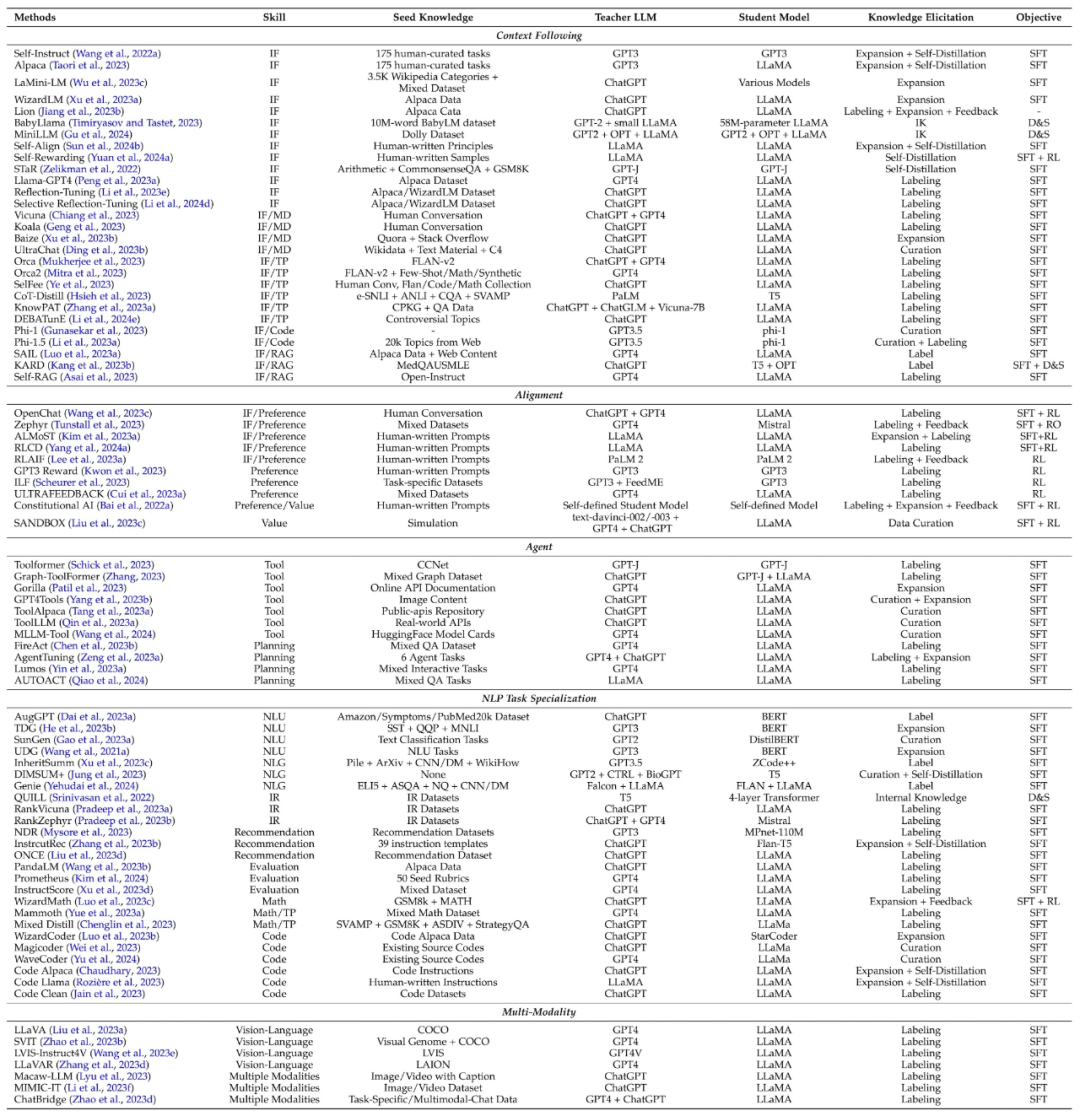
眾所周知,大語言模型具有許多出色的能力。透過知識蒸餾技術,提供指令來控制教師產生包含對應技能的知識並訓練學生模型,從而使其獲得這些能力。這些能力主要包括遵循情境(如指令)、對齊、智能體、自然語言處理(NLP)任務和多模態等能力。
下表總結了技能蒸餾的經典的工作,同時總結了各個工作涉及到的技能、種子知識、教師模型、學生模型、知識獲取方式、蒸餾演算法。
垂直領域蒸餾
除了在通用領域的大語言模型,現在有許多工作訓練垂直領域的大語言模型,這有助於研究界以及工業界對大語言模型的應用與部署。而大語言模型(如 GPT-4)在垂直領域上雖然具備的領域知識是有限的,但是仍能夠提供一些領域知識、能力或增強現有的領域資料集。這裡涉及的領域主要有(1)法律,(2)醫療健康,(3)金融,(4)科學,以及一些其他領域。本部分的分類學以及相關工作如下圖所示:

未來方向
此綜述探討了目前大語言模型知識蒸餾的問題以及潛在的未來研究方向,主要包括:
#數據選擇:如何自動選擇數據以實現更好的蒸餾效果?
多教師蒸餾:探究將不同教師模式的知識蒸餾到一個學生模型中。
教師模型中更豐富的知識:可以探索教師模型中更豐富的知識,包括回饋和特徵知識,以及探索多種知識獲取方法的組合。
克服蒸餾過程中災難性的遺忘:在知識蒸餾或遷移過程中有效地保留原始模型的能力仍然是一個具有挑戰性的問題。
可信任知識蒸餾:目前 KD 主要集中在蒸餾各種技能,對於大模型可信度方面的關注相對較少。
弱到強的蒸餾(Weak-to-Strong Distillation)。 OpenAI 提出了 「弱到強泛化」 概念,這需要探索創新的技術策略,使較弱的模型能夠有效地引導較強的模型的學習過程。
自我對齊(自蒸餾)。可以設計指令使得學生模型透過產生回饋、批評和解釋等內容使其自主地改進、對齊其生成內容。
結論
此綜述對如何利用大語言模型的知識來提升學生模型,如開源大語言模型,進行了全面且有系統地總結,同時包括了近期較流行的自蒸餾的技術。這篇綜述將知識蒸餾分為了兩個步驟:知識獲取以及蒸餾演算法,同時總結了技能蒸餾以及垂直領域蒸餾。最後,本綜述探討了蒸餾大語言模型的未來方向,希望能推動大語言模型知識蒸餾的邊界,得到更容易取得、高效、有效、可信的大語言模型。
以上是總結374篇相關工作,陶大程團隊聯合港大、UMD發布LLM知識蒸餾最新綜述的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















