

OpenAI大模型加持的機器人,深夜來襲!
名曰Figure 01,它能聽會說,動作靈活。

能和人類描述眼前所看到的一切:
我在桌上看到一個紅色的蘋果,瀝水架上還擺放著幾個盤子和一個杯子;你站在旁邊,雙手輕輕放在桌上。
 圖片
圖片
聽到人類說“想吃東西”,就馬上遞過去蘋果。
 圖片
圖片
而且對於自己做的事有清楚認知,給蘋果是因為這是桌上唯一能吃的東西。
還順便把東西整理,能同時搞定兩種任務。
 圖片
圖片
最關鍵的是,這些展示都沒有加速,機器人本來的動作就這麼迅速。
(也沒人在後面操縱)

這下網友坐不住了,立刻@波士頓動力:
#老夥計們,這傢伙是真來勁兒了。咱得回實驗室,讓以前的機器人(波士頓動力)多跳點舞了。
 圖片
圖片
也有網友看在OpenAI捲完大語言模型、文生影片之後,又狙擊機器人後感慨道:
#這是一場激烈的競爭;與OpenAl合作,蘋果可能會超越特斯拉。
但硬體方面,擎天柱看起來更美觀,Figure 01仍然需要一些「整容手術」。 (doge)
 圖片
圖片
接下來,我們繼續來看下Figure 01的細節。
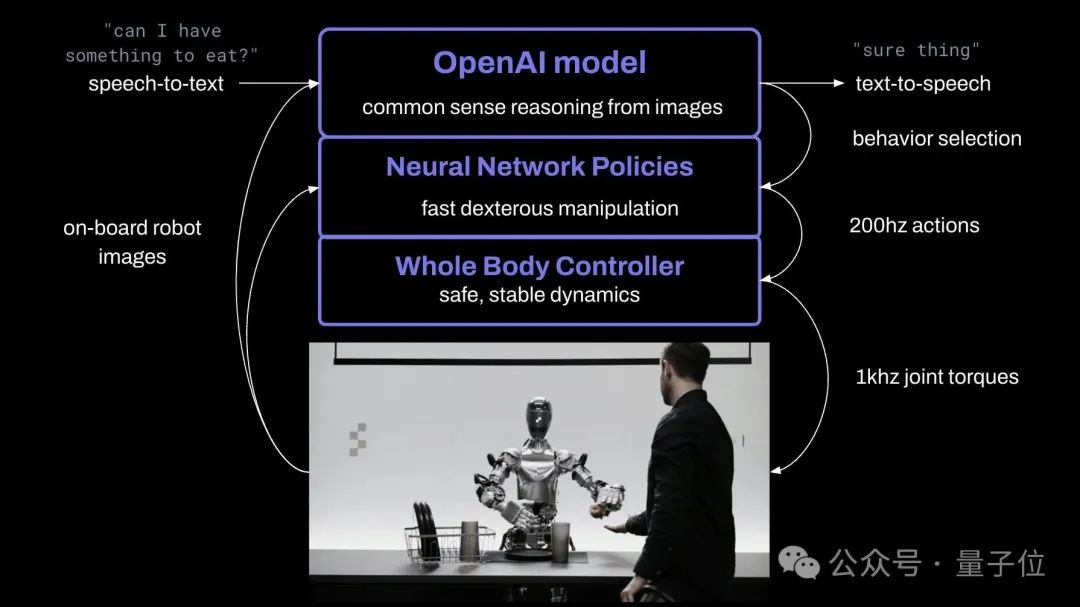
根據創始人的介紹,Figure 01透過端對端神經網絡,可以和人類自如對話。
基於OpenAI提供的視覺理解和語言理解能力,它能完成快速、簡單、靈巧的動作。
模型只說是視覺語言大模型,是否為GPT-4V不得而知。
 圖片
圖片
它也能規劃動作、有短期記憶能力、用語言解釋它的推理過程。
 圖片
圖片
例如對話裡說“你能把它們放在那裡嗎?”
“它們”、“那裡”這種模糊表達的理解,就體現了機器人的短期記憶能力。
它使用了OpenAI訓練的視覺語言模型,機器人相機會以10Hz拍攝畫面,然後神經網路將以200Hz輸出24自由度動作(手腕 手指關節角度)。
具體分工上,機器人的策略也很像人類。
複雜動作交給AI大模型,預訓練模型會對圖像和文字進行常識推理,給出動作計劃;
簡單動作如抓起塑膠袋(抓哪裡都可以) ,機器人基於已學習的視覺-動作執行策略,可以做出一些「下意識」的快速反應行動。
同時全身控制器會負責維持機身平衡、動作穩定。
 圖片
圖片
機器人的語音能力則是基於一個文字-語音大模型微調而來。
 圖片
圖片
除了最先進的AI模型,Figure 01背後公司——Figure的創始人兼CEO還在推文中提到,Figure方面整合了機器人的所有關鍵組成。
包含馬達、中介軟體作業系統、感測器、機械結構等,皆由Figure工程師設計。
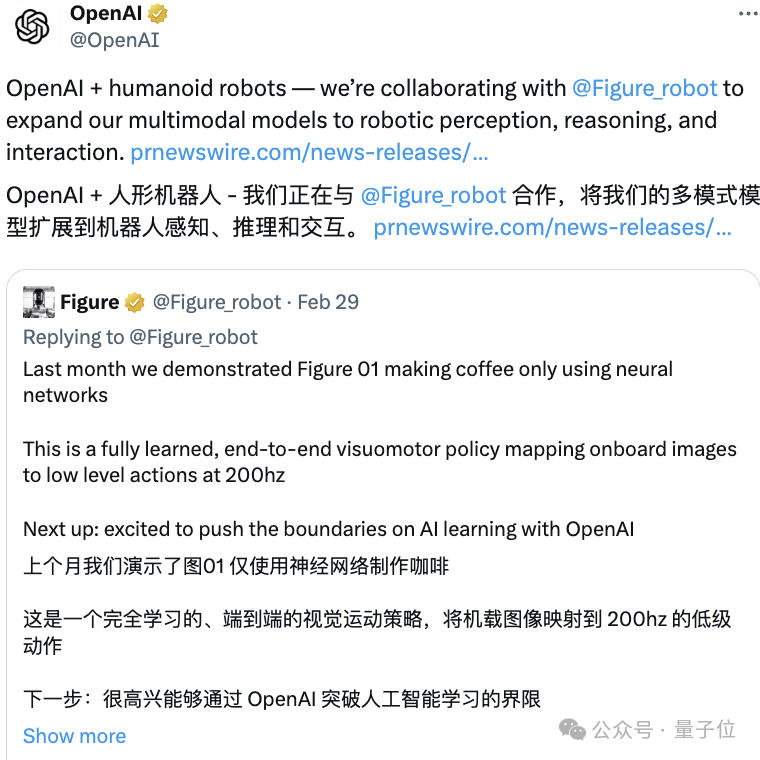
據了解,這家機器人新創公司在2週前才正式宣布和OpenAI的合作,但才13天後就帶來如此重磅成果。不少人都開始期待後續合作了。
 圖片
圖片
由此,具身智慧領域又有一顆新星走到了聚光燈下。
說到Figure,這家公司創立於2022年,正如前文所言,再次引爆外界關注,就在十幾天前——
官方宣佈在新一輪融資中籌集6.75億美元,估值衝到26億美元,投資者幾乎要集齊半個矽谷,包括微軟、OpenAI、英偉達和亞馬遜創始人貝佐斯等等。
更重要的是,OpenAI同時公開了與Figure更進一步合作的計劃:將多模態大模型的能力擴展到機器人的感知、推理和交互上,「開發能夠取代人類進行體力勞動的人形機器人」。
用現在最熱的科技詞彙來說,就是要一起搞身智能。
 圖片
圖片
彼時,Figure 01的最新進展是醬嬸的:
透過觀看人類的示範視頻,只需10小時端到端訓練,Figure 01就能學會用膠囊咖啡機泡咖啡。
 圖片
圖片
Figure與OpenAI的合作一公開,網友們就已經對未來的突破充滿了期待。
 圖片
圖片
畢竟Brett Adcock,可是把「唯一的重點是以30年的視角建立Figure,以積極影響人類的未來」這樣的話都寫在個人主頁上了。
但可能沒人能想得到,僅僅兩週左右的時間,新進展就來了。
如此之快,如此之遠。並且還能持續泛化、擴展規模。
 圖片
圖片
值得一提的是,與炸場demo同時發布的,還有Figure的招募資訊:
我們正在將人形機器人帶進生活。加入我們。
 圖片
圖片
#參考連結:
[1]//m.sbmmt.com/link/59bbfbe0d3922ccd1d167661a26d8353
[2]//m.sbmmt.com/link/a3fc34dce15cda93287496c84af5203c
[3]//m.sbmmt.com/link/194585b5215aea44738909056cfecfec
以上是OpenAI大模型上身機器人,原速示範炸場!的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















