

AGI真的越來越近了!
為了確保人類不會被AI殺死,在解密神經網路/Transfomer黑箱這一方面,OpenAI從未停下腳步。
去年5月,OpenAI團隊發布了一個令人震驚的發現:GPT-4竟可以解釋GPT-2的三十萬神經元!
網友紛紛驚呼,智慧原來是這個樣子。
 圖片
圖片
而就在剛剛,OpenAI超級對齊團隊負責人又正式官宣,要開源內部一直使用的大殺器-Transformer調試器(Transformer Debugger)。
簡之,研究者可以用TDB工具分析Transformer的內部結構,以便對小模型的特定行為進行調查。
 圖片
圖片
也就是說,有了這個TDB工具,未來它就可以幫我們剖析和分析AGI了!
 圖片
圖片
Transformer偵錯器將稀疏自動編碼器,與OpenAI開發的「自動可解釋性」—即用大模型自動解釋小模型,技術結合。
連結:OpenAI炸裂新作:GPT-4破解GPT-2腦! 30萬神經元全被看穿
 圖片
圖片
#論文網址:https://openaipublic.blob.core.windows. net/neuron-explainer/paper/index.html#sec-intro
#值得一提的是,研究者不用寫程式碼,就能快速探索LLM的內部建構。
例如,它可以回答「為什麼模型會輸出token A而不是token B」,「為什麼注意力頭H會關注token T」之類的問題。
 圖片
圖片
因為TDB能支持神經元和注意力頭,所以就可以讓研究人員透過消融單一神經元來介入前向傳遞,並觀察發生的具體變化。
不過根據Jan Leike的說法,這個工具現在還只是一個早期的版本,OpenAI放出來是希望更多的研究人員能夠用上,並且在現有基礎上進一步改進。
 圖片
圖片
專案網址:https://github.com/openai/transformer-debugger
要理解這個Transformer Debugger的工作原理,需要回顧OpenAI在2023年5月放出的一份和對齊有關的研究。

TDB工具是基於先前發布的兩項研究,不會發布論文
簡單來說,OpenAI希望用參數更大能力更強的模型(GPT-4)去自動分析小模型(GPT-2)的行為,解釋它的運作機制。
 圖片
圖片
當時OpenAI研究的初步結果是,參數比較少的模型容易被理解,但隨著模型參數變大,層數增加,解釋的效果會暴降。
 圖片
圖片
當時OpenAI在研究中稱,限於GPT-4本身設計就不是用來解釋小模型行為的,所以整體上對於GPT -2的解釋成果還很差。
 圖片
圖片
未來需要發展出能夠更好地解釋模型行為的演算法和工具。
而現在開源的Transformer Debugger,就是OpenAI在之後這一年的階段性成果。
而這個「更好的工具」-Transformer Debugger,就是將「稀疏自動編碼器」結合進這個「用大模型解釋小模型」的技術線路中去。
然後再將先前OpenAI在可解釋性研究中用GPT-4解釋小模型的過程零程式化,從而大大降低了研究人員上手的門檻。
在GitHub專案主頁,OpenAI團隊成員透過視頻介紹了最新Transformer調試器工具。
與Python調試器類似,TDB可以讓你逐步查看語言模型輸出、追蹤重要激活並分析上游激活。
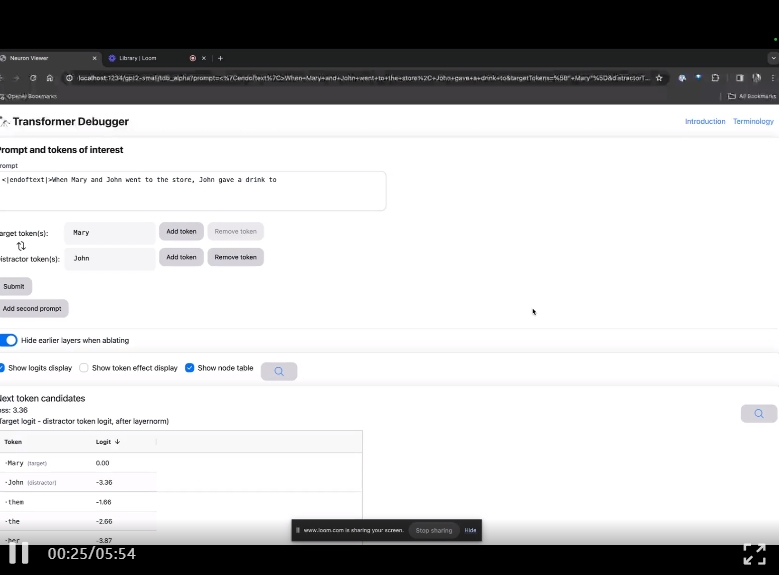
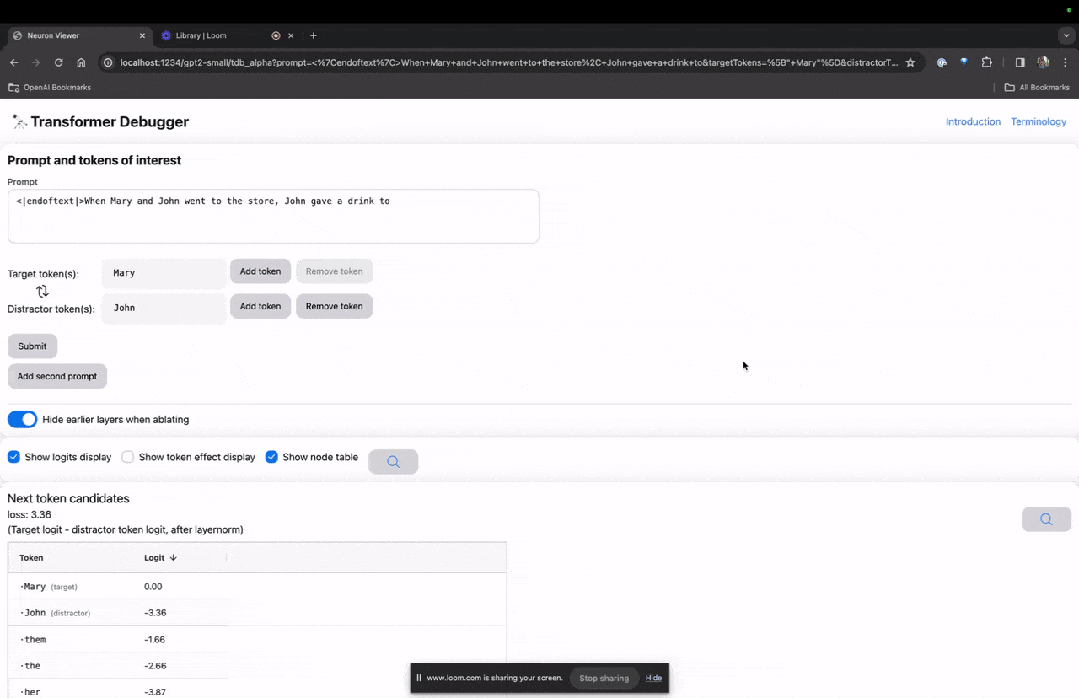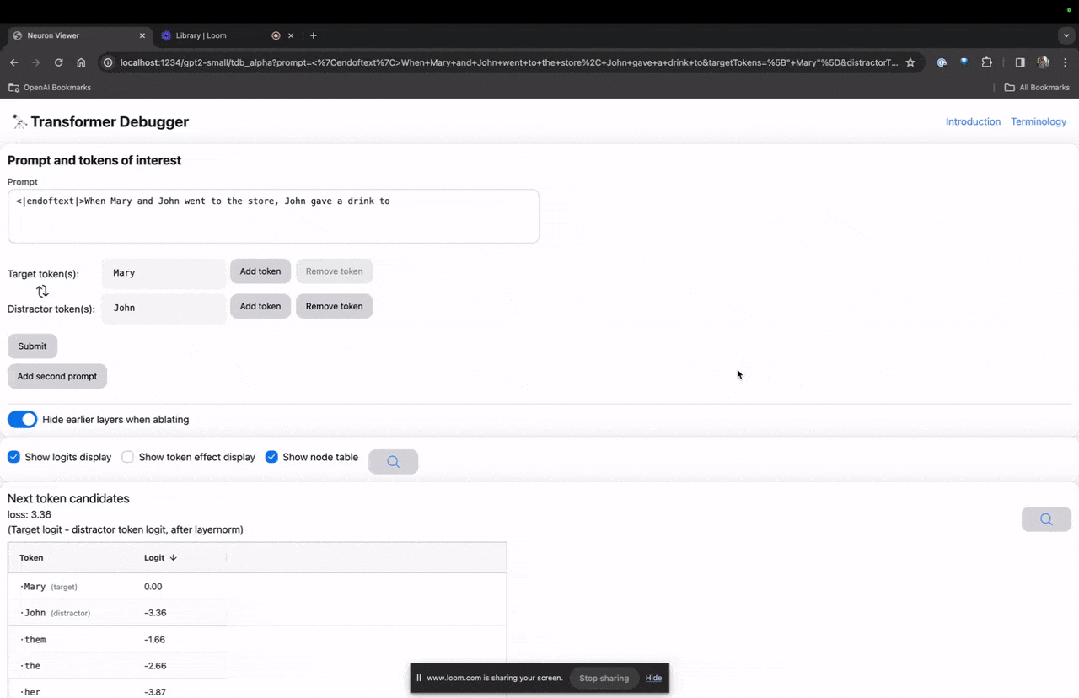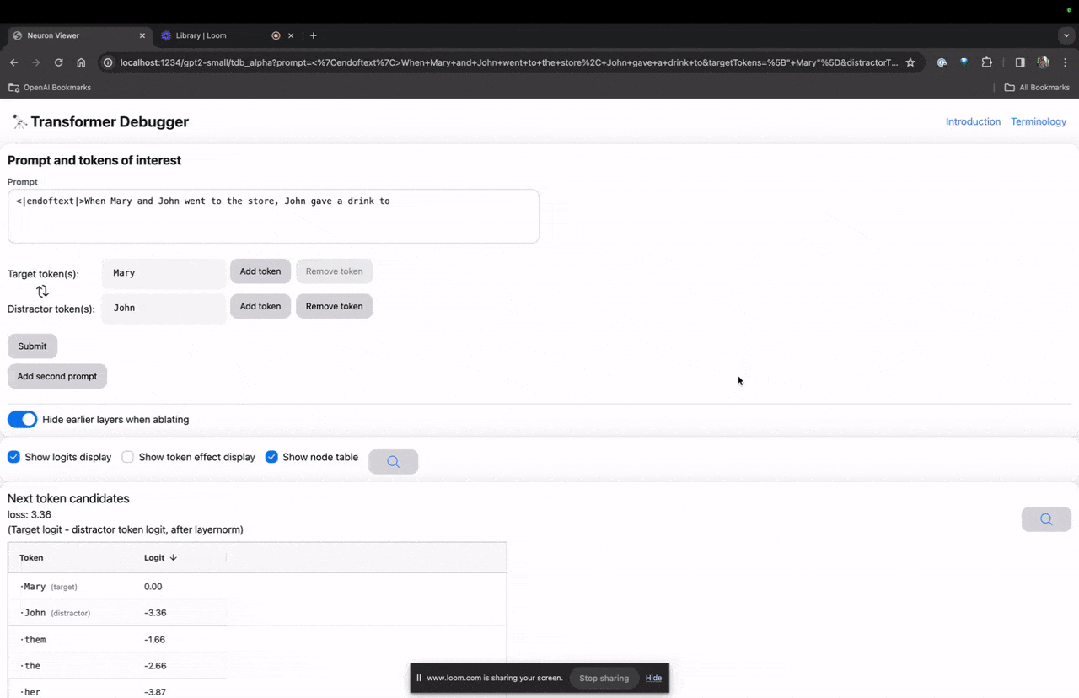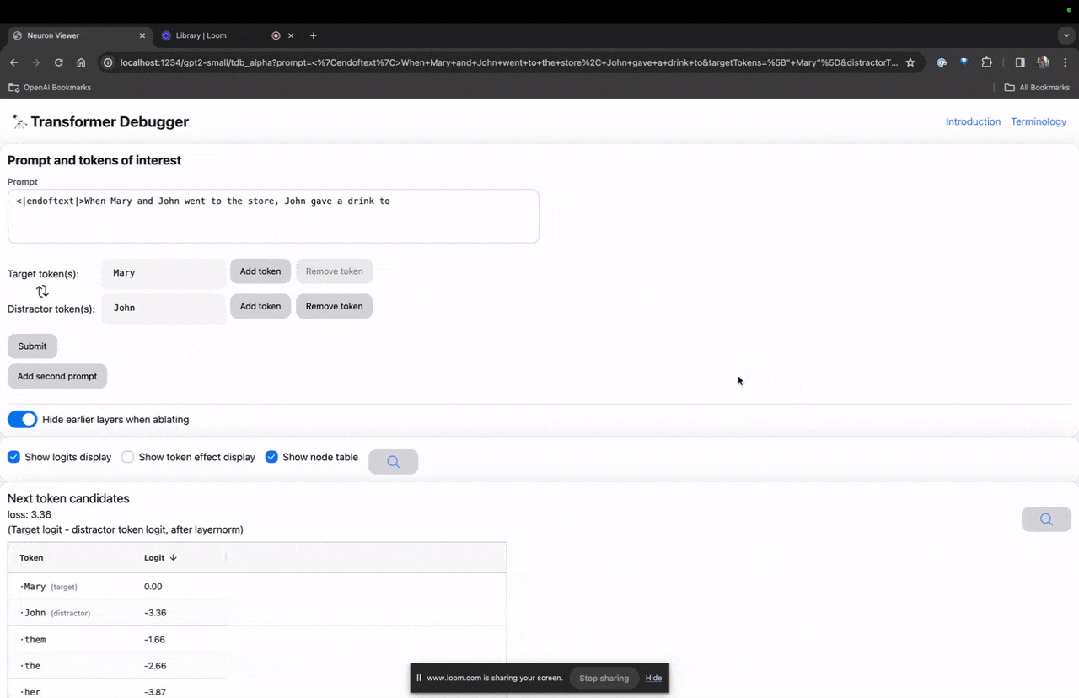
進入TDB主頁,首先是「提示」一欄輸入-提示與感興趣的token:
Mary and Johon went to the store, Johon gave a drink to....
那麼接下來,就是做一個「下一個字」的預測,需要輸入目標token,以及幹擾性的token。
最後提交後,便可以看到系統給出的預測下一字候選的對數。
下面的「節點表」是TDB的核心部分。這裡的每一行都對應一個節點,也就是啟動一個模型元件。
 圖片
圖片
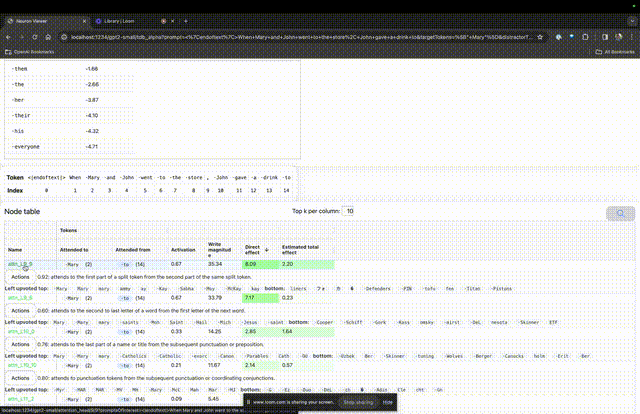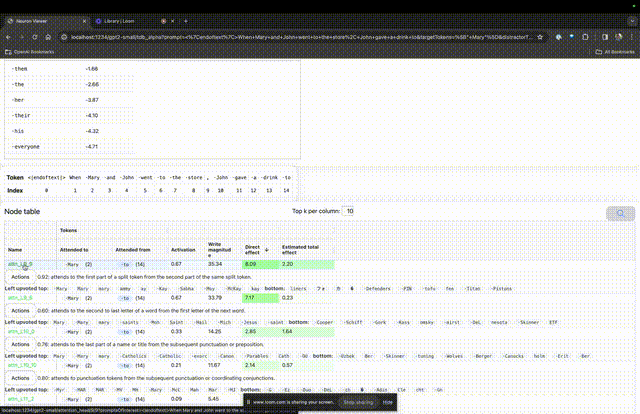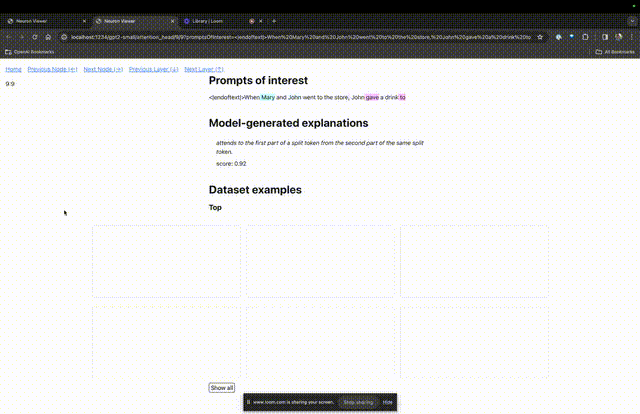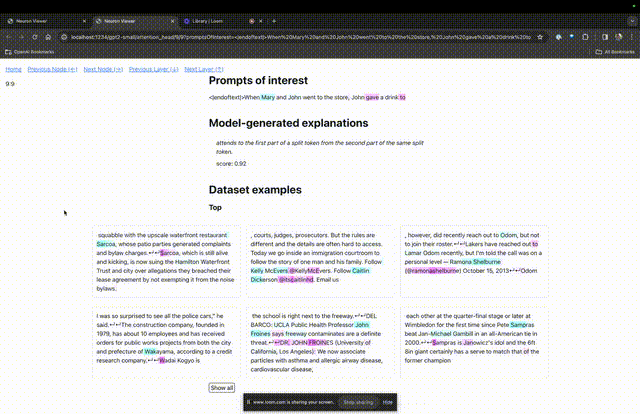
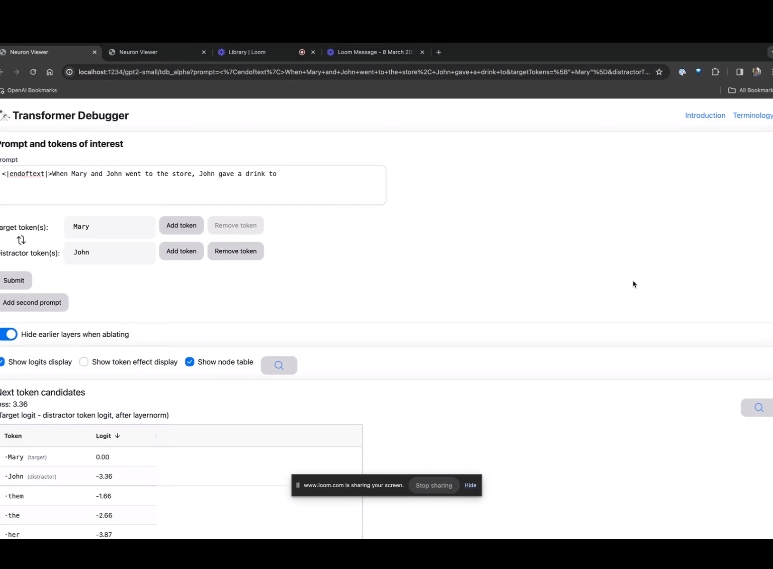
如果要了解對某個特定提示中非常重要的注意力頭的功能,直接點擊組件的名稱。
然後TDB會開啟「神經元瀏覽器 」頁面,頂部會顯示先前的提示詞。
 圖片
圖片
這裡可以看到淺藍色和粉紅色的token。每個對應顏色的token之下,從後續標記到這個token的注意力會讓一個大範數向量(large norm vector)被寫入後續token中。
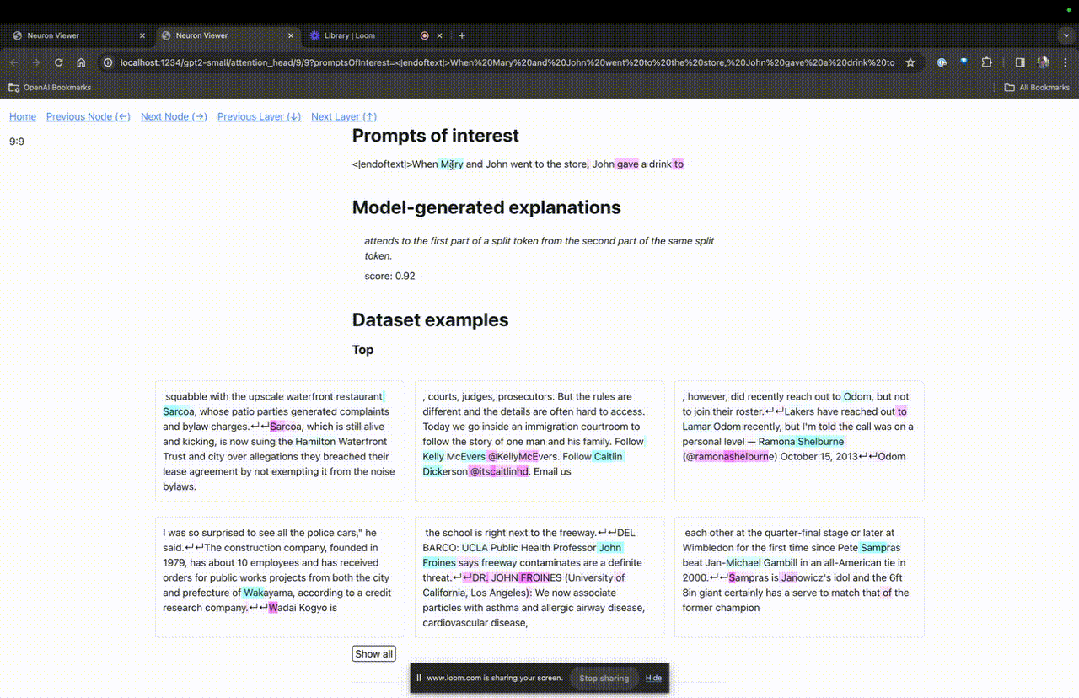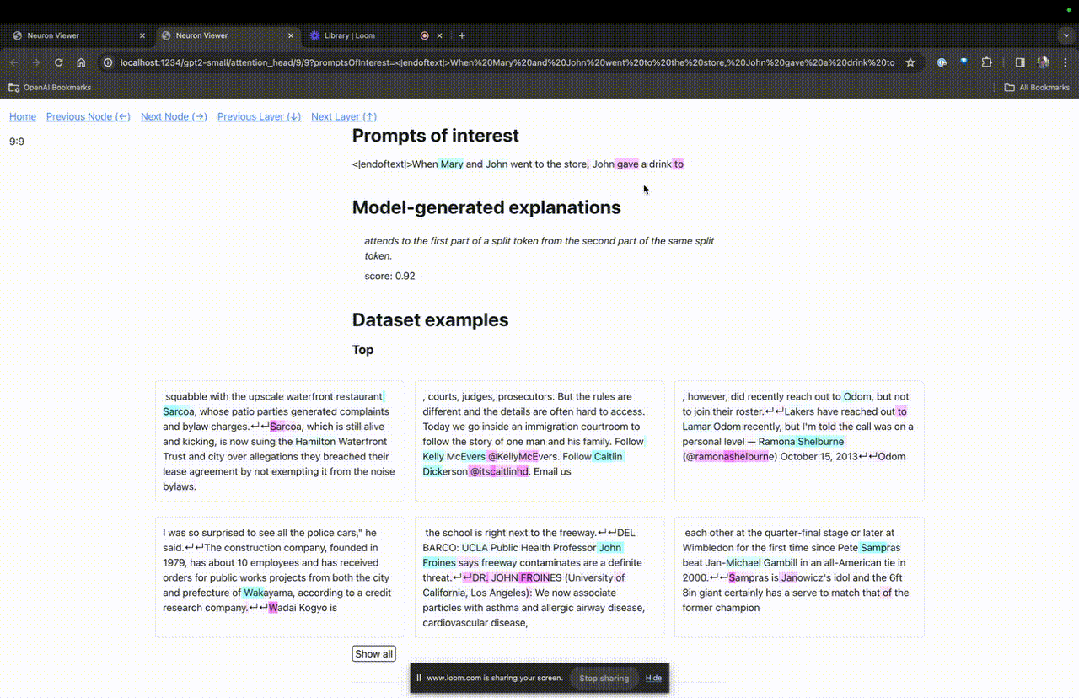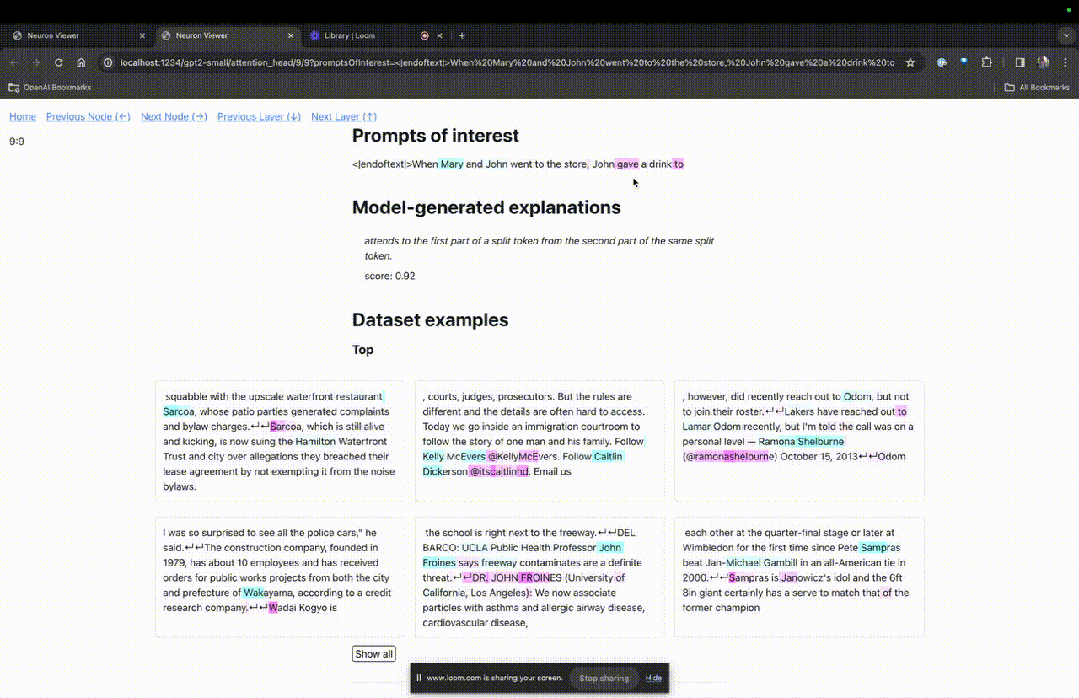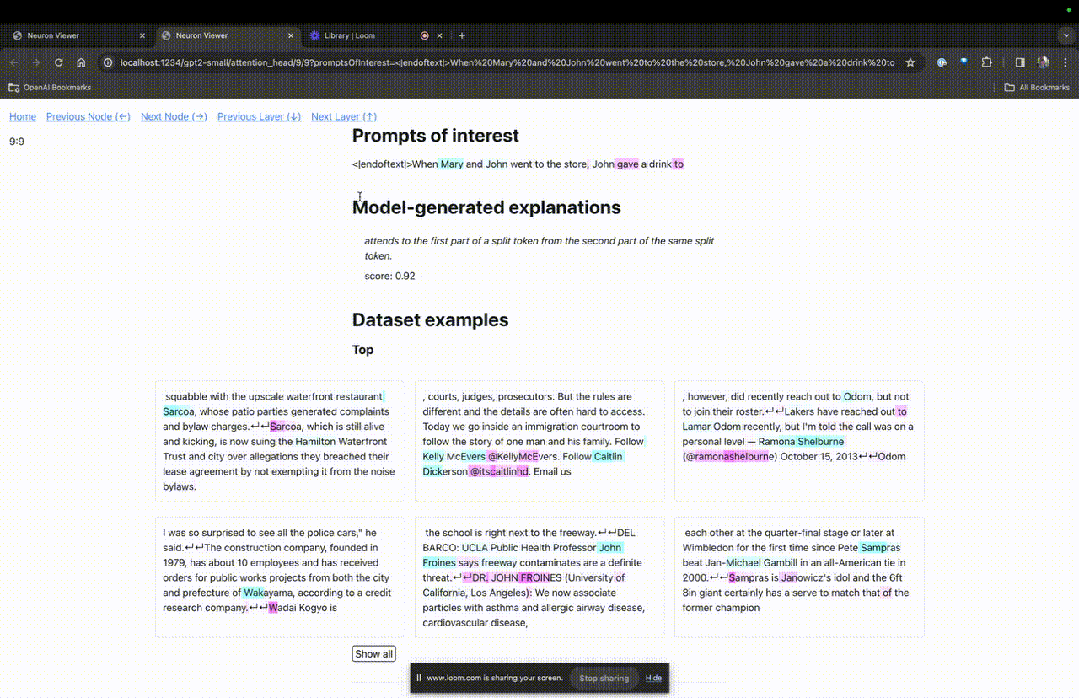 圖片
圖片
在另外兩個影片中,研究人員介紹了TDB的概念,以及在理解迴路中的應用。同時,他也示範了TDB如何定性地再現論文中的一個發現。
簡單來說,OpenAI自動可解釋性研究的想法是讓GPT-4對神經元的行為進行自然語言解釋,然後把這個過程應用在GPT-2。
這何以成為可能?首先,我們要「解剖」一下LLM。
就像大腦一樣,它們由「神經元」組成,它們會觀察文本中的某些特定模式,這就會決定整個模型接下來要說什麼。
例如,如果給出這麼一個prompt,「哪些漫威超級英雄擁有最有用的超能力?」「漫威超級英雄神經元」可能會增加模型命名漫威電影中特定超級英雄的機率。
OpenAI的工具就是利用這個設定,把模型分解成單獨的部分。
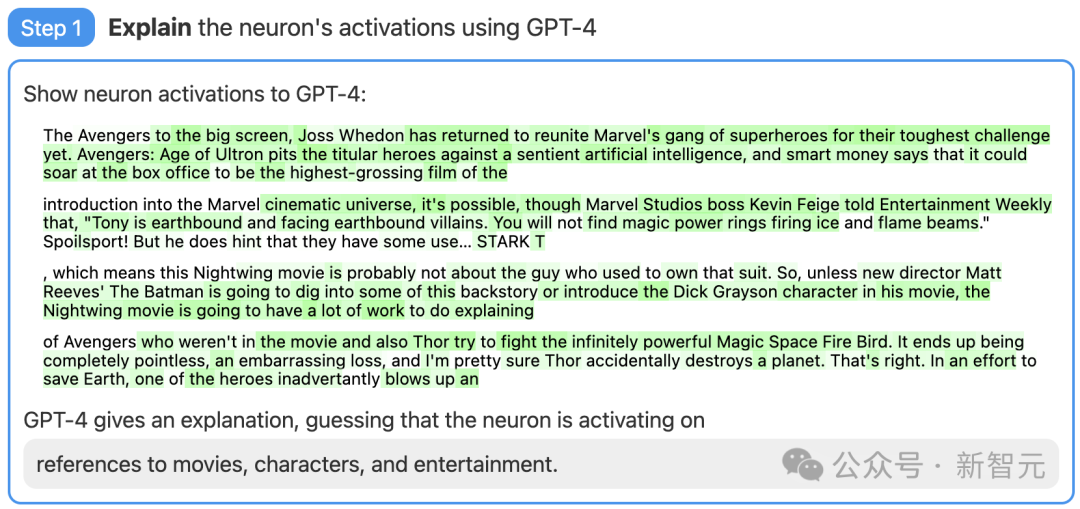
第一步:使用GPT-4產生解釋
#首先,找一個GPT-2的神經元,並向GPT-4展示相關的文字序列和活化。
然後,讓GPT-4根據這些行為,產生一個可能的解釋。
例如,在下面的例子中GPT-4就認為,這個神經元與電影、角色和娛樂有關。
 圖片
圖片
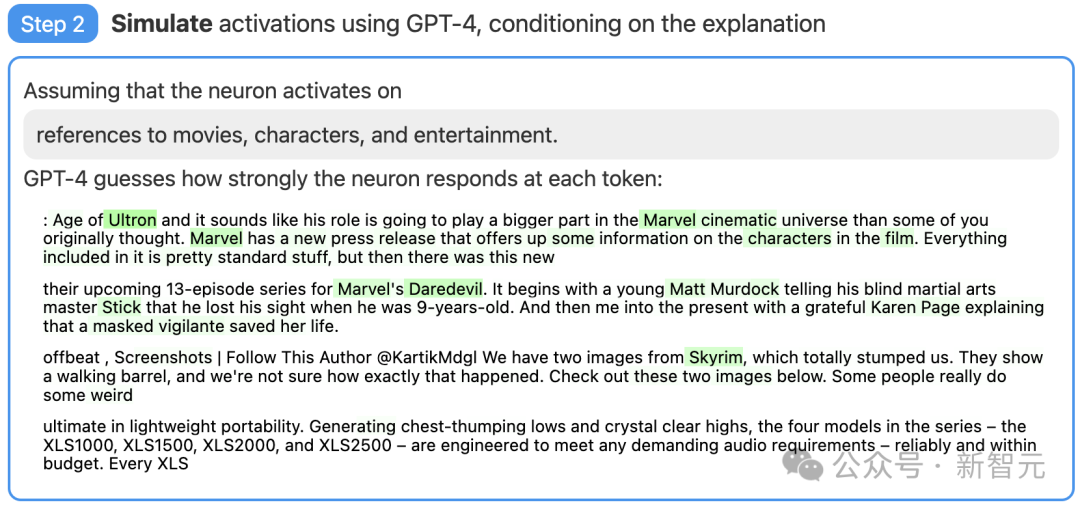
#接著,讓GPT-4根據自己產生的解釋,模擬以此活化的神經元會做什麼。
圖片
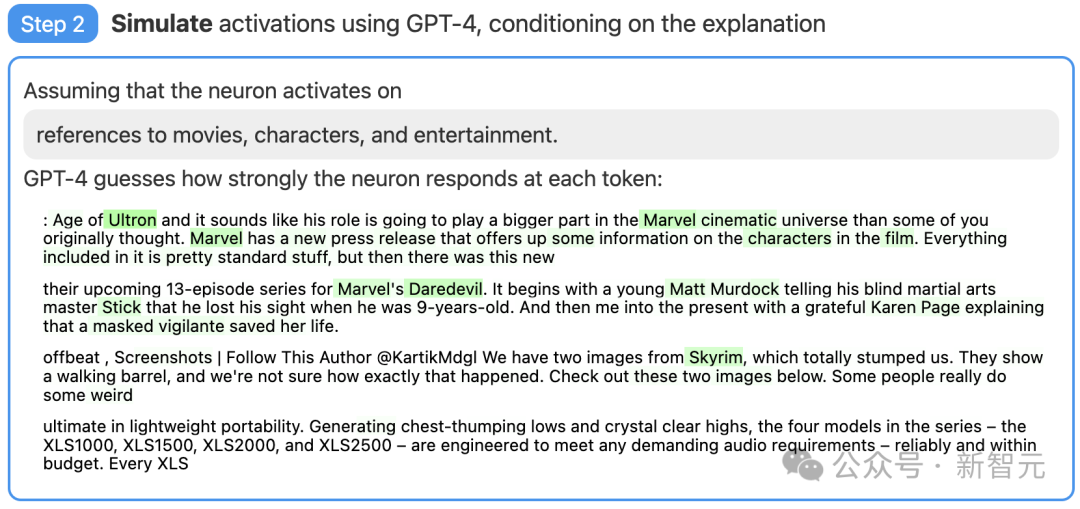 步驟三:對比打分
步驟三:對比打分

#最後,將模擬神經元(GPT-4)的行為與實際神經元(GPT-2)的行為進行比較,看看GPT-4究竟猜得有多準。
圖片
還有限制
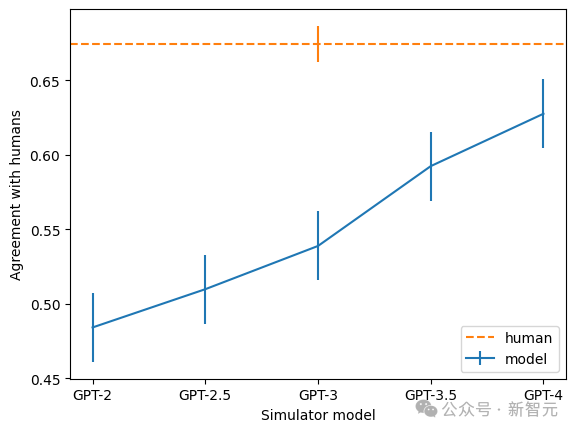 透過評分,OpenAI的研究者衡量了這項技術在神經網路的不同部分都是怎樣的效果。對於較大的模型,這項技術的解釋效果不佳,可能是因為後面的層更難解釋。
透過評分,OpenAI的研究者衡量了這項技術在神經網路的不同部分都是怎樣的效果。對於較大的模型,這項技術的解釋效果不佳,可能是因為後面的層更難解釋。
圖片
 目前,絕大多數解釋分數都很低,但研究者也發現,可以透過迭代解釋、使用更大的模型、更改所解釋模型的體系結構等方法,來提高分數。
目前,絕大多數解釋分數都很低,但研究者也發現,可以透過迭代解釋、使用更大的模型、更改所解釋模型的體系結構等方法,來提高分數。
 現在,OpenAI正在開源「用GPT-4來解釋GPT-2中全部307,200個神經元」結果的資料集和視覺化工具,也透過OpenAI API公開了市面上現有模型的解釋和評分的代碼,並且呼籲學界開發出更好的技術,產生得分更高的解釋。
現在,OpenAI正在開源「用GPT-4來解釋GPT-2中全部307,200個神經元」結果的資料集和視覺化工具,也透過OpenAI API公開了市面上現有模型的解釋和評分的代碼,並且呼籲學界開發出更好的技術,產生得分更高的解釋。
此外,團隊也發現,越大的模型,解釋的一致率也越高。其中,GPT-4最接近人類,但仍有不小的差距。 
圖片
OpenAI使用的的稀疏自動編碼器是一個在輸入端具有偏移的模型,還包括一個用於編碼器的具有偏置和ReLU的線性層,以及另一個用於解碼器的線性層和偏壓。
研究人員發現偏壓項對自動編碼器的性能非常重要,他們將輸入和輸出中應用的偏差聯繫起來,結果相當於從所有激活中減去固定偏差。
研究人員使用Adam優化器訓練自動編碼器,以使用MSE重建Transformer的MLP啟動。使用MSE損耗可以避免多語意性的挑戰,用損失加上L1懲罰項來鼓勵稀疏性。
在訓練自動編碼器時,有幾個原則非常重要。
首先是規模。在更多資料上訓練自動編碼器會使特徵主觀上「更清晰」且更具可解釋性。所以OpenAI為自動編碼器使用了80億個訓練點。
其次,在訓練過程中,有些神經元會停止激活,即使在大量資料點上也是如此。
研究人員於是在訓練期間「重採樣」這些死神經元,允許模型代表給定的自動編碼器隱藏層維度的更多特徵,從而產生更好的結果。
怎麼判斷自己的方法是否有效?在機器學習中可以簡單地用loss作為標準,但在這裡就不太容易找到類似的參考。
例如尋找一個基於資訊的指標,這樣可以在某種意義上說,最好的分解是最小化自動編碼器和資料總資訊的分解。
——但事實上,總資訊通常與主觀特徵可解釋性或活化稀疏性無關。
最終,研究人員使用了幾個附加指標的組合:
- 手動檢查:特徵是否看起來可以解釋?
- 特徵密度:即時特徵數量和觸發它們的token的百分比是一個非常有用的指導。
- 重建損失:衡量自動編碼器重建MLP啟動的程度。最終目標是解釋MLP層的功能,因此MSE損耗應該很低。
- 玩具模型:使用一個已經非常了解的模型,可以清楚評估自動編碼器的效能。
不過研究人員也表示,希望從Transformer上訓練的稀疏自動編碼器中,為字典學習解決方案確定更好的指標。
參考資料:
以上是OpenAI官宣開源Transformer Debugger!不用寫程式碼,人人可以破解LLM黑箱的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















