

隨著大語言模型如GPT-4與機器人技術的結合日益緊密,人工智慧正逐漸走向現實世界。因此,與具身智能相關的研究也引起越來越多的關注。在許多研究計畫中,Google的"RT"系列機器人一直處於前沿地位,這一趨勢在近期開始加速(詳見《大模型正在重構機器人,GoogleDeepmind如何定義未來的具身智慧》)。

去年7月,GoogleDeepMind推出了RT-2,這是全球第一個能夠控制機器人進行視覺-語言-動作(VLA )交互作用的模型。只要用對話的方式下達指令,RT-2就能在大量圖片中辨識出黴黴,並將一罐可樂送到她手中。
如今,這個機器人又進化了。最新版的 RT 機器人名為「RT-H」,它能透過將複雜任務分解成簡單的語言指令,再將這些指令轉化為機器人行動,來提高任務執行的準確性和學習效率。舉例來說,給定一項任務,如「蓋上開心果罐的蓋子」和場景圖像,RT-H 會利用視覺語言模型(VLM)預測語言動作(motion),如「向前移動手臂」和「向右旋轉手臂」,然後根據這些語言動作,預測機器人的行動(action)。

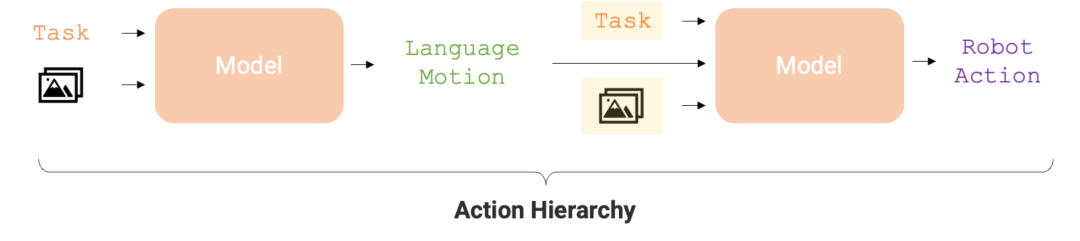
行動層級對於最佳化機器人任務執行的準確性和學習效率至關重要。這種層級結構使得 RT-H 在各種機器人任務中的表現明顯優於 RT-2,為機器人提供了更有效率的執行路徑。

以下是論文的詳細資訊。

專案連結:https://rt-hierarchy.github.io/
語言是人類推理的引擎,它使我們能夠將複雜概念分解為更簡單的組成部分,糾正我們的誤解,並在新環境中推廣概念。近年來,機器人也開始利用語言高效、組合式的結構來分解高層次概念、提供語言修正或實現在新環境下的泛化。
這些研究通常遵循一個共同的範式:面對一個用語言描述的高層任務(如「拿起可樂罐」),它們學習將觀察和語言中的任務描述映射到低層次機器人行動的策略,這需要透過大規模多任務資料集實現。語言在這些場景中的優勢在於編碼類似任務之間的共享結構(例如,「拿起可樂罐」與「拿起蘋果」),從而減少了學習從任務到行動映射所需的資料。然而,隨著任務變得更加多樣化,描述每個任務的語言也變得更加多樣(例如,「拿起可樂罐」與「倒一杯水」),這使得僅透過高層次語言學習不同任務之間的共享結構變得更加困難。
為了學習多樣化的任務,研究者的目標是更準確地捕捉這些任務之間的相似性。 ############他們發現語言不僅可以描述高階任務,還能細緻地說明完成任務的方法 —— 這種表示更細膩,更貼近具體動作。例如,「拿起可樂罐」這項任務可以分解為一系列更細節的步驟,即「語言動作(language motion)」:首先「手臂向前伸」,接著「抓緊罐子」,最後「手臂上舉」。研究者的核心洞見是,透過將語言動作作為連結高階任務描述與底層動作之間的中間層,可以利用它們來建構一個透過語言動作形成的行動層級。 ############建立這種行動層級有幾大好處:######

鑑於語言動作存在以上優勢,來自GoogleDeepMind 的研究者設計了一個端到端的框架-RT-H( Robot Transformer with Action Hierarchies,即使用行動層級的機器人Transformer),專注於學習這類行動層級。 RT-H 透過分析觀察結果和高層次任務描述來預測當前的語言動作指令,從而在細節層面上理解如何執行任務。接著,利用這些觀察、任務以及推斷出的語言動作,RT-H 為每一步驟預測相應的行動,語言動作在此過程中提供額外的上下文,幫助更準確地預測具體行動(圖1 紫色區域) 。
此外,他們還開發了一種自動化方法,從機器人的本體感受中提取簡化的語言動作集,建立了包含超過2500 個語言動作的豐富資料庫,無需手動標註。
RT-H 的模型架構借鑒了RT-2,後者是一個在互聯網規模的視覺與語言資料上共同訓練的大型視覺語言模型(VLM),旨在提升策略學習效果。 RT-H 採用單一模型同時處理語言動作和行動查詢,充分利用廣泛的互聯網規模知識,為行動層級的各個層次提供支援。
在實驗中,研究者發現使用語言動作層級在處理多樣化的多任務資料集時能夠帶來顯著的改善,相比RT-2 在一系列任務上的表現提高了15%。他們也發現,修正語言動作能夠在同樣的任務上達到接近完美的成功率,展現了學習到的語言動作的彈性和情境適應性。此外,透過對模型進行語言動作介入的微調,其表現超過了 SOTA 互動模仿學習方法(如 IWR)50%。最終,他們證明了 RT-H 中的語言動作能夠更好地適應場景和物體變化,相比於 RT-2 展現了更優的泛化表現。
為了有效地捕捉跨多任務資料集的共享結構(不由高階任務描述表徵), RT-H 旨在學習明確利用行動層級策略。
具體來說,研究團隊將中間語言動作預測層引入策略學習。描述機器人細粒度行為的語言動作可以從多任務資料集中捕捉有用的信息,並且可以產生高效能的策略。當學習到的策略難以執行時,語言動作可以再次發揮作用:它們為與給定場景相關的線上人工修正提供了直覺的介面。經過語言動作訓練的策略可以自然地遵循低程度的人工修正,並在給定修正資料的情況下成功完成任務。此外,該策略甚至可以根據語言修正資料進行訓練,並進一步提高其效能。
如圖2 所示,RT-H 有兩個關鍵階段:先根據任務描述和視覺觀察預測語言動作,然後根據預測的語言動作、具體任務、觀察結果推斷精確的行動。
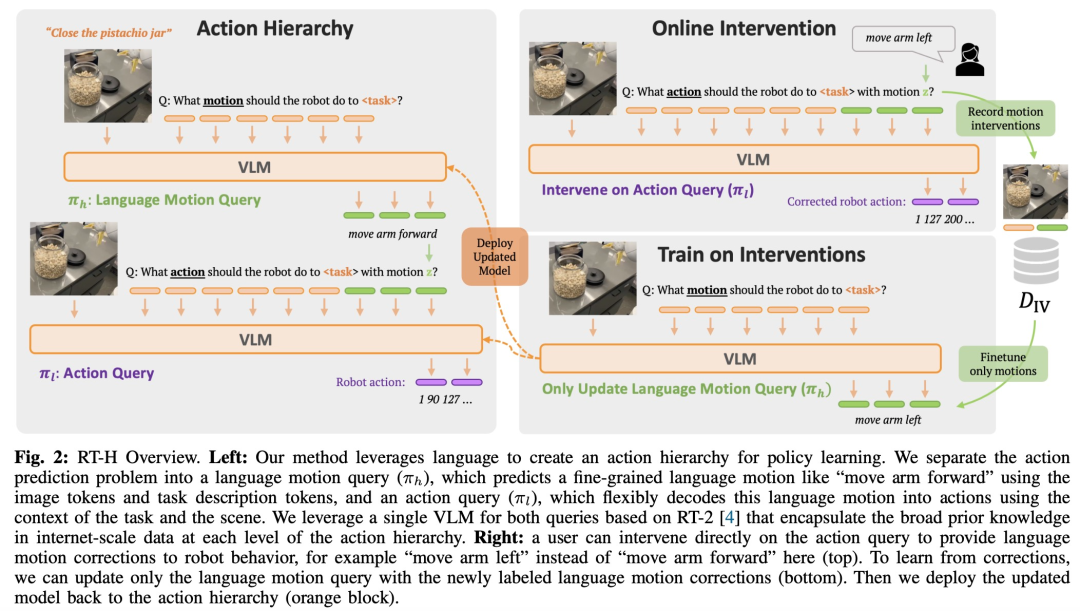
RT-H 使用 VLM 主幹網路並遵循 RT-2 的訓練過程來進行實例化。與 RT-2 類似,RT-H 透過協同訓練利用了互聯網規模資料中自然語言和影像處理的大量先驗知識。為了將這些先驗知識合併到行動層級的所有層次中,單一模型會同時學習語言動作和行動查詢。
為了全面評估RT-H 的效能,研究團隊設定了四個關鍵的實驗問題:
資料集方面,該研究採用一個大型多任務資料集,其中包含 10 萬個具有隨機物件姿態和背景的演示樣本。此資料集結合了以下資料集:
該研究將此組合資料集稱為 Diverse Kitchen (D K) 資料集,並使用自動化程式對其進行語言動作標記。為了評估在完整Diverse Kitchen 資料集上訓練的RT-H 的性能,該研究針對八項具體任務進行了評估,包括:
1)將碗直立放在櫃檯上
2)打開開心果罐
#3)關閉開心果罐
##4 )將碗移離穀物分配器
5)將碗放在穀物分配器下方
##6)將燕麥片放入碗中7)從籃子拿湯匙
#8)從分配器中拉出餐巾
選擇這八個任務是因為它們需要複雜的動作序列和高精度。
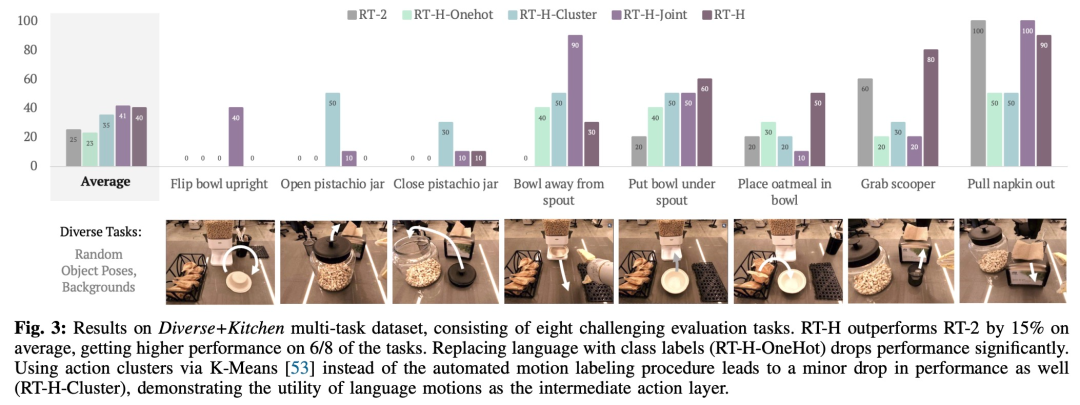
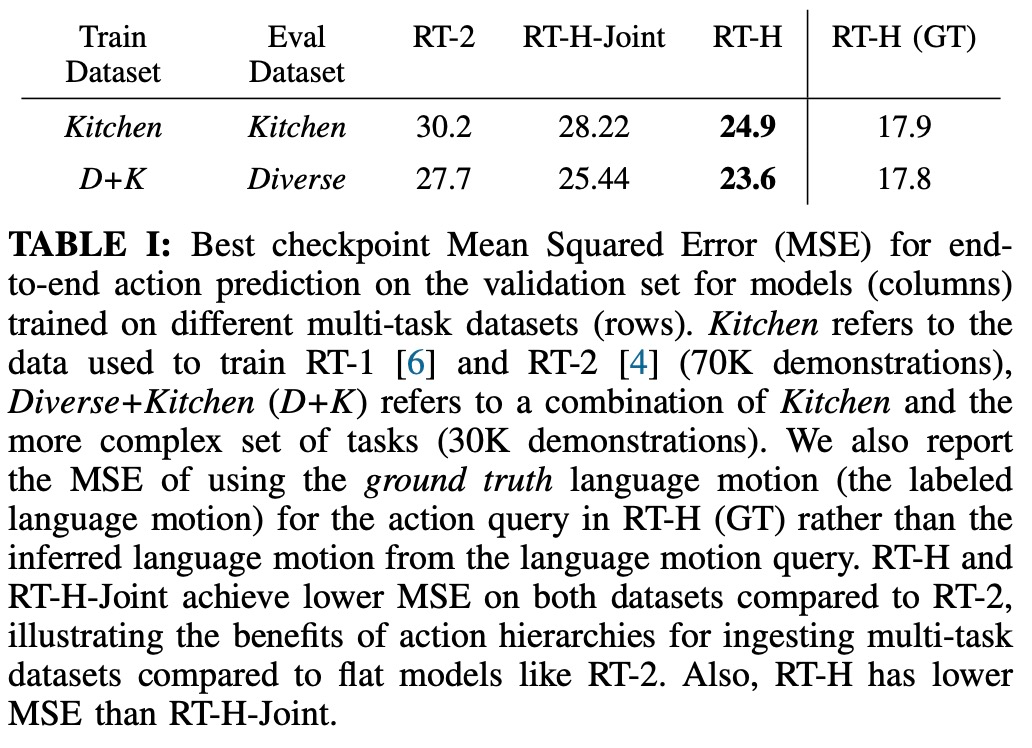


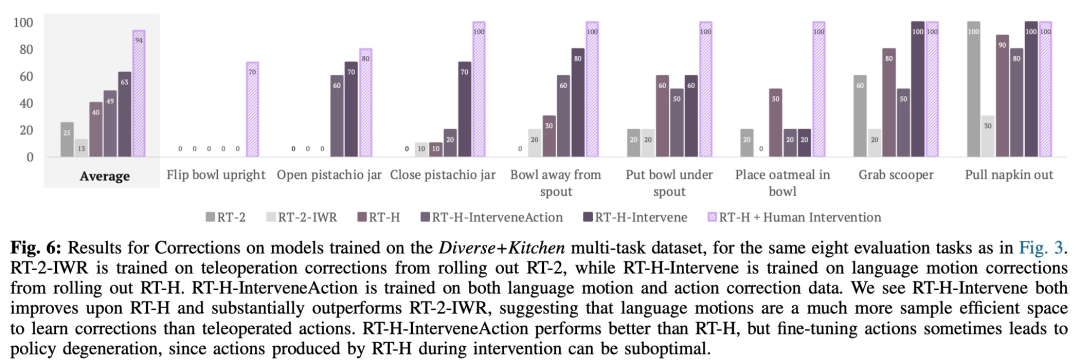
實際上,看似不同的任務之間具備一些共享結構,例如這些任務中每一個都需要一些拾取行為來開始任務,並且透過學習跨不同任務的語言動作的共享結構,RT -H 可以完成拾取階段而無需任何修正。

即使當RT-H 不再能夠泛化其語言動作預測時,語言動作修正通常也可以泛化,因此只需進行有些修正就可以成功完成任務。這顯示語言動作在擴大新任務資料收集方面的潛力。
有興趣的讀者可以閱讀論文原文,了解更多研究內容。
以上是Google具身智能新研究:比RT-2優秀的RT-H來了的詳細內容。更多資訊請關注PHP中文網其他相關文章!


































