#眾所周知,開發頂級的文生圖(T2I)模型需要大量資源,因此資源有限的個人研究者基本上都不可能承擔得起,這也成為了AIGC(人工智慧內容生成)社群創新的一大阻礙。同時隨著時間的推移,AIGC 社群又能獲得持續更新的、更高品質的資料集和更先進的演算法。 於是關鍵的問題來了:我們能以怎樣的方式將這些新元素高效地整合進現有模型,依託有限的資源讓模型變得更強大? 為了探索這個問題,華為諾亞方舟實驗室等研究機構的一個研究團隊提出一種新的訓練方法:由弱到強式訓練(weak- to-strong training)。 
論文標題:PixArt-Σ: Weak-to-Strong Training of Diffusion Transformer for 4K Text-to-Image Generation論文地址:https: //arxiv.org/pdf/2403.04692.pdf專案頁:https://pixart-alpha.github.io/PixArt-sigma-project/ 他們的研究是基於他們去年十月提出的一種高效的文生圖訓練方法PixArt-α,參閱本站報道《超低訓練成本文生圖模型PixArt 來了,效果媲美MJ,只需SD 10% 訓練時間》。 PixArt-α 是 DiT(擴散 Transformer)框架的一種早期嘗試。而現在,隨著 Sora 登上熱搜以及 Stable Diffusion 層出不窮的應用,DiT 架構的有效性得到了研究社區越來越多工作的驗證,例如 PixArt, Dit-3D, GenTron 等“1”。 該團隊使用 PixArt-α 的預訓練基礎模型,透過整合進階元素以促進其持續提升,最終得到了一個更強大的模型 PixArt-Σ。圖 1 展示了一些生成結果範例。 
具體來說,為了實現由弱到強式訓練,造出 PixArt-Σ,團隊採用了以下改進措施。 #該團隊收集了一個高品質數據集Internal-Σ,其主要關注兩個面向:(1) 高品質影像:此資料集包含3,300 萬張來自網路的高解析度影像,全都超過1K 分辨率,包括230 萬張分辨率大約為4K 的圖像。這些圖像的主要特點是美觀度高並且涵蓋廣泛的藝術風格。 (2) 密集且準確的描述:為了給上述圖像更精準和詳細的描述,團隊將PixArt-α 中使用的LLaVA 替換成了一種更強大的圖像描述器Share-Captioner。 不僅如此,為了提升模型對齊文字概念和視覺概念的能力,該團隊將文字編碼器(即Flan-T5)的token 長度擴展到了大約300 字。他們觀察到,這些改進可以有效消除模型產生幻覺的傾向,實現更高品質的文字 - 圖像對齊。 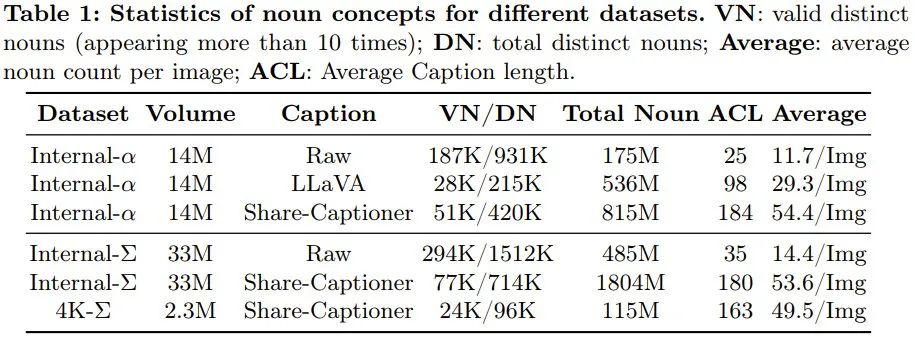
#為了增強PixArt-α,該團隊將其生成解析度從1K 提升到了4K。為了產生超高解析度(如 2K/4K)的影像,token 數量會大幅成長,這會導致運算需求大幅成長。 為了解決這個難題,他們引入了專門針對 DiT 框架調整過的自註意力模組,其中使用了鍵和值 token 壓縮。具體來說,他們使用了步長為 2 的分組卷積來執行鍵和值的局部聚合,如下圖 7 所示。 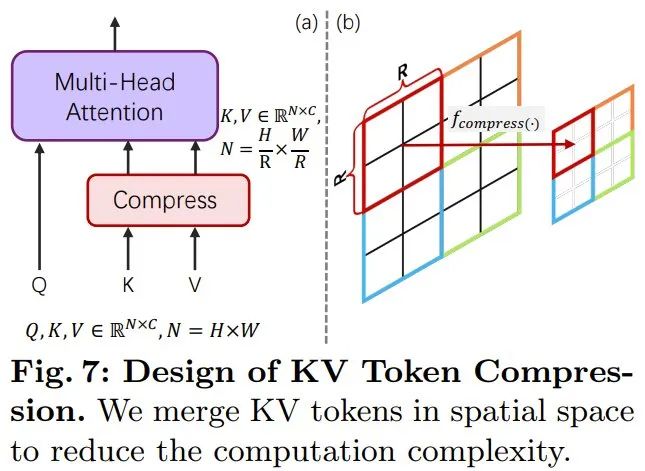
此外,團隊還採用了一種專門設計的權重初始化方案,可在不使用 KV(鍵 - 值)壓縮的前提下從預訓練模型實現平滑適應。這項設計可有效將高解析度影像產生的訓練和推理時間降低約 34%。 #該團隊提出了多種微調技術,可快速且有效率地將弱模型調整為強模型。其中包括:(1) 替換使用了更強大的變分自動編碼器(VAE):將 PixArt-α 的 VAE 替換成了 SDXL 的 VAE。 (2) 從低解析度到高解析度擴展,這個過程為了應對效能下降的問題,他們使用了位置嵌入(PE)插值方法。 (3) 從不使用 KV 壓縮的模型演進為使用 KV 壓縮的模型。 實驗結果驗證了由弱到強式訓練方法的可行性和有效性。 透過上述改進,PixArt-Σ 能以盡可能低的訓練成本和盡可能少的模型參數產生高品質的 4K 解析度影像。 具體來說,透過從一個已經預先訓練的模型開始微調,該團隊僅額外使用PixArt-α 所需的9% 的GPU 時間,就得到了能生成1K 高解析度影像的模型。如此表現非常出色,因為其中還取代使用了新的訓練資料和更強大的 VAE。 此外,PixArt-Σ 的參數量也只有 0.6B,相較之下,SDXL 和 SD Cascade 的參數量分別為 2.6B 和 5.1B。 PixArt-Σ 產生的影像的美觀程度足以比肩目前最頂級的文生圖產品,例如 DALL・E 3 和 MJV6。此外,PixArt-Σ 也展現出了與文字 prompt 細粒度對齊的卓越能力。
圖 2 展示了一張 PixArt-Σ 產生 4K 高解析度影像的結果,可以看到產生結果很好地遵從了複雜且資訊密集的文字指令。 
#訓練細節:對於執行條件特徵提取的文本編碼器,團隊按照Imagen 和PixArt-α 的做法使用了T5 的編碼器(即Flan-T5-XXL)。基礎擴散模型就是 PixArt-α。不同於大多數研究提取固定的77 個文本token 的做法,這裡將文本token 的長度從PixArt-α 的120 提升到了300,因為Internal-Σ 中整理的描述信息更加密集,可以提供高細粒度的細節。另外 VAE 使用了 SDXL 的已預先訓練的凍結版 VAE。其它實現細節與 PixArt-α 一樣。 模型是基於 PixArt-α 的 256px 預訓練檢查點開始微調的,並使用了位置嵌入插值技術。 最終的模型(包括 1K 解析度)是在 32 塊 V100 GPU 上訓練的。他們還額外使用了 16 塊 A100 GPU 來訓練 2K 和 4K 影像生成模型。 評估指標:為了更好地展示美觀度和語義能力,團隊收集了3 萬對高品質文字- 圖像,以對最強大的文生圖模型進行基準評估。這裡主要是透過人類和 AI 偏好來評估 PixArt-Σ,因為 FID 指標可能無法適當地反映生成品質。 # 影像品質評估:團隊定性地比較了PixArt- Σ 與閉源文生圖(T2I)產品與開源模型的生成品質。如圖 3 所示,相較於開源模型 SDXL 和該團隊之前的 PixArt-α,PixArt-Σ 生成的人像的真實感更高,並且也有更好的語義分析能力。與 SDXL 相比,PixArt-Σ 能更好地遵循使用者指令。 
PixArt-Σ 不僅優於開源模型,而且與目前的閉源產品相比也頗具競爭力,如圖 4 所示。 
產生高解析度影像:新方法可以直接產生 4K 解析度的影像,而無需任何後處理。此外,PixArt-Σ 也能準確遵從使用者提供的複雜和詳細的長文本。因此,使用者無需費心設計 prompt 也能得到讓人滿意的結果。 人類 / AI(GPT-4V)偏好研究:團隊也研究了人類和 AI 對生成結果的偏好。他們收集了 6 個開源模型的生成結果,包括 PixArt-α、PixArt-Σ、SD1.5、Stable Turbo、Stable XL、Stable Cascade 和 Playground-V2.0。他們開發了一個網站,透過展現 prompt 和對應的圖像來收集人類偏好回饋。 人類評估者可根據生成品質以及與 prompt 的匹配程度來給予影像排名。結果見圖 9 的藍色長條圖。 可以看出人類評估者對 PixArt-Σ 的熱愛勝過其它 6 個生成器。相較於先前的文生圖擴散模型,如SDXL(2.6B 參數)和SD Cascade(5.1B 參數),PixArt-Σ 能以少得多的參數(0.6B)產生更高品質且更符合用戶prompt 的圖像。 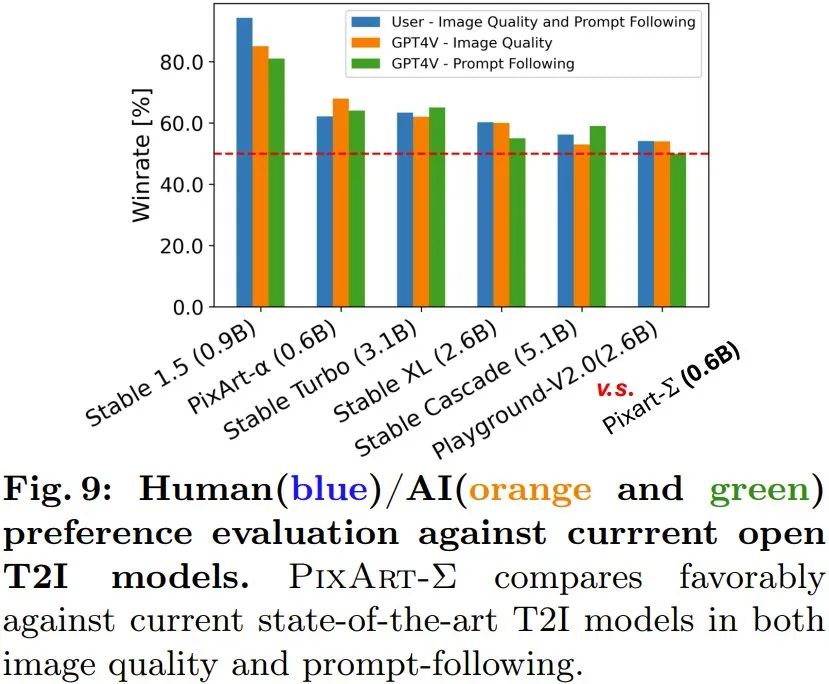
此外,團隊也使用了先進的多模態模型 GPT-4 Vision 來執行 AI 偏好研究。他們的做法是給 GPT-4 Vision 提供兩張圖像,讓它基於圖像品質和圖像 - 文字對齊程度進行投票。結果見圖 9 中的橘色和綠色長條圖,可以看到情況與人類評估基本一致。 團隊也進行了消融研究來驗證各種改進措施的有效性。更多詳情,請訪問原論文。 參考文章:1.https://www.shoufachen.com/Awesome-Diffusion-Transformers/ #
以上是基於DiT,支援4K影像生成,華為諾亞0.6B文生圖模型PixArt-Σ來了的詳細內容。更多資訊請關注PHP中文網其他相關文章!























