

每個人想要的大模型,是真·智能的那種......
這不,Google團隊就做出來了一個強大的「讀屏」AI。
研究人員稱之為ScreenAI,是一種理解使用者介面和資訊圖表的全新視覺語言模型。

論文網址:https://arxiv.org/pdf/2402.04615.pdf
ScreenAI的核心是一種新的螢幕截圖文字表示方法,可以識別UI元素的類型和位置。
研究人員使用Google語言模型PaLM 2-S產生了合成訓練數據,這些數據被用來訓練模型,以回答與螢幕資訊、螢幕導航和螢幕內容摘要相關的問題。值得一提的是,這種方法為提高模型在處理螢幕相關任務時的表現提供了新的想法。

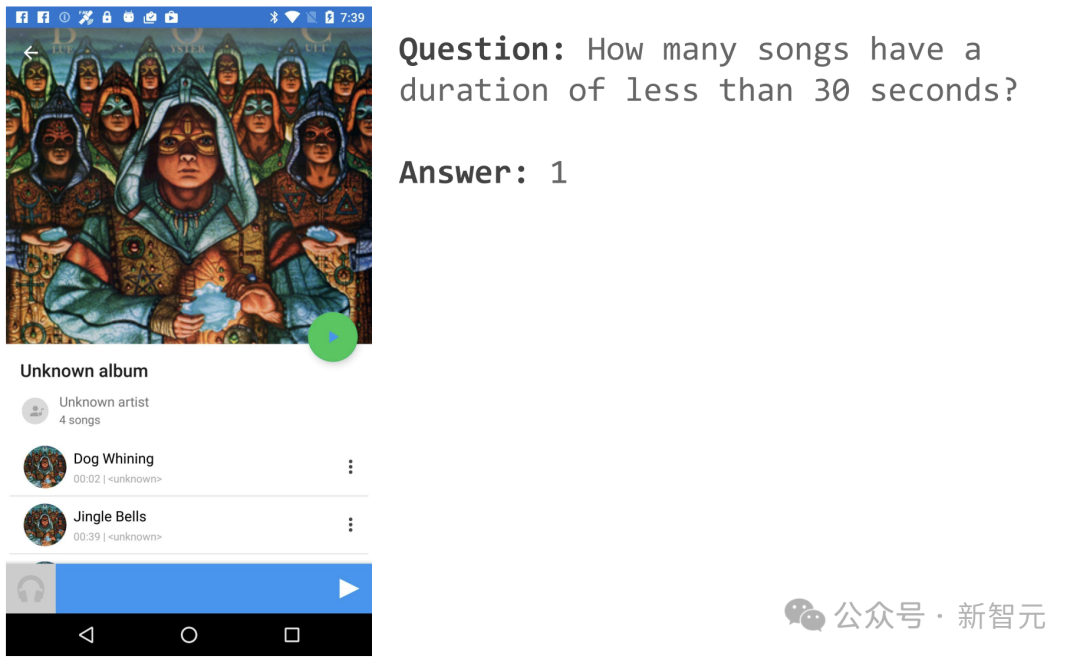
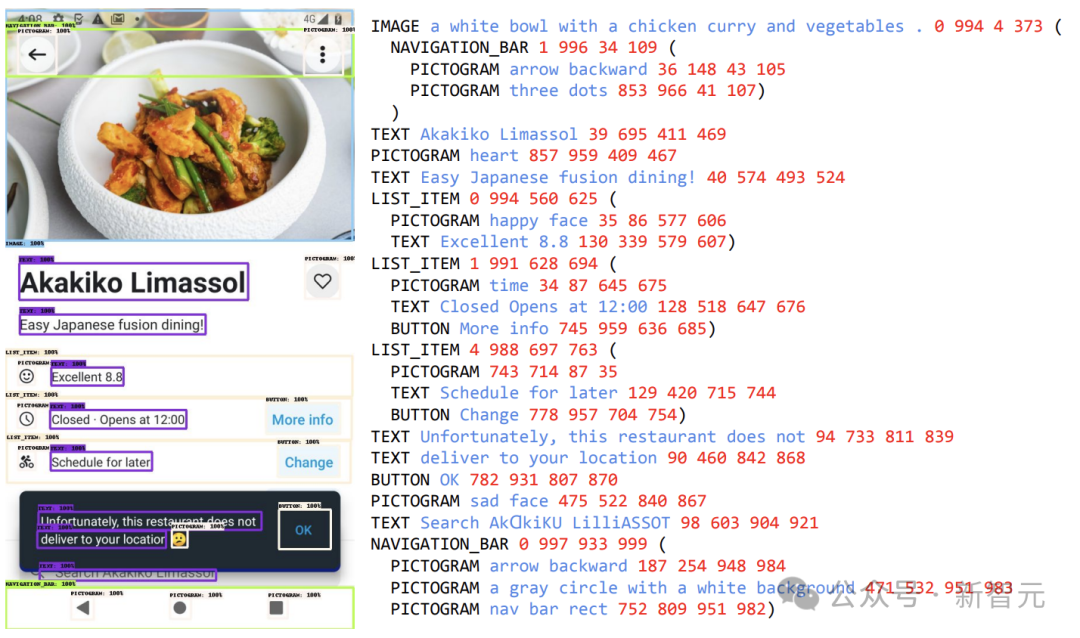
舉個栗子,例如開啟一音樂APP頁面,可以詢問「有幾首歌時長少於30秒」?
ScreenAI便給了簡單的答案:1。
再例如指令ScreenAI開啟選單,就可以選取。
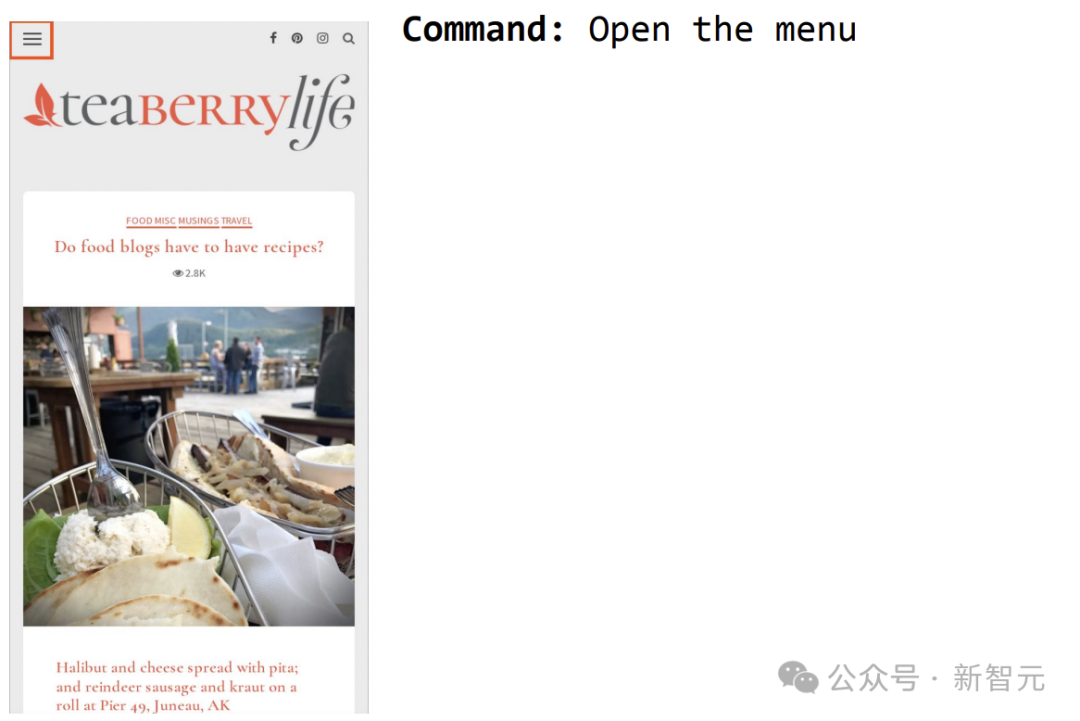
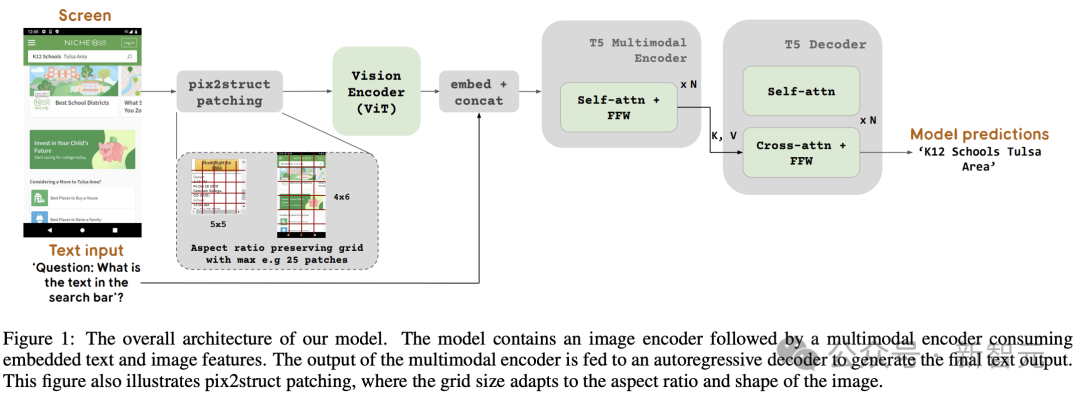
圖1中展示了ScreenAI模型架構。研究人員受到了PaLI系列模型架構(由一個多模態編碼器區塊組成)的啟發。
此編碼器區塊包含一個類似ViT的視覺編碼器和一個消費圖像(consuming image)和文字輸入的mT5語言編碼器,後面接著一個自回歸解碼器。
輸入影像透過視覺編碼器轉換為一系列嵌入,這些嵌入與輸入文字嵌入結合,一起輸入mT5語言編碼器。
編碼器的輸出傳遞給解碼器,產生文字輸出。
這種泛化公式能夠使用相同的模型架構,解決各種視覺和多模態任務。這些任務可以重新表述為文字 圖像(輸入)到文字(輸出)的問題。
與文字輸入相比,影像嵌入構成了多模態編碼器輸入長度的重要部分。
簡而言之,此模型採用影像編碼器與語言編碼器擷取影像與文字特徵,將二者融合後輸入解碼器產生文字。
這種建構方式可以廣泛適用於影像理解等多模態任務。
另外,研究人員也進一步擴展了PaLI的編碼器-解碼器架構,以接受各種影像分塊模式。
原始的PaLI架構只接受固定網格模式的影像區塊來處理輸入影像。然而,研究人員在螢幕相關領域遇到的數據,跨越了各種各樣的分辨率和寬高比。
為了使單一模型能夠適應所有螢幕形狀,有必要使用適用於各種形狀影像的分塊策略。
為此,Google團隊借鑒了Pix2Struct中引入的一種技術,允許根據輸入圖像形狀和預定義的最大塊數,生成任意網格形狀的圖像塊,如圖1所示。
這樣能夠適應各種格式和寬高比的輸入影像,而無需對影像進行填充或拉伸以固定其形狀,從而使模型更通用,能夠同時處理移動設備(即縱向)和桌上型電腦(即橫向)的影像格式。
模型配置
#研究人員訓練了3種不同大小的模型,包含670M、2B和5B參數。
對於670M和2B參數模型,研究人員從視覺編碼器和編碼器-解碼器語言模型的預訓練單峰檢查點開始。
對於5B參數模型,從 PaLI-3的多模態預訓練檢查點開始,其中ViT與基於UL2的編碼器-解碼器語言模型一起訓練。
表1中可以看到視覺與語言模型之間的參數分佈。

#自動資料產生
研究人員稱,模型開發的預訓練階段很大程度上,取決於對龐大且多樣化的資料集的存取。
然而手動標註廣泛的資料集是不切實際的,因此Google團隊的策略是-自動資料生成。
這種方法利用專門的小模型,每個模型都擅長高效且高精度地產生和標記資料。
與手動標註相比,這種自動化方法不僅高效且可擴展,而且還確保了一定程度的資料多樣性和複雜性。
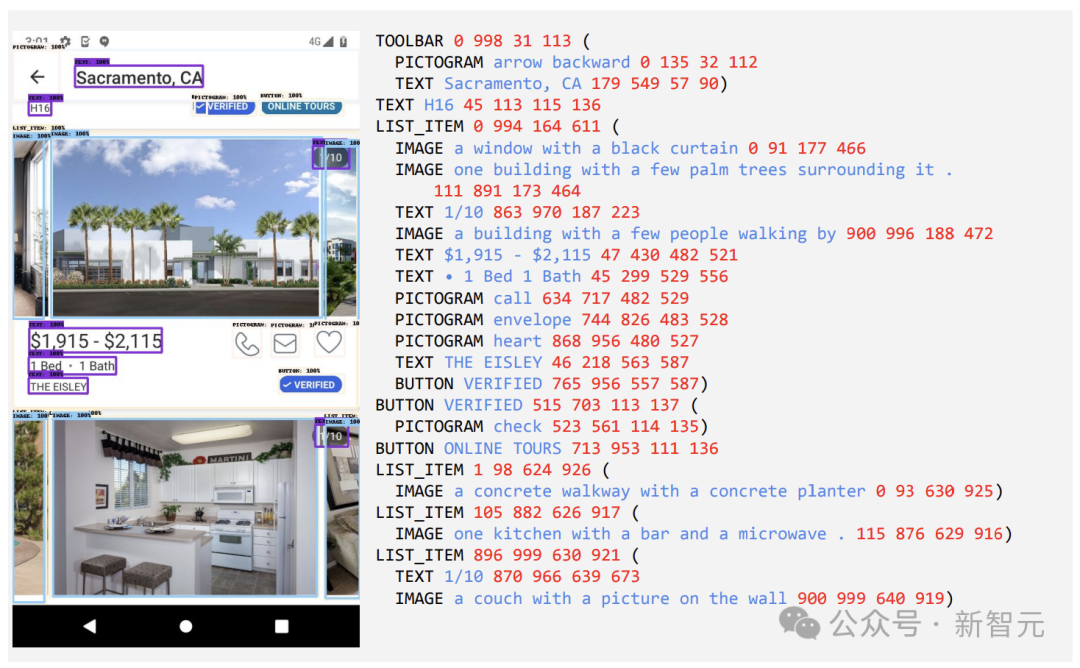
第一步是讓模型全面了解文字元素、各種螢幕元件及其整體結構和層次結構。這種基礎理解對於模型準確解釋各種使用者介面並與之互動的能力至關重要。
這裡,研究人員透過爬蟲應用程式和網頁,從各種裝置(包括桌上型電腦、行動裝置和平板電腦)收集了大量螢幕截圖。
然後,這些螢幕截圖會使用詳細的標籤進行標註,這些標籤描述了UI 元素、它們的空間關係以及其他描述性資訊。
此外,為了給預訓練資料注入更大的多樣性,研究人員也利用語言模型的能力,特別是PaLM 2-S分兩個階段產生QA對。
首先產生先前描述的螢幕模式。隨後,作者設計一個包含螢幕模式的提示,指導語言模型產生合成資料。
經過幾次迭代後,可以確定一個有效產生所需任務的提示,如附錄C所示。
為了評估這些生成回應的質量,研究人員對資料的子集進行了手動驗證,以確保達到預定的品質要求。
此方法在圖2中進行了描述,大幅提升預訓練資料集的深度與廣度。
透過利用這些模型的自然語言處理能力,結合結構化的螢幕模式,便可以模擬各種使用者互動和情境。
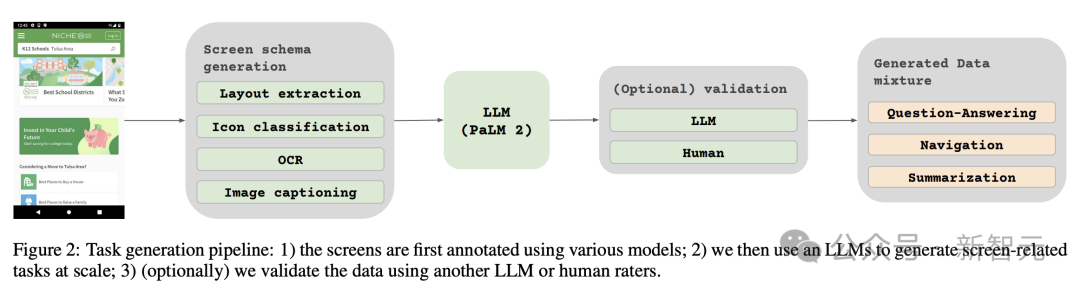
接下來,研究者為模型定義了兩組不同的任務:一組初始的預訓練任務和一組後續的微調任務。
這兩組的差異主要在於兩個面向:
- 真實資料的來源:對於微調任務,標記由人類評估者提供或驗證。對於預訓練任務,標記是使用自監督學習方法推斷的或使用其他模型產生的。
- 資料集的大小:通常預訓練任務包含大量的樣本,因此,這些任務用於透過更擴展的一系列步驟來訓練模型。
表2顯示所有預訓練任務的摘要。
在混合資料中,資料集按其大小按比例加權,每個任務允許的最大權重。

將多模態來源納入多工訓練中,從語言處理到視覺理解和網頁內容分析,使模型能夠有效處理不同的場景,並增強其整體多功能性和性能。

研究人員在微調期間使用各種任務和基準來估計模型的品質。表3總結了這些基準,包括現有的主要螢幕、資訊圖表和文件理解基準。

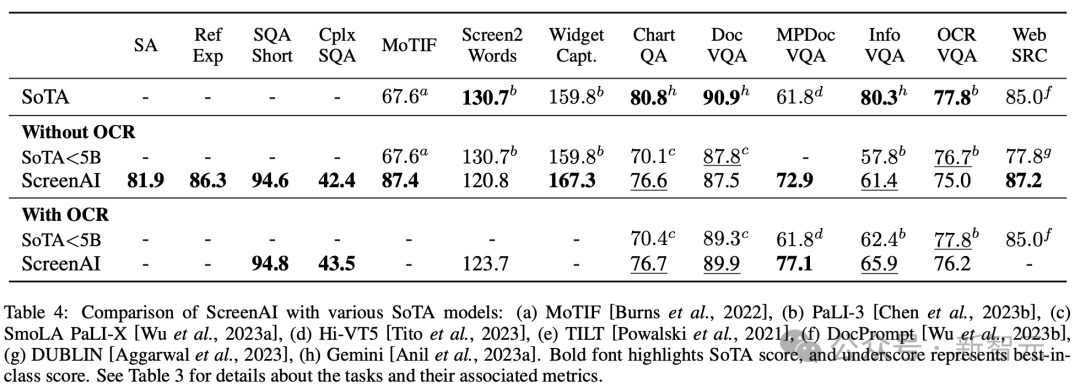
圖4顯示了ScreenAI模型的效能,並將其與各種與螢幕和資訊圖形相關的任務上的最新SOT結果進行了比較。
可以看到,ScreenAI在不同任務上取得的領先效能。
在表4中,研究人員呈現了使用OCR資料的單一任務微調結果。
對於QA任務,增加OCR可以提高效能(例如Complex ScreenQA、MPDocVQA和InfoVQA上高達4.5%)。
然而,使用OCR會稍微增加輸入長度,導致整體訓練速度更慢。它還需要在推理時獲得OCR結果。
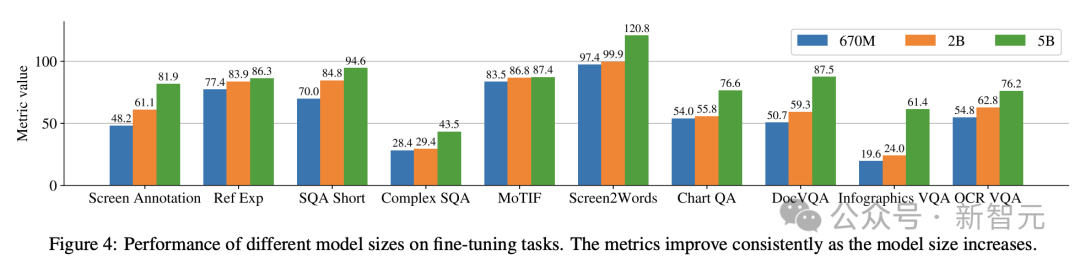
另外,研究人員使用以下模型規模進行了單一任務實驗:6.7億參數、20億參數和50億參數。
在圖4中可以觀察到,對於所有任務,增加模型規模都可以改善效能,在最大規模下的改進還沒有飽和。
對於需要更複雜的視覺文字和算術推理的任務(例如InfoVQA、ChartQA和Complex ScreenQA),20億參數模型和50億參數模型之間的改進明顯大於6.7億參數模型和20億參數模型。
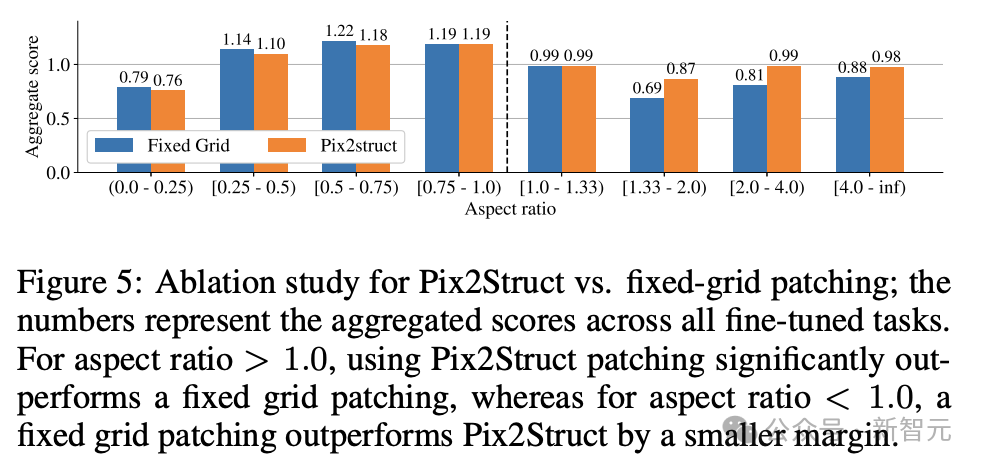
最後,圖5顯示了,對於長寬比>1.0的影像(橫向模式影像),pix2struct分割策略明顯優於固定網格分割。
對於縱向模式影像,趨勢相反,但固定網格分割僅稍微好一些。
鑑於研究人員希望ScreenAI模型能夠在不同長寬比的圖像上使用,因此選擇使用pix2struct分割策略。
Google研究人員表示,ScreenAI模型還需要在一些任務上進行更多研究,以縮小與GPT-4和Gemini等更大模型的差距。
以上是谷歌發布最新「讀屏」AI! PaLM 2-S自動產生數據,多項理解任務刷新SOTA的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















