

在當今科技日新月異的浪潮中,人工智慧(Artificial Intelligence, AI)、機器學習(Machine Learning, ML)與深度學習(Deep Learning, DL)如同璀璨星辰,引領著資訊科技的新浪潮。這三個詞彙經常出現在各種前沿討論和實際應用中,但對於許多初涉此領域的探索者來說,它們的具體含義及相互之間的內在聯繫可能仍籠罩著一層神秘面紗。
那讓我們先來看看這張圖。

可以看出,深度學習、機器學習和人工智慧之間存在著緊密的關聯和遞進關係。深度學習是機器學習的一個特定領域,而機器學習則是人工智慧的重要組成部分。這些領域之間的連結與相互促進,使得人工智慧技術不斷得以發展和改進。
人工智慧(Artificial Intelligence, AI)是一個廣泛的概念,其主要目標在於開發能夠模擬、延伸甚至超越人類智慧的運算系統。它在許多領域都有具體應用,例如:
這些高階技術都圍繞著「模擬人類智慧」的核心概念展開研究和應用。它們專注於不同感知維度(如視覺、聽覺、思考邏輯等)的開發,共同推動了人工智慧技術的不斷發展和進步。
機器學習(Machine Learning, ML)是人工智慧(AI)領域中至關重要的一個分支。它透過利用各種演算法,讓電腦系統能夠自動從資料中學習規律和模式,藉此進行預測和決策,從而增強和擴展人類智慧的能力。
例如,在訓練一個貓識別模型時,機器學習處理的過程如下:
常用的10大機器學習演算法有:決策樹、隨機森林、邏輯迴歸、SVM、樸素貝葉斯、K最近鄰演算法、K均值演算法、Adaboost演算法、神經網路、馬爾科夫等。
深度學習(Deep Learning, DL)是機器學習的一種特殊形式,它透過深層神經網路結構模擬人腦處理資訊的方式,從而自動提取資料中的複雜特徵表示。
例如,在訓練一個貓咪辨識模型時,深度學習處理的過程如下:
(1) 資料預處理與準備:
(2) 模型設計與建構:
(3) 初始化參數與設定超參數:
(4) 前向傳播:
(5) 損失函數與反向傳播:
(6) 最佳化與參數更新:
(7) 驗證與評估:
(8) 訓練完成與測試:
深度學習和機器學習的區別在於:
#機器學習演算法通常依賴人為設計的特徵工程,即根據問題背景知識預先抽取關鍵特徵,然後基於這些特徵建立模型並進行最佳化求解。
深度學習則採取了端到端的學習方式,透過多層非線性變換自動產生高級抽象特徵,並且這些特徵是在整個訓練過程中不斷優化得到的,無需手動選擇和構造特徵,更接近人類大腦的認知處理方式。
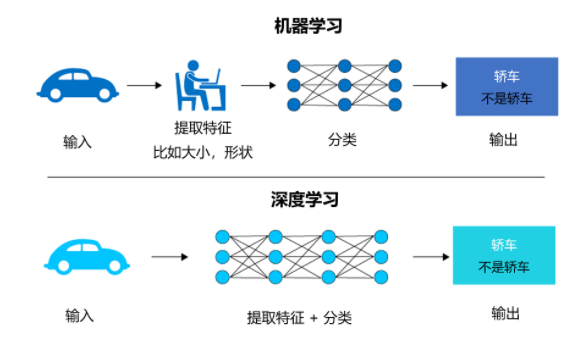
舉個例子,如果你要寫一個軟體讓它去識別一輛轎車,如果使用機器學習,你需要人為提取汽車的特徵,比如大小和形狀等;而如果你使用深度學習,那麼人工智慧神經網路會自行提取這些特徵,不過它需要大量的標識為轎車的圖片來進行學習。
機器學習在指紋辨識、特徵物件偵測等領域的應用基本上達到了商業化的要求。
深度學習主要應用於文字辨識、臉部技術、語意分析、智慧監控等領域。目前在智慧硬體、教育、醫療等產業也在快速佈局。
機器學習演算法在小樣本情況下也能展現出較好的性能,對於一些簡單任務或者特徵易於提取的問題,較少的數據即可達到滿意效果。
深度學習通常需要大量的標註資料來訓練深層神經網絡,其優勢在於能從原始資料直接學習複雜的模式和表示,尤其當資料規模增大時,深度學習模型的效能提升更為顯著。
訓練階段,由於深度學習模型的層次更多、參數數量龐大,故訓練過程往往較為耗時,需要高效能運算資源的支持,如GPU集群。
相較之下,機器學習演算法(尤其是那些輕量級的模型)在訓練時間和運算資源需求上通常較小,更適合於快速迭代和實驗驗證。
以上是一文搞懂:AI、機器學習與深度學習的連結與區別的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















