

「絕不是簡單的摳圖。」
ControlNet作者最新推出的研究受到了一波高度關注—
給一句prompt,用Stable Diffusion可以直接產生單一或多個透明圖層(PNG)!
例如來一句:
頭髮凌亂的女性,在臥室裡。
Woman with messy hair, in the bedroom.

#可以看到,AI不僅產生了符合prompt的完整圖像,就連背景和人物也能分開。
而且把人物PNG圖像放大細看,髮絲那叫一個根根分明。

再看一個例子:
燃燒的柴火,在一張桌子上,在鄉下。
Burning firewood, on a table, in the countryside.

#同樣,放大「燃燒的火柴」的PNG,就連火焰週邊的黑煙都能分離出來:

這就是ControlNet作者提出的新方法-LayerDiffusion,允許大規模預訓練的潛在擴散模型(Latent Diffusion Model)產生透明影像。

值得再強調一次的是,LayerDiffusion絕不是摳圖那麼簡單,重點在於生成。
如網友所說:
這是現在動畫、影片製作最核心的工序之一。這一步能夠過,可以說SD一致性就不再是問題了。
還有網友以為類似這樣的工作並不難,只是「順便加上alpha通道」的事,但令他意外的是:
結果這麼久才有出來的。
那麼LayerDiffusion到底是如何實現的呢?
LayerDiffusion的核心,是一種叫做潛在透明度(latent transparency)的方法。
簡單來說,它可以允許在不破壞預訓練潛在擴散模型(如Stable Diffusion)的潛在分佈的前提下,為模型添加透明度。
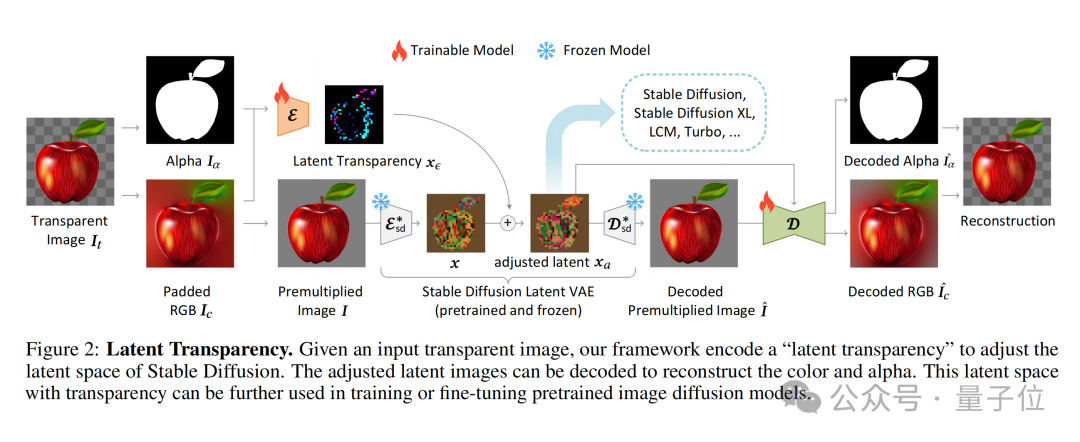
在具體實現上,可以理解為在潛在圖像上添加一個精心設計過的小擾動(offset),這種擾動被編碼為一個額外的通道,與RGB通道一起構成完整的潛在圖像。
為了實現透明度的編碼和解碼,作者訓練了兩個獨立的神經網路模型:一個是潛在透明度編碼器(latent transparency encoder),另一個是潛在透明度解碼器(latent transparency decoder)。
編碼器接收原始影像的RGB通道和alpha通道作為輸入,將透明度資訊轉換為潛在空間中的一個偏移量。
而解碼器則接收調整後的潛在影像和重建的RGB影像,從潛在空間中提取出透明度訊息,以重建原始的透明影像。
為了確保添加的潛在透明度不會破壞預訓練模型的潛在分佈,作者提出了一種「無害性」(harmlessness)度量。
這個測量值透過比較原始預訓練模型的解碼器對調整後潛在影像的解碼結果與原始影像的差異,來評估潛在透明度的影響。
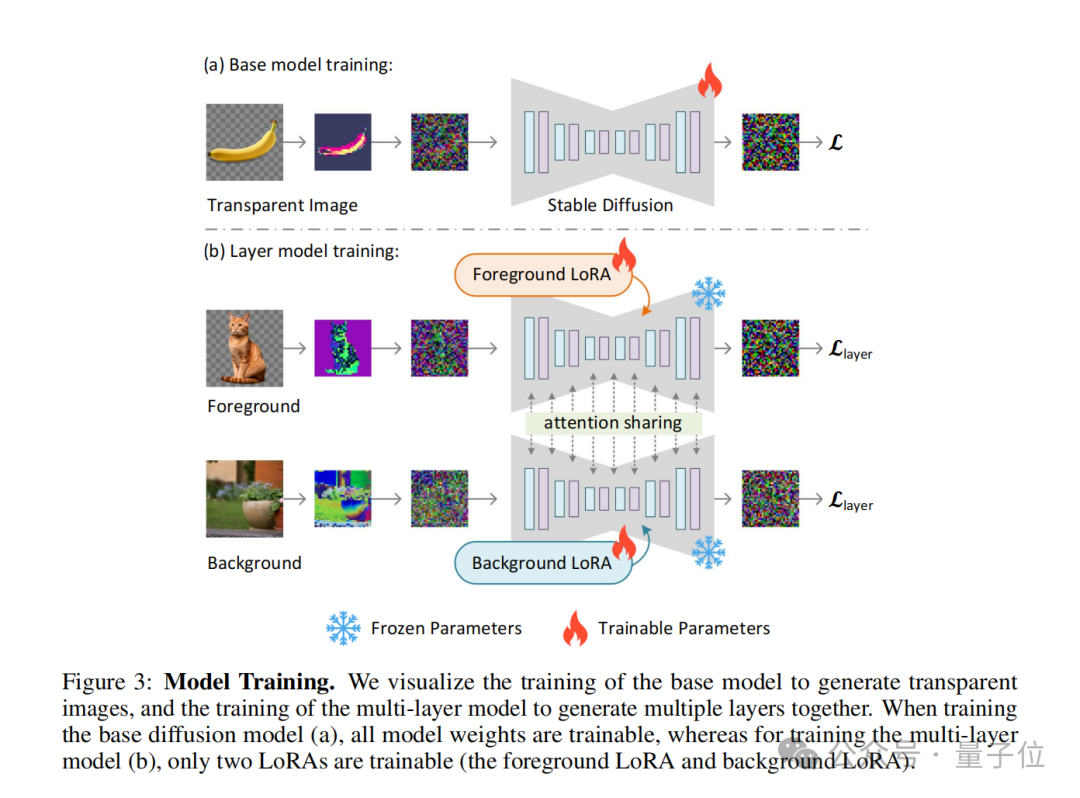
在訓練過程中,作者也使用了一個聯合損失函數(joint loss function),它結合了重建損失( reconstruction loss)、身分損失(identity loss)和判別器損失(discriminator loss)。
它們的作用分別是:
透過此方法,任何潛在擴散模型都可以轉換為透明影像產生器,只需對其進行微調以適應調整後的潛在空間。

潛在透明度的概念還可以擴展到生成多個透明圖層,以及與其他條件控制系統結合,實現更複雜的影像生成任務,如前景/背景條件產生、聯合圖層產生、圖層內容的結構控制等。



值得一提的是,作者也展示如何把ControlNet引入進來,豐富LayerDiffusion的功能:

至於LayerDiffusion與傳統摳圖上的區別,我們可以簡單歸整為以下幾點。
原生生成 vs. 後處理
LayerDiffusion是一種原生的透明圖像生成方法,它直接在生成過程中考慮並編碼透明度資訊。這意味著模型在生成圖像的同時就創建了透明度通道(alpha channel),從而產生了具有透明度的圖像。
傳統的摳圖方法通常涉及先生成或獲取一個圖像,然後透過圖像編輯技術(如色鍵、邊緣檢測、用戶指定的遮罩等)來分離前景和背景。這種方法通常需要額外的步驟來處理透明度,並且可能在複雜背景或邊緣產生不自然的過渡。
潛在空間操作 vs. 像素空間操作
#LayerDiffusion在潛在空間(latent space)中進行操作,這是一個中間表示,它允許模型學習並產生更複雜的圖像特徵。透過在潛在空間中編碼透明度,模型可以在生成過程中自然地處理透明度,而不需要在像素層級上進行複雜的計算。
傳統的摳圖技術通常在像素空間中進行,這可能涉及對原始影像的直接編輯,如顏色替換、邊緣平滑等。這些方法可能在處理半透明效果(如火焰、煙霧)或複雜邊緣時遇到困難。
資料集和訓練
LayerDiffusion使用了一個大規模的資料集進行訓練,這個資料集包含了透明影像對,使得模型能夠學習到生成高品質透明影像所需的複雜分佈。
傳統的摳圖方法可能依賴較小的資料集或特定的訓練集,這可能限制了它們處理多樣化場景的能力。
靈活性和控制
LayerDiffusion提供了更高的靈活性和控制能力,因為它允許使用者透過文字提示(text prompts)來指導圖像的生成,並且可以生成多個圖層,這些圖層可以被混合和組合以創建複雜的場景。
傳統的摳圖方法可能在控制方面更為有限,尤其是在處理複雜的影像內容和透明度時。
品質比較
用戶研究顯示,LayerDiffusion產生的透明圖像在大多數情況下(97%)被用戶偏好,這表明其產生的透明內容在視覺上與商業透明資產相當,甚至可能更優。
傳統的摳圖方法可能在某些情況下無法達到相同的質量,尤其是在處理具有挑戰性的透明度和邊緣時。
總而言之,LayerDiffusion提供的是一種更先進且靈活的方法來產生和處理透明影像。
它在生成過程中直接編碼透明度,並且能夠產生高品質的結果,這在傳統的摳圖方法中是很難實現的。
正如我們剛才提到的,這項研究的作者之一,正是大名鼎鼎的ControlNet的發明人-張呂敏。
他本科就畢業於蘇州大學,大一的時候就發表了與AI繪畫相關的論文,本科期間更是發了10篇頂會一作。
目前張呂敏在史丹佛大學攻讀博士,但他為人可以說是非常低調,連Google Scholar都沒有註冊。
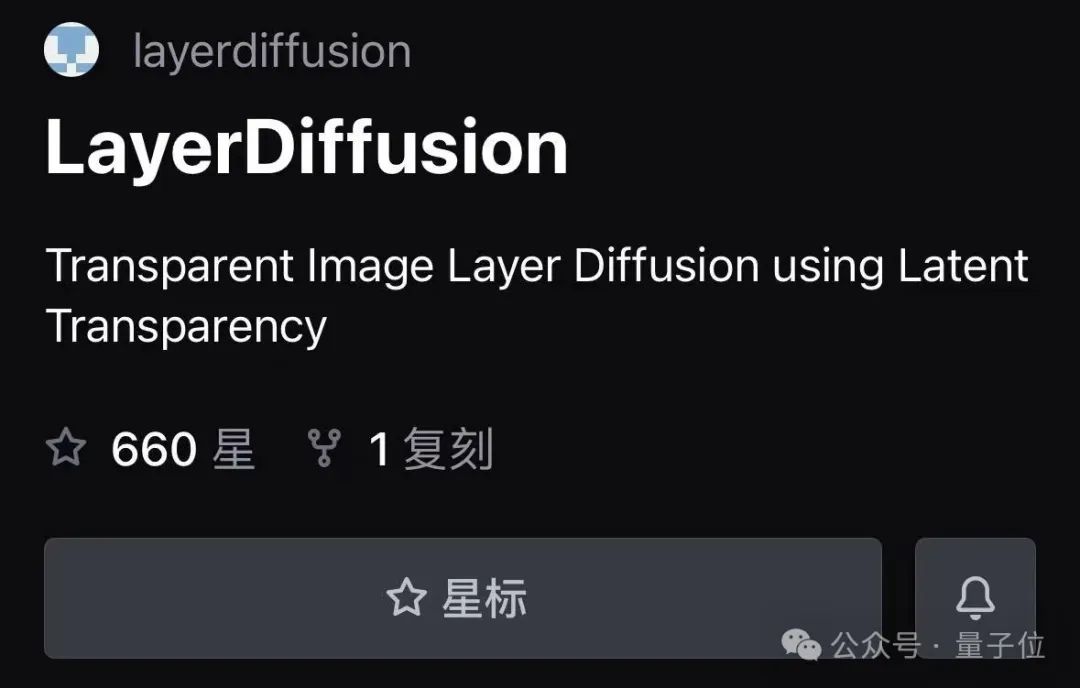
就目前來看,LayerDiffusion在GitHub中並沒有開源,但即便如此也擋不住大家的關注,已經斬獲660顆星。
畢竟張呂敏也被網友調侃為“時間管理大師”,對LayerDiffusion感興趣的小伙伴可以提前mark一波了。
以上是ControlNet作者新作:AI繪畫能分圖層了!專案未開源就斬獲660 Star的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















