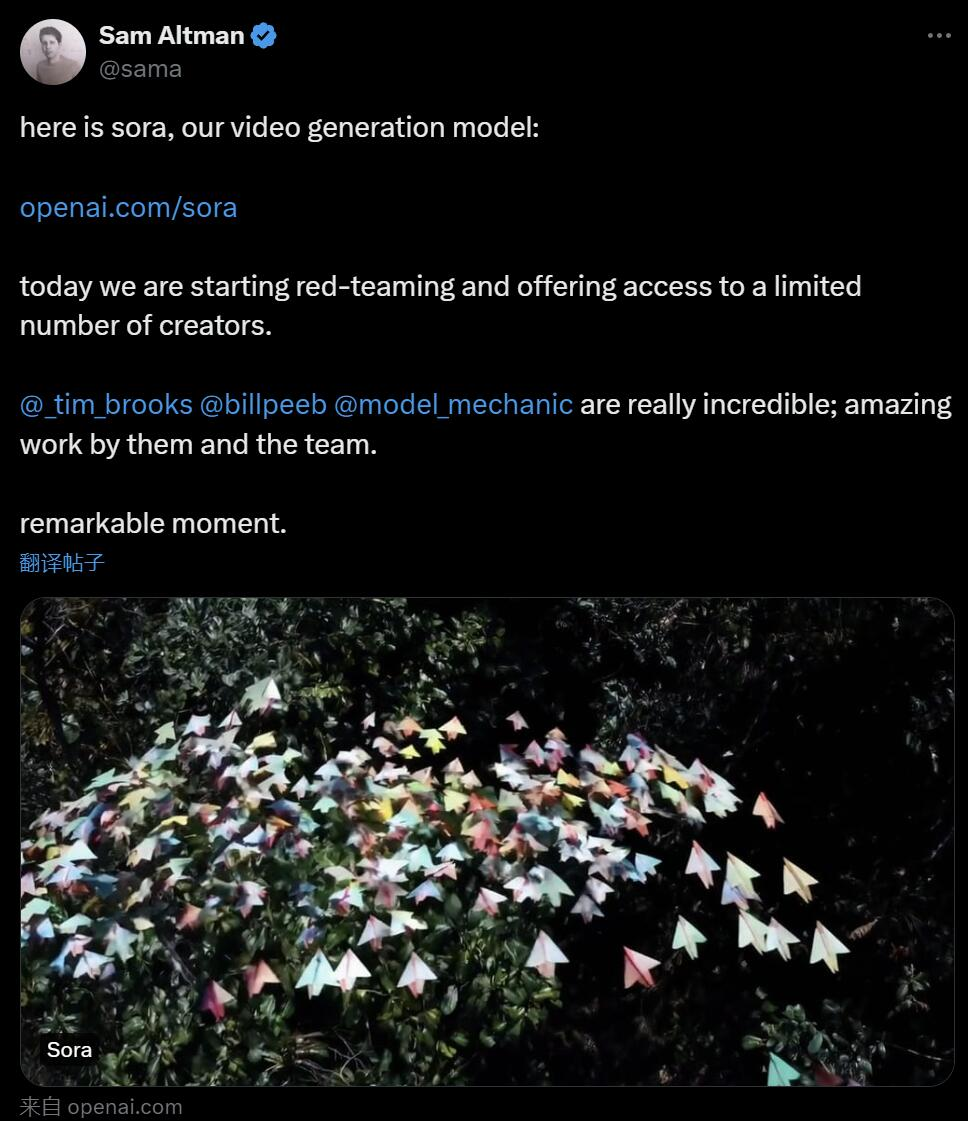
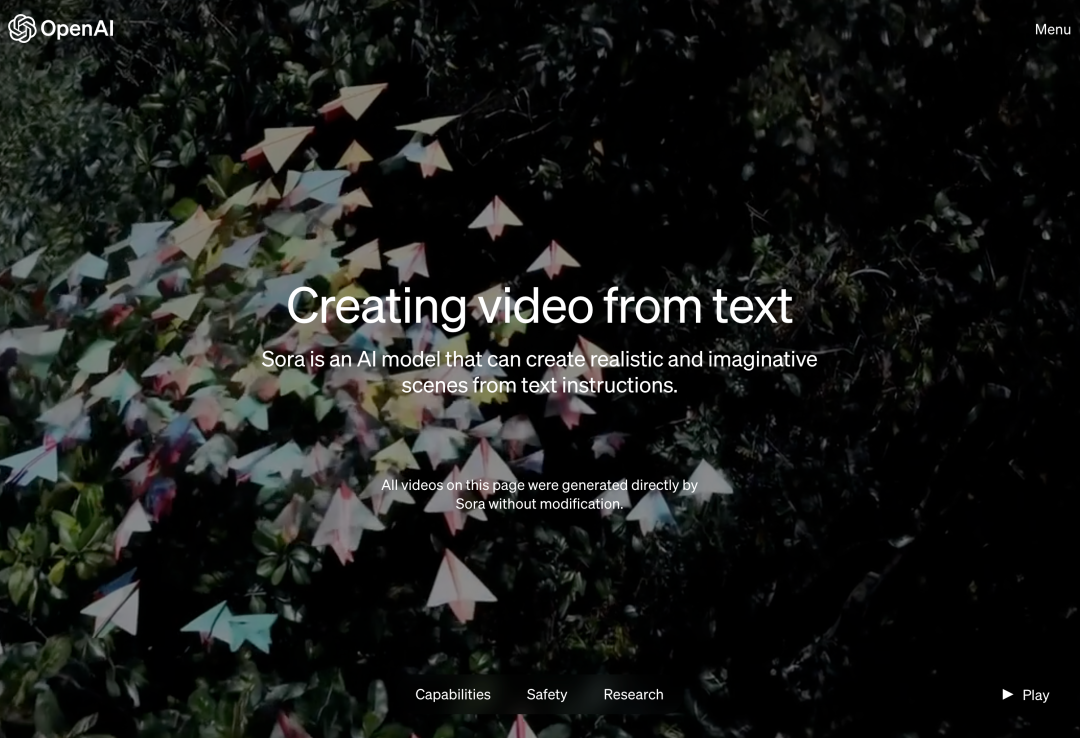
北京時間今天凌晨,OpenAI 正式發布了文字到影片生成模型 Sora,繼 Runway、Pika、Google和 Meta 之後,OpenAI 終於加入影片生成領域的戰爭。
山姆・奧特曼的消息放出後,看到 OpenAI 工程師第一時間展示的 AI 生成視頻效果,人們紛紛表示感嘆:好萊塢的時代結束了?
OpenAI 聲稱,如果給定一段簡短或詳細的描述或一張靜態圖片,Sora 就能產生類似電影的1080p 場景,其中包含多個角色、不同類型的動作和背景細節。
Sora 有哪些特別之處呢?它對語言有著深刻的理解,能夠準確地解釋 prompt 並產生吸引人的字符來表達充滿活力的情感。同時,Sora 不僅能夠了解使用者在 prompt 中提出的要求,還能 get 到在物理世界中的存在方式。
在官方部落格中,OpenAI 提供了許多Sora 生成的影片範例,展示了令人印象深刻的效果,至少與先前出現過的文字產生影片技術相比是這樣。
#對於初學者來說,Sora 可以產生各種風格的影片(例如,真實感、動畫、黑白),最長可達一分鐘—— 比大多數文本到視頻模型要長得多。
這些影片保持了合理的連貫性,它們並不總是屈服於所說的「人工智慧怪異」,例如物體朝物理上不可能的方向移動。

例如輸入 prompt:加州淘金熱時期的歷史鏡頭。

輸入 prompt:玻璃球的特寫視圖,裡面有禪宗花園。球體中有一個小矮人正在沙上創造圖案。

輸入prompt:一位24 歲女性眨眼的極端特寫,在魔法時刻站在馬拉喀什,70 毫米拍攝的電影,景深,鮮豔的色彩,電影。

輸入 prompt:穿過東京郊區的火車窗外的倒影。

輸入 promot:賽博龐克背景下機器人的生活故事。

但 OpenAI 承認,目前的模型也有弱點。它可能難以準確模擬複雜場景中的物理現象,也可能無法理解特定的因果關係。該模型還可能混淆提示的空間細節,例如混淆左和右,並可能難以精確描述隨時間發生的事件,例如跟隨特定的攝影機軌跡。
例如他們發現,在生成的過程中動物和人會自發性出現,尤其是在包含許多實體的場景中。
在下面這個例子中,Prompt 本來是「五隻灰狼幼崽在草叢環繞的偏僻碎石路上嬉戲追逐。幼狼們奔跑著、跳躍著,互相追逐著、咬著,嬉戲著。」但所產生的這種「複製貼上」的畫面很容易讓人想起某些神異鬼怪傳說:

還有下面這個例子,吹蠟燭之前和吹蠟燭之後,火苗沒有絲毫變化,透露出一種詭異:

對Sora 背後的模型細節,我們所知甚少。根據 OpenAI 博客,更多的資訊將在後續的技術論文中公佈。
部落格中透露了一些基本資訊:Sora 是一種擴散模型,它產生的影片一開始看起來像靜態噪音,然後透過多個步驟去除噪音,逐步轉換影片。
Midjourney 和 Stable Diffusion 的圖像和視訊產生器同樣基於擴散模型。但我們可以看出,OpenAI Sora 生成影片的品質好得多。 Sora 感覺像是創建了真實的視頻,而以往這些競爭對手的模型則感覺像是 AI 生成圖像的定格動畫。
Sora 可以一次生成整個視頻,也可以擴展生成的視頻,使其更長。透過讓模型一次預見多幀畫面,OpenAI 解決了一個具有挑戰性的問題,即確保主體即使暫時離開視線也能保持不變。
與 GPT 模型類似,Sora 也使用了 transformer 架構,從而實現了卓越的擴展性能。
OpenAI 將視訊和圖像表示為稱為 patch 的較小資料單元的集合,每個 patch 類似於 GPT 中的 token。透過統一資料表示方式,OpenAI 能夠在比以往更廣泛的視覺資料上訓練擴散 transformer,包括不同的持續時間、解析度和寬高比。
Sora 建立在過去 DALL・E 和 GPT 模型的研究基礎上。它採用了 DALL・E 3 中的重述技術,即為視覺訓練資料產生高度描述性的字幕。因此,該模型能夠在生成的影片中更忠實地遵循使用者的文字提示。
除了能夠僅根據文字說明生成視頻外,該模型還能根據現有的靜態圖像生成視頻,並準確、細緻地對圖像內容進行動畫處理。該模型還能提取現有視頻,並對其進行擴展或填充缺失的幀。
參考連結:https://openai.com/sora
#
以上是春節大禮包! OpenAI首個影片生成模式發布,60秒高畫質大作,網友已嘆服的詳細內容。更多資訊請關注PHP中文網其他相關文章!