

通常引用開源軟體的模式是引入開源軟體的動態庫或jar包,因此在漏洞檢測時漏洞誤報率會非常的低,但對在Linux內核卻有所不同,由於Linux內核功能模組非常的豐富和龐大,實際使用時會根據業務需求進行相應的裁剪,因此如何在該場景下實現漏洞的精準檢測,降低漏洞檢測的誤報率就尤為突出。
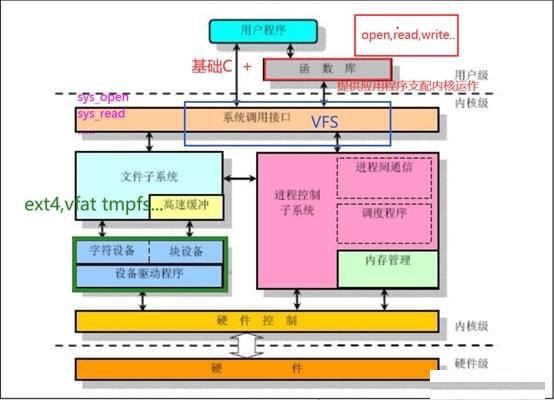
Linux核心結構:
Linux核心由七個部分構成,每個不同的部分又有多個核心模組組成,結構框圖如下:
Linux裁切場景分析:
透過分析Linux核心原始碼可以看到不同目錄中存放著不同模組的實作程式碼,同時在編譯時可以config中配置的資訊來控制哪些模組編譯到最終的二進位中,哪些模組被裁切掉,例如以IPV6模組為例,控制該模組的配置名稱為CONFIG_IPV6,如果該配置項為設定為y,則表示該功能模組未被編譯到最終的二進位檔案中,如下所示:

如果該功能模組被裁剪了,即使該漏洞沒有被補丁修復,那麼該功能模組中存在的漏洞在二進制中也是不受影響的,因此和IPV6相關的漏洞在漏洞檢測時就報告中應該明顯的標識出不受該漏洞的影響,如CVE-2013-0343(Linux kernel 3.8之前版本內的net/ipv6/addrconf.c中的函數ipv6_create_tempaddr沒有正確處理IPv6臨時位址產生問題,可允許遠端攻擊者透過ICMPv6 Router Advertisement (RA) 訊息,造成拒絕服務,然後取得敏感資訊。)。
業界二進位SCA工具不能偵測的原因分析:
#為什麼目前業界通常的二進位SCA工具無法做到精準檢測,原因是因為業界二進位SCA工具是基於檢測到的開源軟體名稱和版本號來關聯出已知漏洞清單的,而這種透過裁切功能模組的方法來應用Linux內核,開源軟體名稱和版本號碼是不會改變的,因此工具就無法精確的檢測出來了。
二進位SCA工具如何實現該功能:
要實現Linux核心裁切場景下的已知漏洞精準偵測,二進位SCA工具必須在原先偵測開源軟體名稱和版本號的基礎上,需要實現更新細顆粒度的偵測技術,基於原始碼檔案顆粒度、函數顆粒度的偵測能力,從而實現裁剪場景下已知漏洞的精準檢測,也就是可以知道哪些程式碼被編譯到最終的二進位檔案中,哪些程式碼沒有參與編譯。同時漏洞庫也必須實現對細顆粒維度的支持,即漏洞資訊必須精準定位是由哪些文件和函數中的程式碼片段引入的。
以CVE-2013-0343為例,透過分析漏洞描述資訊和Linux核心原始碼,可以取得到該漏洞和下列這些位置程式碼相關的定位資訊:
"CVE-2013-0343": {
"net/ipv6/addrconf.c": [
“addrconf_add_ifaddr”,
“addrconf_dad_begin”,
“addrconf_dad_stop”,
“addrconf_dad_work”,
“addrconf_del_ifaddr”,
“addrconf_prefix_rcv”,
“addrconf_verify_rtnl”,
“addrconf_verify_work”,
“inet6_addr_add”,
“inet6_addr_del”,
“inet6_addr_modify”,
“inet6_rtm_deladdr”,
“inet6_rtm_newaddr”,
“inet6_set_iftoken”,
“inet6_set_link_af”,
“ipv6_create_tempaddr”,
“manage_tempaddrs”
]
}
總結
基於如果引入漏洞的源代碼沒有參與編譯出二進制,那麼編譯出來的二進制也就是不存在該漏洞的原理;因此只要二進制SCA工具能檢測出上述位置的源代碼沒有參與編譯出最終的vmlinux二進位文件,那麼此vmlinux文件就不受CVE-2013-0343漏洞的影響。
二元SCA工具要想更好的輔助安全人員實現安全審計、降低漏洞檢測的誤報率,必須朝著更細顆粒度的檢測維度發展,而不僅僅停留在開源軟體的層面,同時對漏洞庫的要求也需要向細顆粒度的精準資訊提出的挑戰。
以上是精準偵測Linux核心漏洞介紹的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















