

HuggingFace是最熱門的機器學習開源社區,擁有30萬個不同的機器學習模型和10萬個可用的應用程式。
如果HuggingFace上這30萬個模型,可以自由組合,共同完成新的學習任務,那會是什麼樣的畫面?
其實在HuggingFace問世的2016年,南京大學週志華教授就提出了「學件」(Learnware)概念,描繪了這樣的藍圖。
最近,南京大學週志華教授團隊推出了一個這樣的平台-北冥塢。
網址:https://bmwu.cloud/
#北冥塢不僅提供給科研人員和使用者上傳自己的模型,還能依使用者需求進行模式配對與協作融合,以有效率處理學習任務。

論文地址:https://arxiv.org/abs/2401.14427
北冥塢系統倉庫:https://www.gitlink.org.cn/beimingwu/beimingwu
科學研究工具包倉庫:https://www.gitlink.org.cn/beimingwu/learnware
這個平台最大的特點就是引入了學件(Learnware)系統,從而突破性地實現了針對使用者需求的模型自適應匹配與協作能力。
學件由機器學習模型和描述模型的規約構成,即「學件 = 模型 規約」。
學件的規約由「語意規約」和「統計規約」兩部分組成:
學件的規約刻畫了模型的能力,使得模型能夠在未來用戶事先對學件一無所知的情況下被充分識別並復用,以滿足用戶需求。
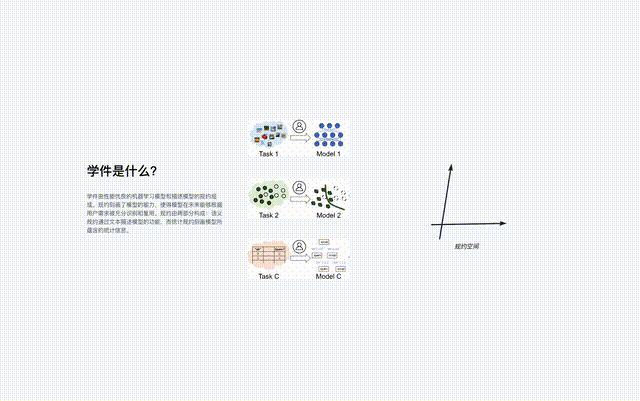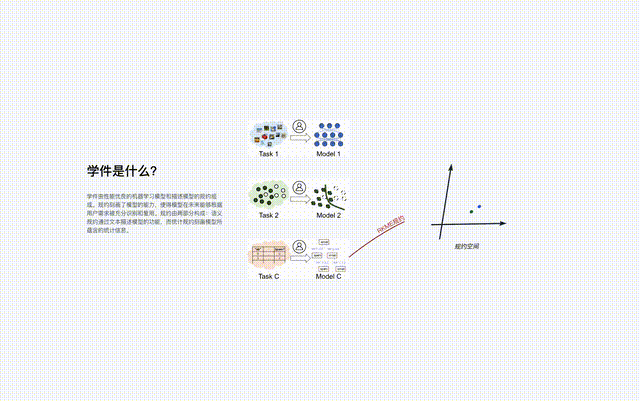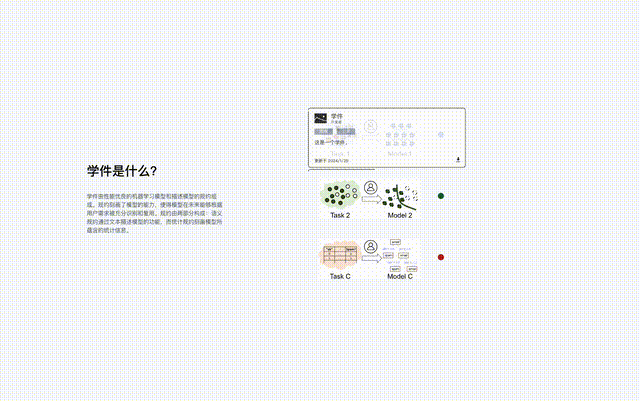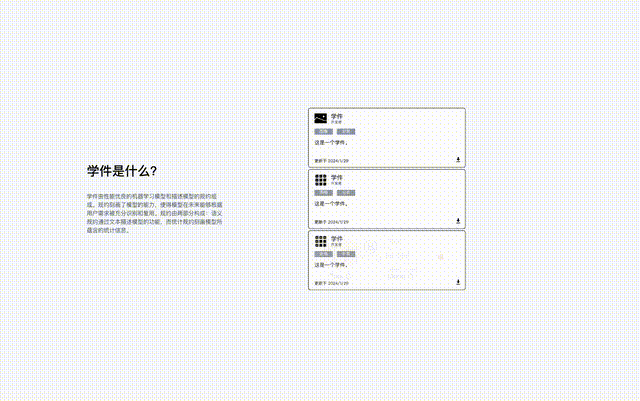
規約是學件基座系統的核心元件,串連了系統中關於學件的全部流程,包括學件上傳、組織、查搜、部署與復用。
就像《天龍八部》中的燕子塢由許多小島組成一樣,北冥塢中的規約也像一個個的小島。
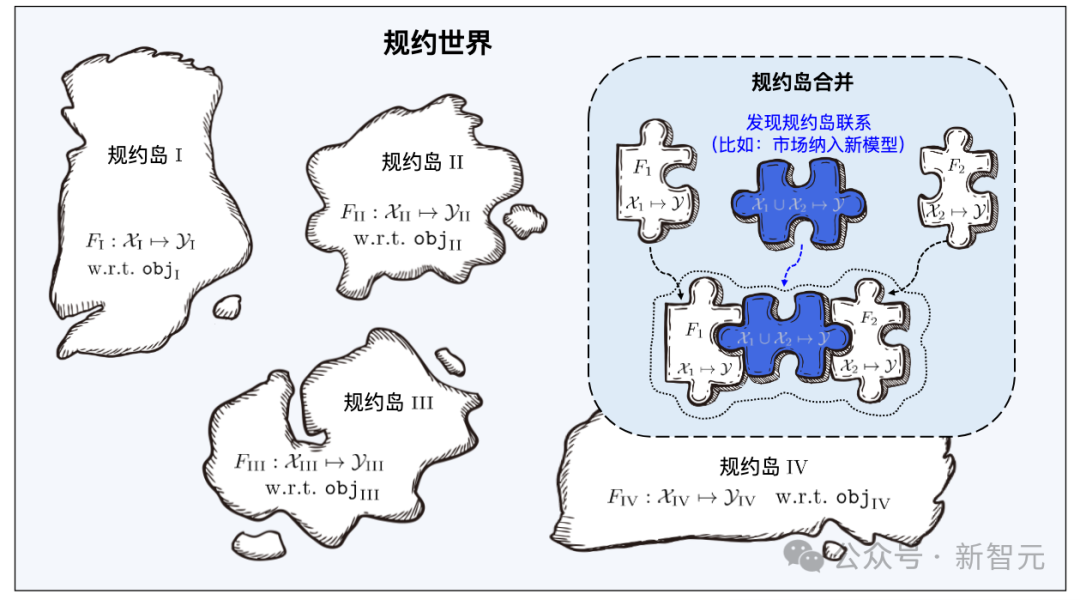
來自不同特徵/標記空間的學件,構成眾多的規約島嶼,所有規約島嶼共同構成學件基座系統中的規約世界。在規約世界中,如果能夠發現並建立不同島嶼之間的聯繫,那麼相對應的規約島嶼將可以進行合併。
在學件範式下,世界各地的開發者可分享模型至學件基座系統,系統透過有效查搜和復用學件幫助使用者高效解決機器學習任務,而無需從零開始建立機器學習模型。
北冥塢是學件的第一個系統性開源實現,為學件相關研究提供了初步科研平台。
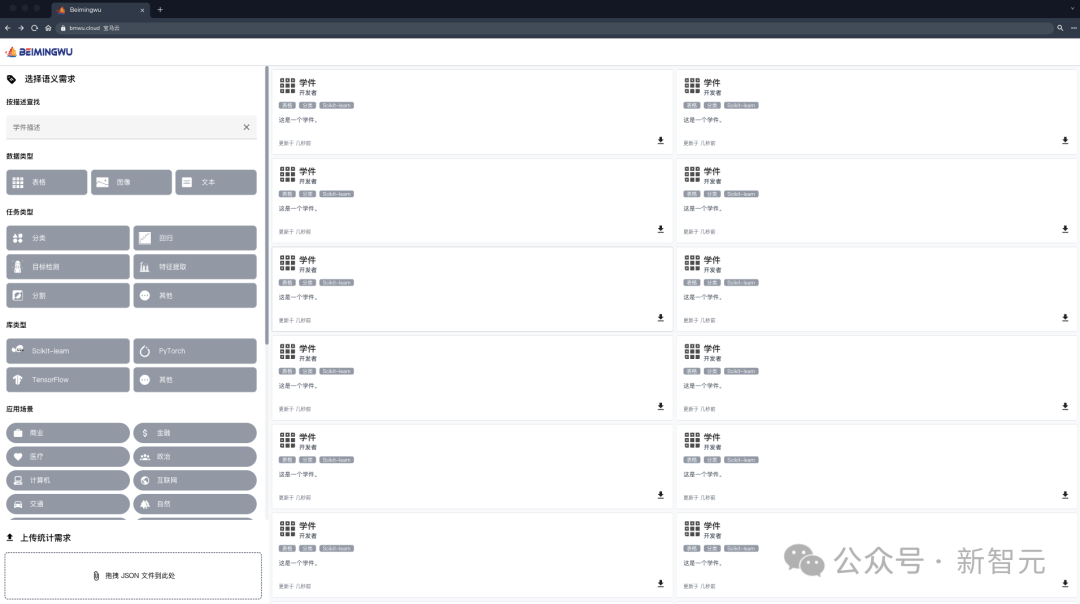
有分享意願的開發者可自由提交模型,學件塢協助產生規約形成學件存放在學件塢中,開發者在這個過程中無需向學件塢洩漏自己的訓練資料。
未來的使用者可以透過向學件塢提交需求,在學件塢協助下查搜復用學件來完成自己的機器學習任務,且使用者可以不向學件塢洩漏自有資料。
而且以後,在學件塢擁有數以百萬計的學件後,將可能出現「湧現」行為:以往沒有專門開發過模型的機器學習任務,可能透過複用若干個現有學件而解決。
機器學習在許多領域取得了巨大成功,但依然面臨著諸多問題,例如需要大量的訓練資料和高超的訓練技巧、持續學習的困難、災難性遺忘的風險以及資料隱私/所有權的洩漏等。
雖然上述每一個問題都有相應的研究,但由於問題之間是相互耦合的,在解決其中一個問題時,可能會導致其他問題變得更加嚴重。
學件基座系統期望透過一個整體框架,同時解決上述諸多問題:
如下圖所示,系統工作流程分為以下兩個階段:
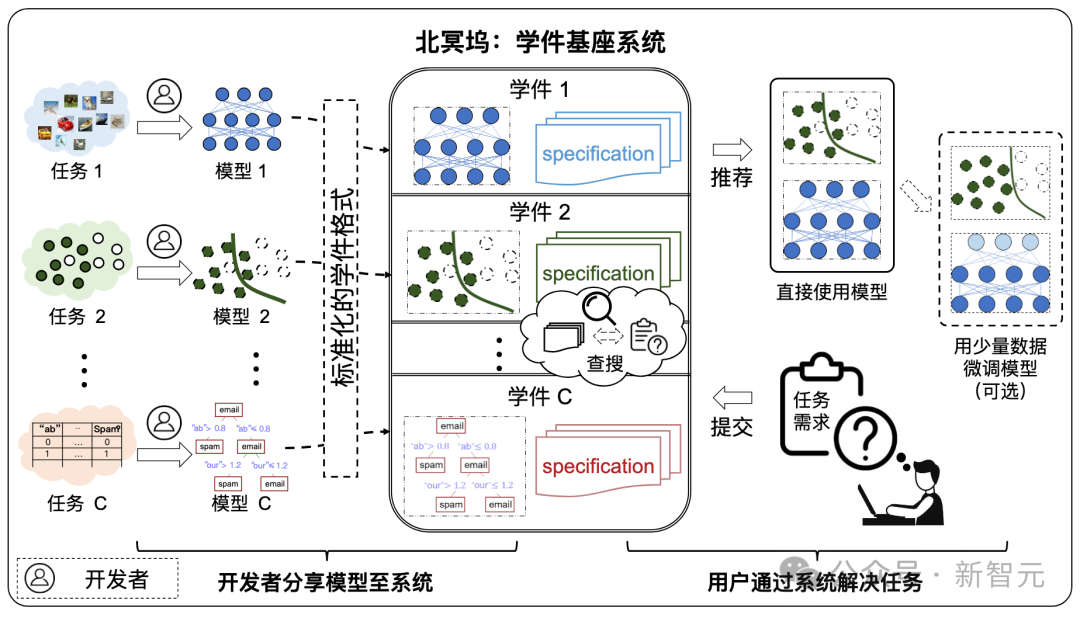
#規約是學件基座系統的核心元件,串連了系統中關於學件的全部流程,包括學件上傳、組織、查搜、部署與重複使用。
來自不同特徵/標記空間的學件,構成眾多的規約島嶼,所有規約島嶼共同構成學件基座系統中的規約世界。在規約世界中,如果能夠發現並建立不同島嶼之間的聯繫,那麼相對應的規約島嶼將可以進行合併。
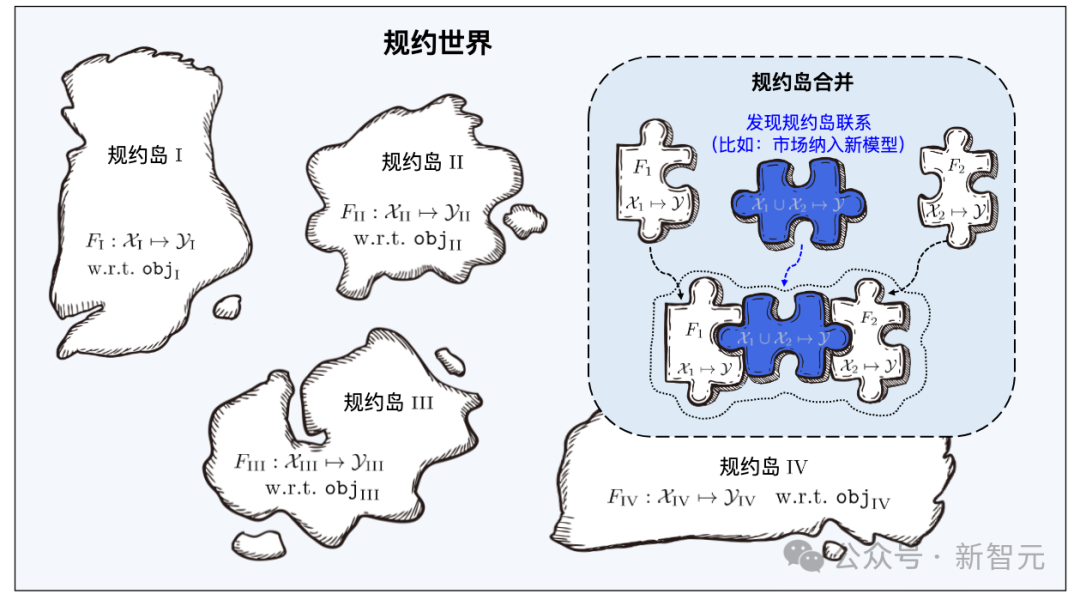
學件基座系統在查搜時,首先透過使用者需求中的語意規約定位到具體的規約島嶼,再透過使用者需求中的統計規約對規約島上的學件進行精確識別。不同的規約島嶼合併,則意味著相應的學件可以被用於不同特徵/標記空間的任務上,即可以復用至超出其原始目的的任務中。
學件範式透過充分利用社群分享的機器學習模型的能力,建構統一的規約空間,以統一的方式高效地為新用戶解決機器學習任務。隨著學件數量增多,透過有效地組織學件結構,學件基座系統整體解決任務的能力將顯著增強。
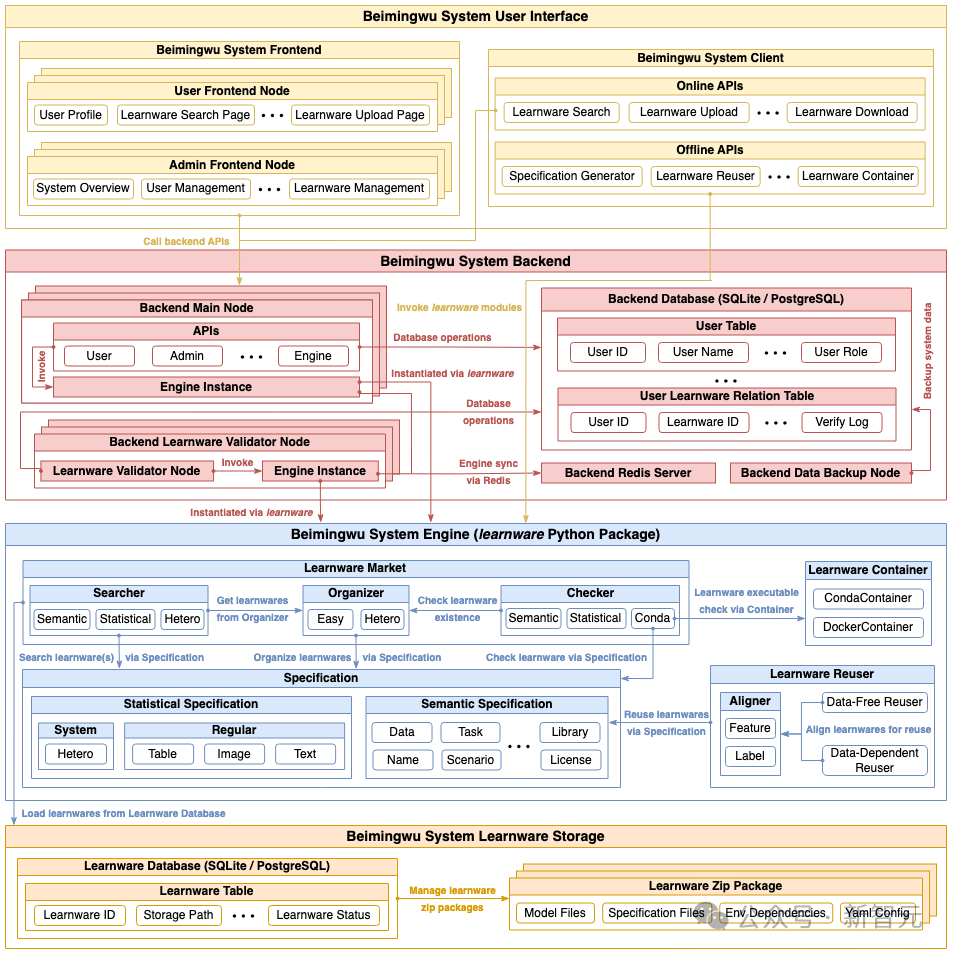
如下圖所示,北冥塢的系統架構包含四個層次,從學件儲存層至使用者互動層,首次自底向上系統性地實現了學件範式。四個層次的具體功能如下:
在論文中,研究團隊也建立了各種類型的基礎實驗場景,評估表格、圖像和文字數據上進行規約產生、學件辨識和復用的基準演算法。
表格資料實驗
#在各種表格資料集上,團隊首先評估了從學件系統中辨識和重複使用與使用者任務具有相同特徵空間的學件的性能。
而且,由於表格任務通常來自不同的特徵空間,研究團隊也對來自不同特徵空間的學件的識別和復用進行了評估。
同質案例
#在同質案例中,PFS資料集中的53個商店充當53個獨立用戶。
每個商店利用自己的測試數據作為使用者任務數據,並採用統一的特徵工程方法。這些使用者隨後可以在基座系統上查搜與其任務具有相同特徵空間的同質學件。
當使用者沒有標註資料或標註資料量有限時,團隊對不同的基準演算法進行了比較,所有使用者的平均損失如下圖所示。左表顯示,無資料方法比從市場上隨機選擇和部署一個學件要好得多;右圖表明,當使用者的訓練資料有限時,識別並重複使用單一或多個學件比使用者自訓練的模型性能更優。
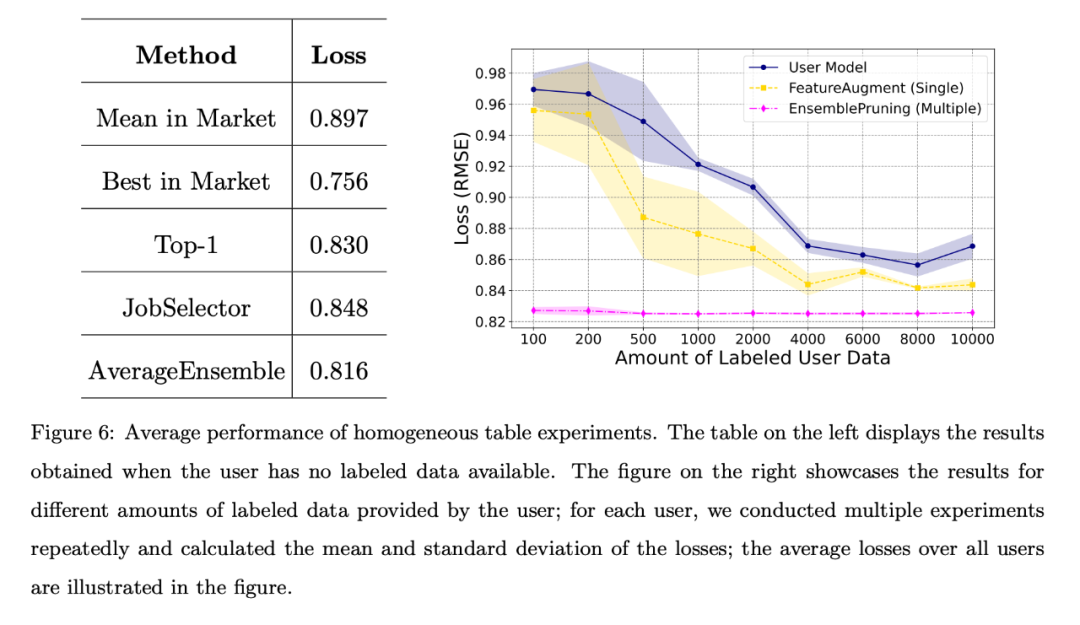
左表顯示,無資料方法比從市場上隨機選擇和部署一個學件要好得多;右圖表明,當使用者的訓練資料有限時,辨識並重複使用單一或多個學件比使用者自訓練的模型表現更優。
異質案例
#根據市場上學件與使用者任務的相似性,異質案例可進一步分為不同的特徵工程和不同的任務場景。
不同的特徵工程場景:
下圖左顯示的結果表明,即使使用者缺乏標註數據,系統中的學件也能表現出很強的性能,尤其是複用多個學件的AverageEnsemble方法。
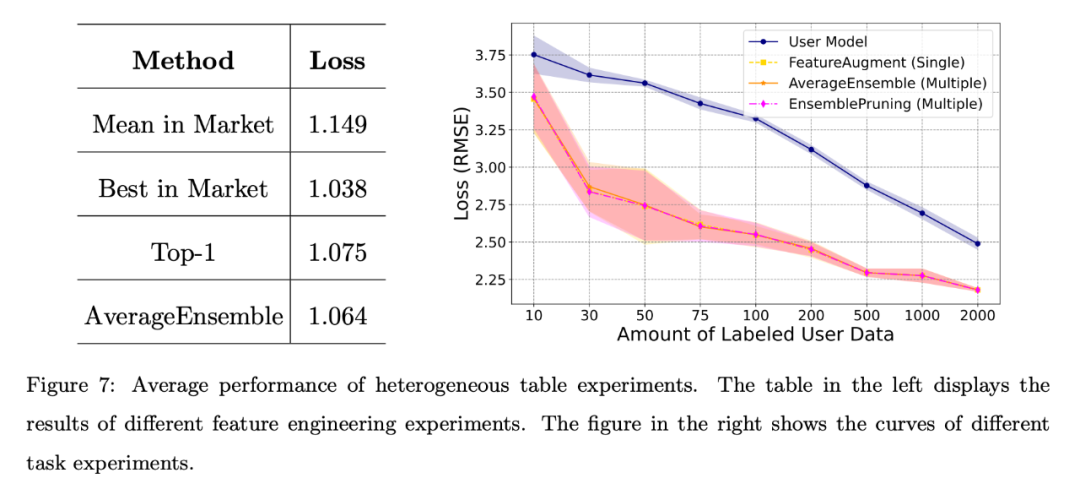
不同的任務場景:
上圖右顯示了使用者自訓練模型和幾種學件復用方法的損失曲線。
很明顯,異質學件在使用者標註資料量有限的情況下實驗驗證是有益的,有助於更好地與使用者的特徵空間進行對齊。
圖像和文字資料實驗
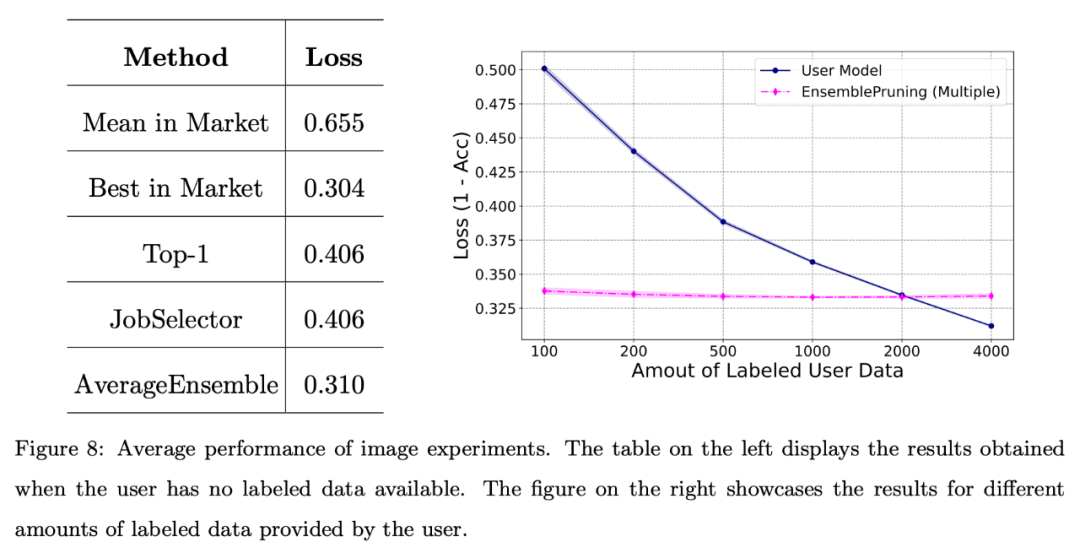
#此外,研究團隊在圖像資料集上對系統進行了基礎的評估。
下圖顯示,當使用者面臨標註資料稀缺或僅擁有有限數量的資料(少於 2000 個實例)時,利用學件基座系統可以產生良好的效能。
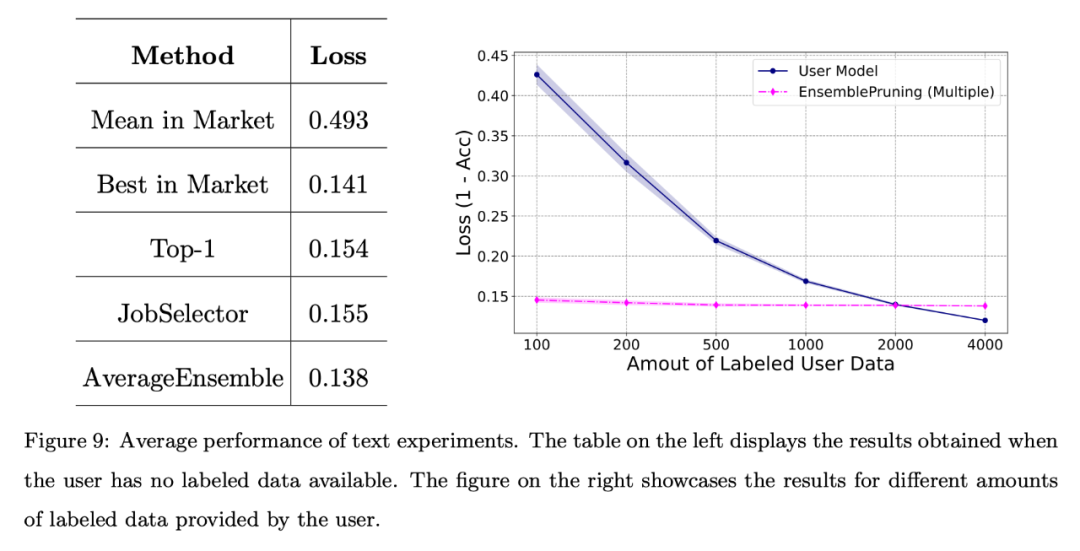
團隊也在基準的文字資料集上對系統進行了基礎評估。透過統一的特徵提取器進行特徵空間對齊。
如下圖所示,即使在沒有提供標註資料的情況下,透過學件辨識和重複使用所獲得的效能也能與系統中最好的學件相媲美。
此外,與從頭開始訓練模型相比,利用學件基座系統可以減少約2000個樣本。
以上是南大周志華團隊8年力! 「學件」系統解決機器學習複用難題,「模型融合」湧現科研新範式的詳細內容。更多資訊請關注PHP中文網其他相關文章!


































