

动态视觉分词统一图文表示,快手与北大合作提出基座模型 LaVIT 刷榜多模态理解与生成任务。
当前的大型语言模型如GPT、LLaMA等在自然语言处理领域取得了显著进展,它们能够理解和生成复杂的文本内容。然而,我们是否考虑过将这种强大的理解和生成能力迁移到多模态数据上呢?这将使我们能够轻松理解海量的图像和视频,并创作出图文并茂的内容。为了实现这一愿景,快手和北大最近合作开发了一种新型的多模态大模型,名为LaVIT。LaVIT正在逐步将这一想法变为现实,让我们期待它的进一步发展。

论文标题:Unified Language-Vision Pretraining in LLM with Dynamic Discrete Visual Tokenization
论文地址:https://arxiv.org/abs/2309.04669
代码模型地址:https://github.com/jy0205/LaVIT
模型总览
LaVIT 是一个新型的通用多模态基础模型,类似于语言模型,它能够理解和生成视觉内容。LaVIT 的训练范式借鉴了大型语言模型的成功经验,采用自回归的方式来预测下一个图像或文本 token。在完成训练后,LaVIT 可以充当一个多模态通用接口,无需进一步微调即可执行多模态理解和生成任务。例如,LaVIT 具备以下能力:
LaVIT 是一种先进的图像生成模型,可以根据文本提示生成高质量、多种纵横比和高美感的图像。与最先进的图像生成模型(如 Parti、SDXL 和 DALLE-3)相比,LaVIT 的图像生成能力不逊色。它能够有效地实现高质量文本到图像的生成,为用户提供更多选择和更好的视觉体验。

根据多模态提示进行图像生成:由于在 LaVIT 中,图像和文本都被统一表示为离散化的 token,因此其可以接受多种模态组合(例如文本、图像 文本、图像 图像)作为提示,生成相应的图像,而无需进行任何微调。

理解图像内容并回答问题:在给定输入图像的情况下,LaVIT 能够阅读图像内容并理解其语义。例如,模型可以为输入的图像提供 caption 并回答相应的问题。

方法概览
LaVIT 的模型结构如下图所示,其整个优化过程包括两个阶段:
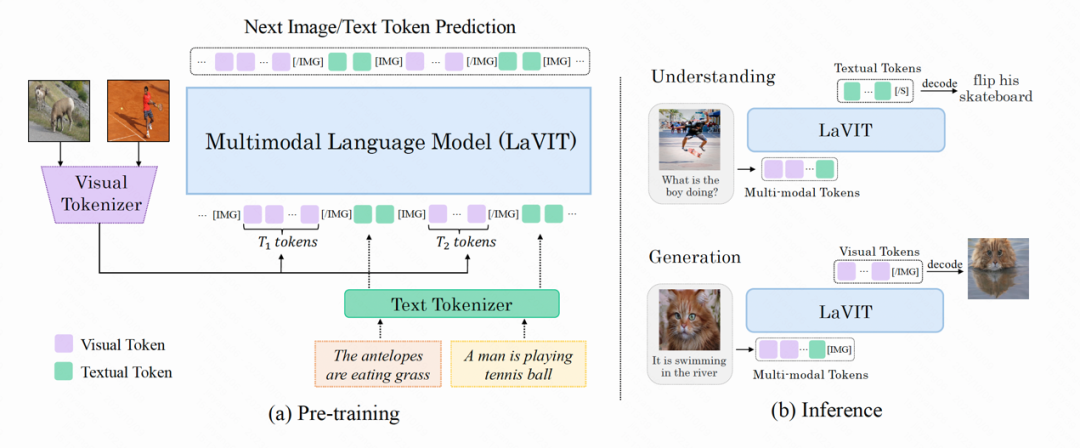
图:LaVIT 模型的整体架构
阶段 1: 动态视觉分词器
为了能够像自然语言一样理解和生成视觉内容,LaVIT 引入了一个设计良好的视觉分词器,用于将视觉内容(连续信号)转换为像文本一样的 token 序列,就像 LLM 能够理解的外语一样。作者认为,为了实现统一视觉和语言的建模,该视觉分词器 (Tokenizer) 应该具有以下两个特性:
离散化:视觉 token 应该被表示为像文本一样的离散化形式。这样对于两种模态采用统一的表示形式,有利于 LaVIT 在一个统一的自回归生成式训练框架下,使用相同的分类损失进行多模态建模优化。
动态化:与文本 token 不同的是,图像 patch 之间有着显著的相互依赖性,这使得从其他图像 patch 中推断另一个 patch 相对简单。因此,这种依赖性会降低原本 LLM 的 next-token prediction 优化目标的有效性。LaVIT 提出通过使用 token merging 来降低视觉 patch 之间的冗余性,其根据不同图像语义复杂度的不同,编码出动态的视觉 token 数量。这样对于复杂程度不同的图像,采用动态的 token 编码也进一步提高了预训练的效率,避免了冗余的 token 计算。
下图是 LaVIT 所提出的视觉分词器结构:
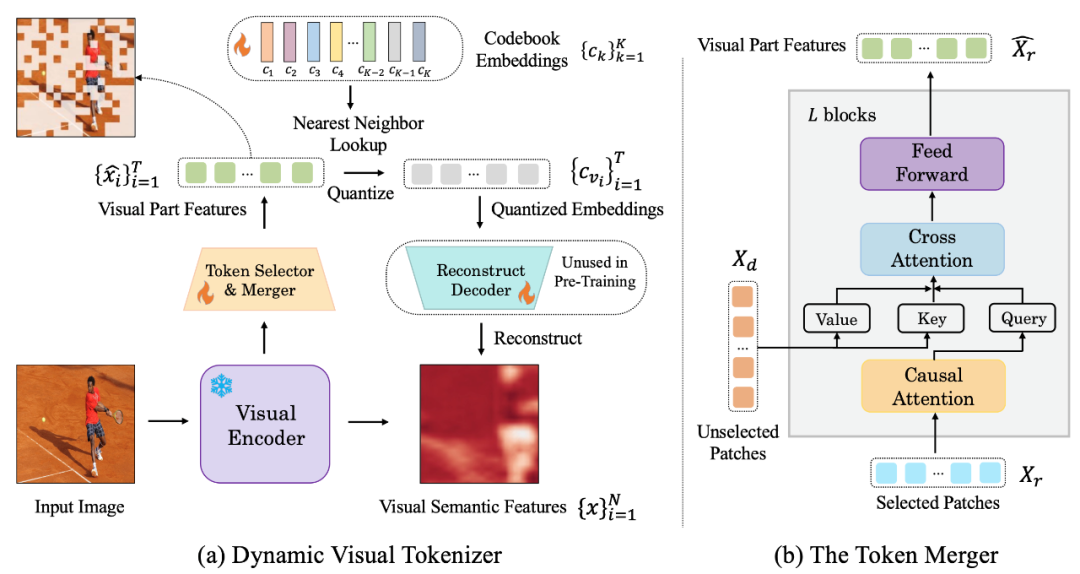
Figure: (a) Dynamic visual token generator (b) token combiner
The dynamic visual word segmentation The processor includes token selector and token combiner. As shown in the figure, the token selector is used to select the most informative image blocks, while the token merger compresses the information of those uninformative visual blocks into the retained tokens to achieve the merging of redundant tokens. The entire dynamic visual word segmenter is trained by maximizing the semantic reconstruction of the input image.
Token selector
Token selector receives N image block-level features as input, and its goal is to evaluate the importance of each image block and select The block with the highest amount of information to fully represent the semantics of the entire image. To achieve this goal, a lightweight module consisting of multiple MLP layers is used to predict the distribution π. By sampling from the distribution π, a binary decision mask is generated that indicates whether to keep the corresponding image patch.
Token combiner
Token combiner divides N image blocks into two groups: retain X_r and discard X_d according to the generated decision mask. Unlike discarding X_d directly, the token combiner can preserve the detailed semantics of the input image to the maximum extent. The token combiner consists of L stacked blocks, each of which includes a causal self-attention layer, a cross-attention layer, and a feed-forward layer. In the causal self-attention layer, each token in X_r only pays attention to its previous token to ensure consistency with the text token form in LLM. This strategy performs better compared to bidirectional self-attention. The cross-attention layer takes the retained token X_r as query and merges the tokens in X_d based on their semantic similarity.
Phase 2: Unified generative pre-training
The visual token processed by the visual tokenizer is connected with the text token to form a multi-modal sequence as training enter. In order to distinguish the two modalities, the author inserts special tokens at the beginning and end of the image token sequence: [IMG] and [/IMG], which are used to indicate the beginning and end of visual content. In order to be able to generate text and images, LaVIT uses two image-text connection forms: [image, text] and [text; image].
For these multi-modal input sequences, LaVIT uses a unified, autoregressive approach to directly maximize the likelihood of each multi-modal sequence for pre-training. This complete unification of representation space and training methods helps LLM better learn multi-modal interaction and alignment. After pre-training is completed, LaVIT has the ability to perceive images and can understand and generate images like text.
Experiment
Zero-shot multimodal understanding
LaVIT in image subtitle generation (NoCaps, Flickr30k) and visual question answering It has achieved leading performance on zero-shot multi-modal understanding tasks such as (VQAv2, OKVQA, GQA, VizWiz).
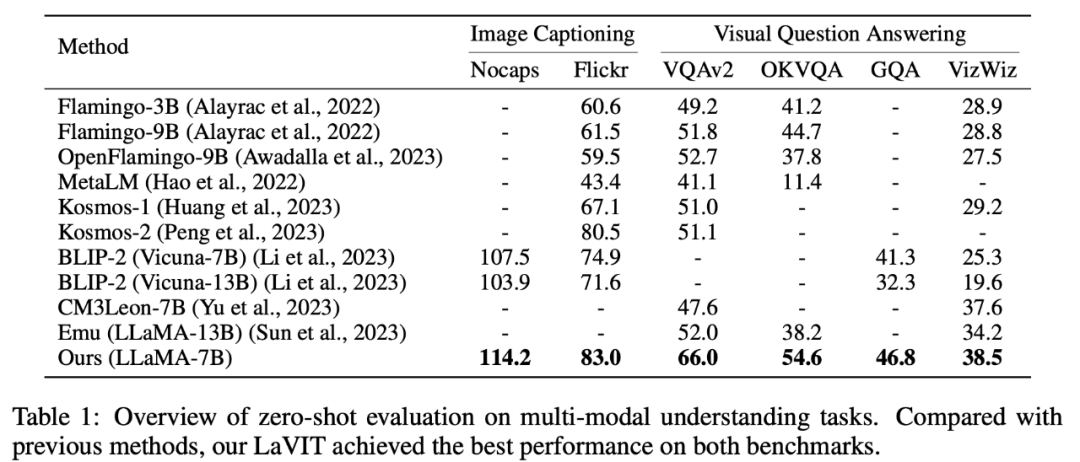
Table 1 Evaluation of multi-modal understanding tasks with zero samples
Multiple zero samples Modality Generation
In this experiment, since the proposed visual tokenizer is able to represent images as discretized tokens, LaVIT has the ability to synthesize images by generating text-like visual tokens through autoregression. The author conducted a quantitative evaluation of the image synthesis performance of the model under zero-sample text conditions, and the comparison results are shown in Table 2.
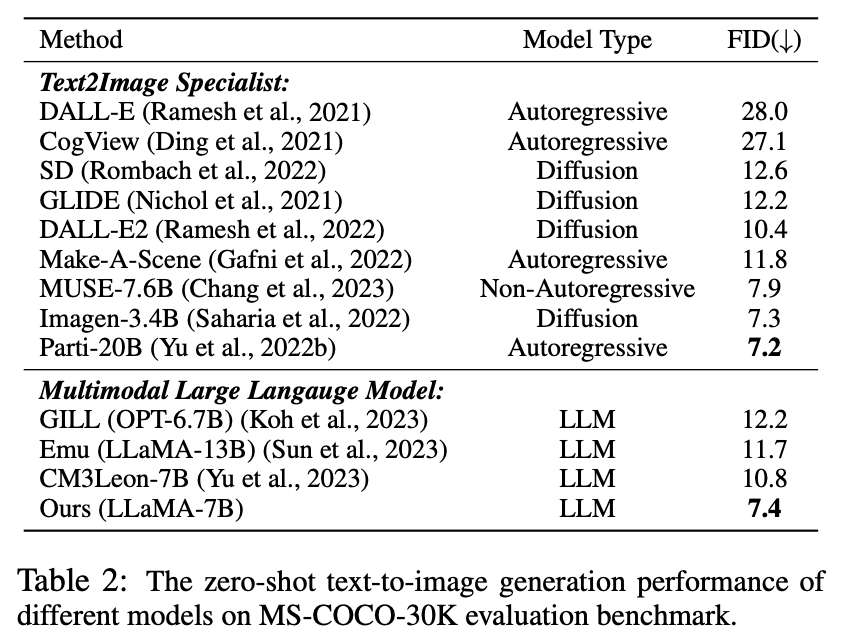
Table 2 Zero-sample text to image generation performance of different models
As can be seen from the table It turns out that LaVIT outperforms all other multi-modal language models. Compared to Emu, LaVIT achieves further improvements on smaller LLM models, demonstrating excellent visual-verbal alignment capabilities. Furthermore, LaVIT achieves comparable performance to the state-of-the-art text-to-image expert Parti while using less training data.
Multi-modal prompt image generation
LaVIT can seamlessly accept multiple modal combinations as prompts and generate corresponding image without any fine-tuning. LaVIT generates images that accurately reflect the style and semantics of a given multimodal cue. And it can modify the original input image with multi-modal cues of the input. Traditional image generation models such as Stable Diffusion cannot achieve this capability without additional fine-tuned downstream data.

Example of multi-modal image generation results
Qualitative analysis
As shown in the figure below, LaVIT's dynamic tokenizer can dynamically select the most informative image blocks based on the image content, and the learned code can produce visual encoding with high-level semantics.

Visualization of dynamic visual tokenizer (left) and learned codebook (right)
Summary
The emergence of LaVIT provides an innovative paradigm for the processing of multi-modal tasks. By using a dynamic visual word segmenter to represent vision and language into a unified discrete token representation, inheritance A successful autoregressive generative learning paradigm for LLM. By optimizing under a unified generation goal, LaVIT can treat images as a foreign language, understanding and generating them like text. The success of this method provides new inspiration for the development direction of future multimodal research, using the powerful reasoning capabilities of LLM to open new possibilities for smarter and more comprehensive multimodal understanding and generation.
以上是快手、北大多模態大模型:影像即外語,媲美DALLE-3的突破的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















