

2023年,AI大模型領域的統治者Transformer的地位開始受到挑戰。一種新的架構名為「Mamba」嶄露頭角,它是一種選擇性狀態空間模型,在語言建模方面與Transformer不相上下,甚至有可能超越它。同時,Mamba能夠根據上下文長度的增加實現線性擴展,這使得它在處理實際資料時能夠處理百萬詞彙長度的序列,並提升了5倍的推理吞吐量。這項突破性的性能提升令人矚目,為AI領域的發展帶來了新的可能性。
發布後的一個多月裡,Mamba開始逐漸展現其影響力,並衍生出了MoE-Mamba、Vision Mamba、VMamba、U-Mamba、MambaByte等多個項目。在不斷克服Transformer的短板方面,Mamba顯示出了極大的潛力。這些發展顯示出Mamba不斷發展和進步,為人工智慧領域帶來了新的可能性。
然而,這顆冉冉升起的"新星"在2024年的ICLR會議上遇到了挫折。最新的公開結果顯示,Mamba的論文目前仍處於待定狀態,我們只能在待定決定一欄中看到它的名字,無法確定是被延遲決定還是被拒絕。

整體來看,Mamba收到了四位審查者的評分,分別為8/8/6/3。有人表示,如果遭到這樣的評分仍然被拒絕,確實令人感到不解。

要弄清楚其中的緣由,我們還得看一下打出低分的審查者是怎麼說的。
論文審查頁面:https://openreview.net/forum?id=AL1fq05o7H
在評審回饋中,給予「3: reject, not good enough」評分的審稿人解釋了自己對於Mamba 的幾點意見:
#對模型設計的想法:
對實驗的想法:
此外,另一位審查者也指出 Mamba 存在的不足:該模型在訓練過程中仍然像 Transformers 一樣具有二次記憶體需求。
匯總所有審稿人的意見之後,作者團隊也對論文內容進行了修改和完善,補充了新的實驗結果與分析:
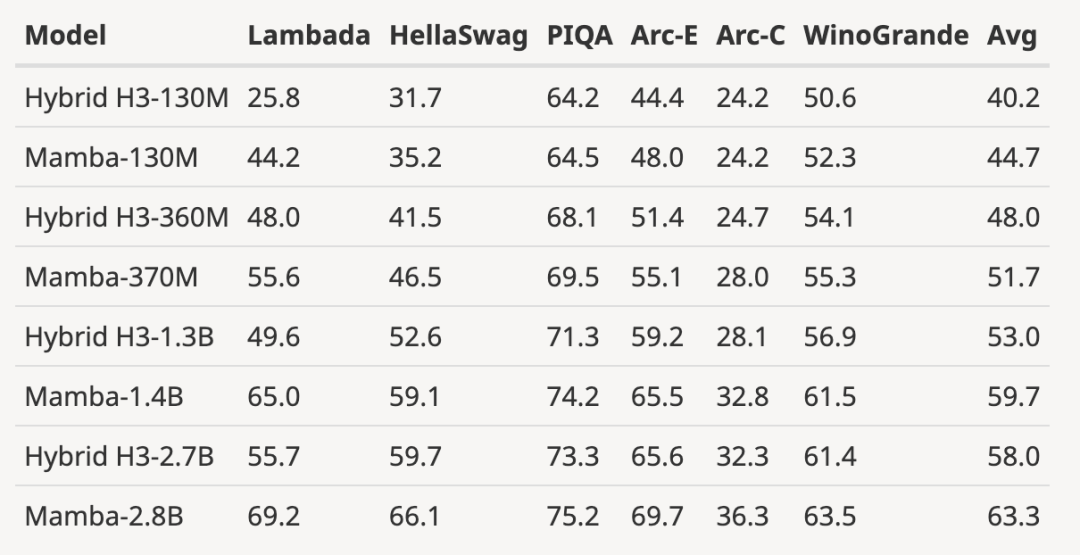
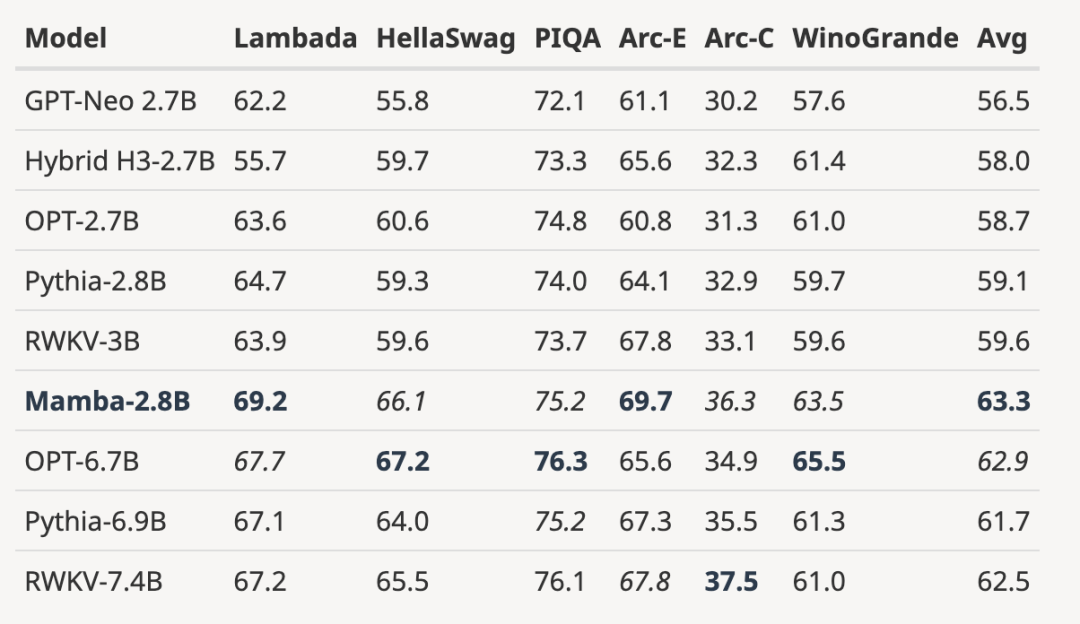
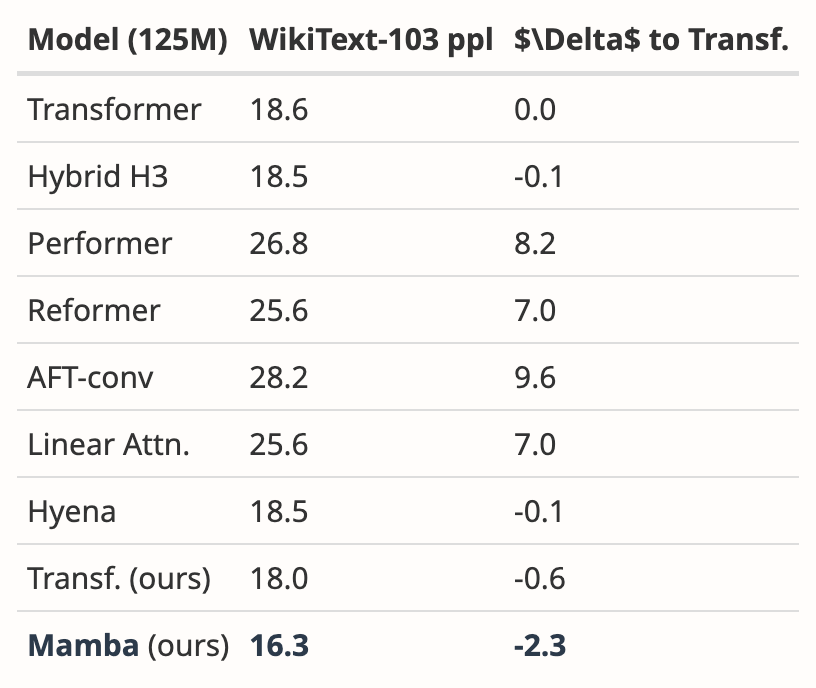
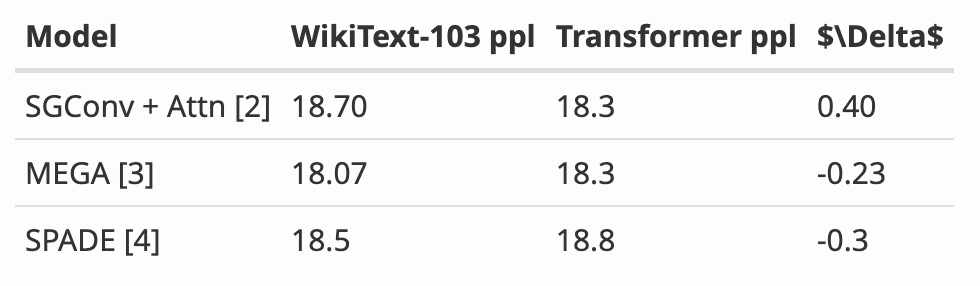
##作者下載了大小為125M-2.7 B 參數的預訓練H3 模型,並進行了一系列評估。 Mamba 在所有語言評估中都明顯更勝一籌,值得注意的是,這些H3 模型是使用二次注意力的混合模型,而作者僅使用線性時間Mamba 層的純模型在各項指標上都明顯更優。
與預訓練H3 模型的評估比較如下:
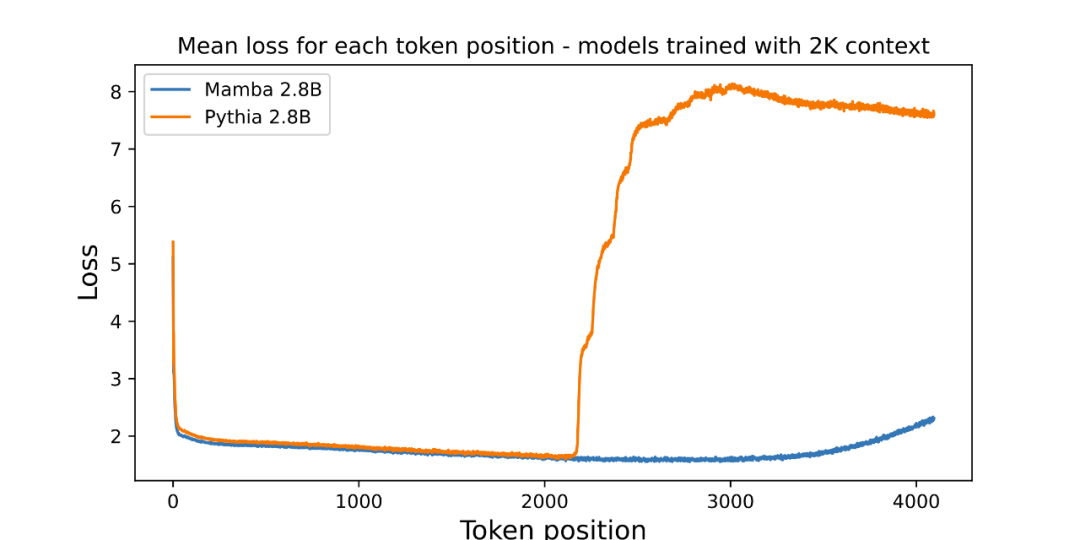
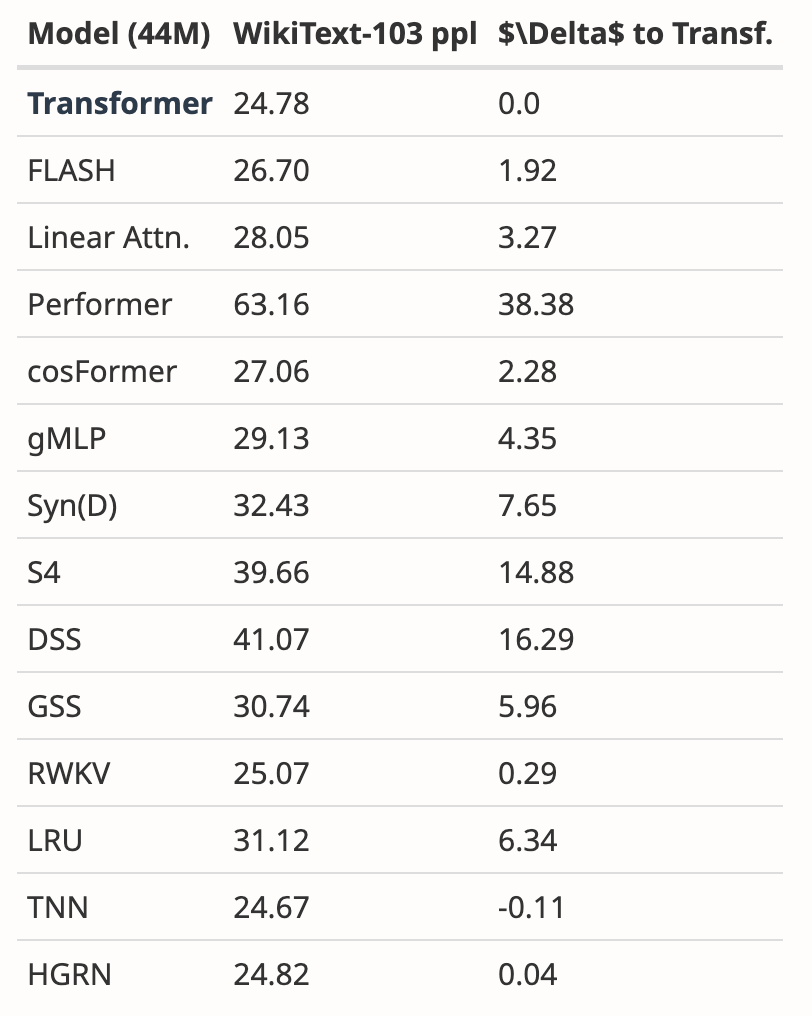
作者強調,長度外推並不是本文模型的直接動機,而是將其視為額外功能:
##這裡的基線模型(Pythia)在訓練時並沒有考慮長度外推法,或許還有其他Transformer 變體更具通用性(例如T5 或Alibi 相對位置編碼)。
 #儘管如此,兩個月過去了,這篇論文也處於「Decision Pending」流程中,沒有得到「接收」或「拒絕」的明確結果。
#儘管如此,兩個月過去了,這篇論文也處於「Decision Pending」流程中,沒有得到「接收」或「拒絕」的明確結果。
在各大AI 頂會中,「投稿數量爆炸」都是一個令人頭痛的問題,所以精力有限的審稿人難免有看走眼的時候。這就導致歷史上出現了許多著名論文被頂會拒絕的情況,包括YOLO、transformer XL、Dropout、支援向量機(SVM)、知識蒸餾、SIFT,還有Google 搜尋引擎的網頁排名演算法PageRank(參見: 《大名鼎鼎的YOLO、PageRank 影響力爆棚的研究,曾被CS 頂會拒稿》)。
甚至,身為深度學習三巨頭之一的 Yann LeCun 也是經常被拒的論文大戶。剛剛,他發推文說,他被引 1887 次的論文「Deep Convolutional Networks on Graph-Structured Data」也被頂會拒絕了。
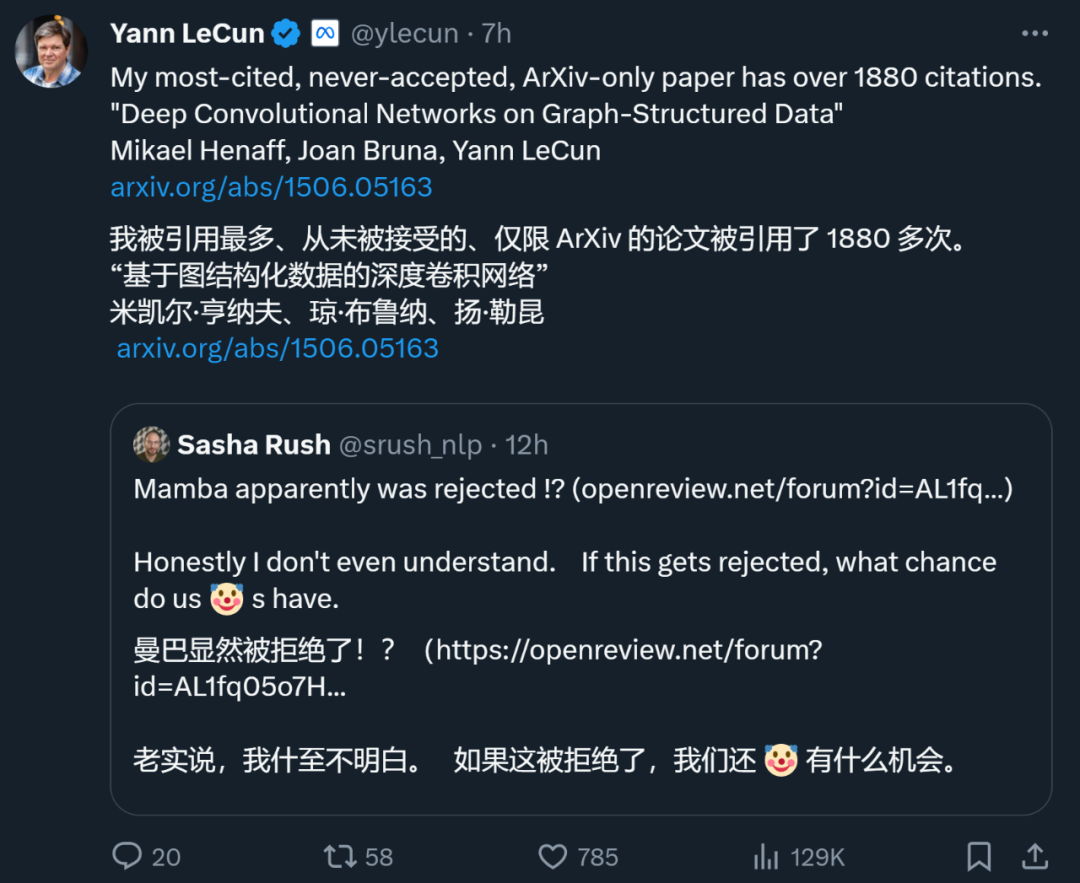
在 ICML 2022 期間,他甚至「投了三篇,被拒絕三篇」。

所以,論文被某個頂會拒絕不代表沒有價值。在上述被拒絕的論文中,許多論文選擇了轉投其他會議,最後被接收。因此,網友建議 Mamba 轉投陳丹琦等青年學者組成的 COLM。 COLM 是一個專注於語言建模研究的學術場所,專注於理解、改進和評論語言模型技術的發展,或許對 Mamba 這類論文來說是更好的選擇。
不過,無論Mamba 最終能否被ICLR 接收,它都已經成為一份頗具影響力的工作,也讓社區看到了衝破Transformer 桎梏的希望,為超越傳統Transformer 模型的探索注入了新的活力。
以上是ICLR為什麼不接受Mamba論文? AI社群掀起了大討論的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















