大模型領域中,微調是改善模型效能的重要一步。隨著開源大模型逐漸變多,人們總結出了許多微調方式,其中一些取得了很好的結果。 最近,來自Meta、紐約大學的研究者用「自我獎勵方法」,讓大模型自己產生自己的微調數據,給人帶來了一點新的震撼。 在新方法中,作者對Llama 2 70B 進行了三個迭代的微調,生成的模型在AlpacaEval 2.0 排行榜上優於一眾現有重要大模型,包括Claude 2、Gemini Pro 和GPT-4。 因此,論文剛發上 arXiv 幾個小時就引起了人們的注意。 雖然目前方法還沒有開源,但是人們認為論文中使用的方法描述清晰,復現起來應該不難。 
眾所周知,使用人類偏好資料調整大語言模型(LLM)可以大幅提高預訓練模型的指令追蹤效能。在GPT 系列中,OpenAI 提出了人類回饋強化學習(RLHF) 的標準方法,讓大模型可以從人類偏好中學習獎勵模型,再使得獎勵模型被凍結並用於使用強化學習訓練LLM,這種方法已獲得了巨大的成功。 最近出現的新想法是完全避免訓練獎勵模型,並直接使用人類偏好來訓練 LLM,例如直接偏好最佳化(DPO)。在上述兩種情況下,調優都受到人類偏好資料的大小和品質的瓶頸,並且在 RLHF 的情況下,調優質量也受到從它們訓練的凍結獎勵模型的品質的瓶頸。 在Meta 的新工作中,作者提議訓練一個自我改進的獎勵模型,該模型不是被凍結,而是在LLM 調整期間不斷更新,以避免這一瓶頸。 這種方法的關鍵是發展一個擁有訓練期間所需的所有能力的智能體(而不是分為獎勵模型和語言模型),讓指令跟隨任務的預訓練和多任務訓練允許透過同時訓練多個任務來實現任務遷移。 因此作者引入了自我獎勵語言模型,其智能體既充當遵循模型的指令,為給定的提示生成響應,也可以根據示例生成和評估新指令,以添加到他們自己的訓練集中。 新方法使用類似迭代 DPO 的框架來訓練這些模型。從種子模型開始,如圖 1 所示,在每次迭代中都有一個自指令建立過程,其中模型為新建立的提示產生候選響應,然後由相同模型分配獎勵。後者是透過 LLM-as-a-Judge 的提示來實現的,這也可以看作是指令跟隨任務。根據產生的資料建立偏好資料集,並透過 DPO 訓練模型的下一次迭代。 
#作者提出的方法首先假設:可以存取基本的預訓練語言模型和少量人工註釋的種子數據,然後建立一個模型,旨在同時擁有兩種技能:#1. 指令遵循:給出描述用戶請求的提示,能夠產生高品質、有幫助(且無害)的回應。 2. 自指令建立:能夠按照範例產生和評估新指令以新增至自己的訓練集中。 使用這些技能是為了使模型能夠執行自對準,即它們是用於使用人工智慧回饋(AIF)迭代訓練自身的元件。 自指令的創建包括產生候選回應,然後讓模型本身判斷其質量,即它充當自己的獎勵模型,從而取代對外部模型的需求。這是透過 LLM-as-a-Judge 機制實現的 [Zheng et al., 2023b],即透過將反應評估制定為指令跟隨任務。這個自行創建的 AIF 偏好資料被用作訓練集。 所以在微調過程中,相同的模型被用於兩個角色:作為「學習者」和作為「法官」。基於新出現的法官角色,模型可以透過上下文微調來進一步提升表現。 整體的自對齊過程是一個迭代過程,透過以下步驟來進行:建立一系列模型,每個模型都比上一個模型有所改進。在這其中重要的是,由於模型既可以提高其生成能力,又可以透過相同的生成機製作為自己的獎勵模型,這意味著獎勵模型本身可以透過這些迭代來改進,這就與獎勵模型固有的標準做法出現了差異。 研究者認為,這種方式可以提高這些學習模式未來自我改進的潛力上限,並消除限制性瓶頸。 

#在實驗中,研究者使用了Llama 2 70B 作為基礎預訓練模式。他們發現,與基線種子模型相比,自獎勵 LLM 對齊不僅提高了指令跟隨表現,獎勵建模能力也提高了。 這意味著在迭代訓練中,模型能夠在給定的迭代中為自己提供比上一次迭代品質更好的偏好資料集。雖然這種影響在現實世界中會趨於飽和,但提供了一個有趣的可能:這樣得到的獎勵模型(以及 LLM)要優於僅從人類撰寫的原始種子資料中訓練的模型。 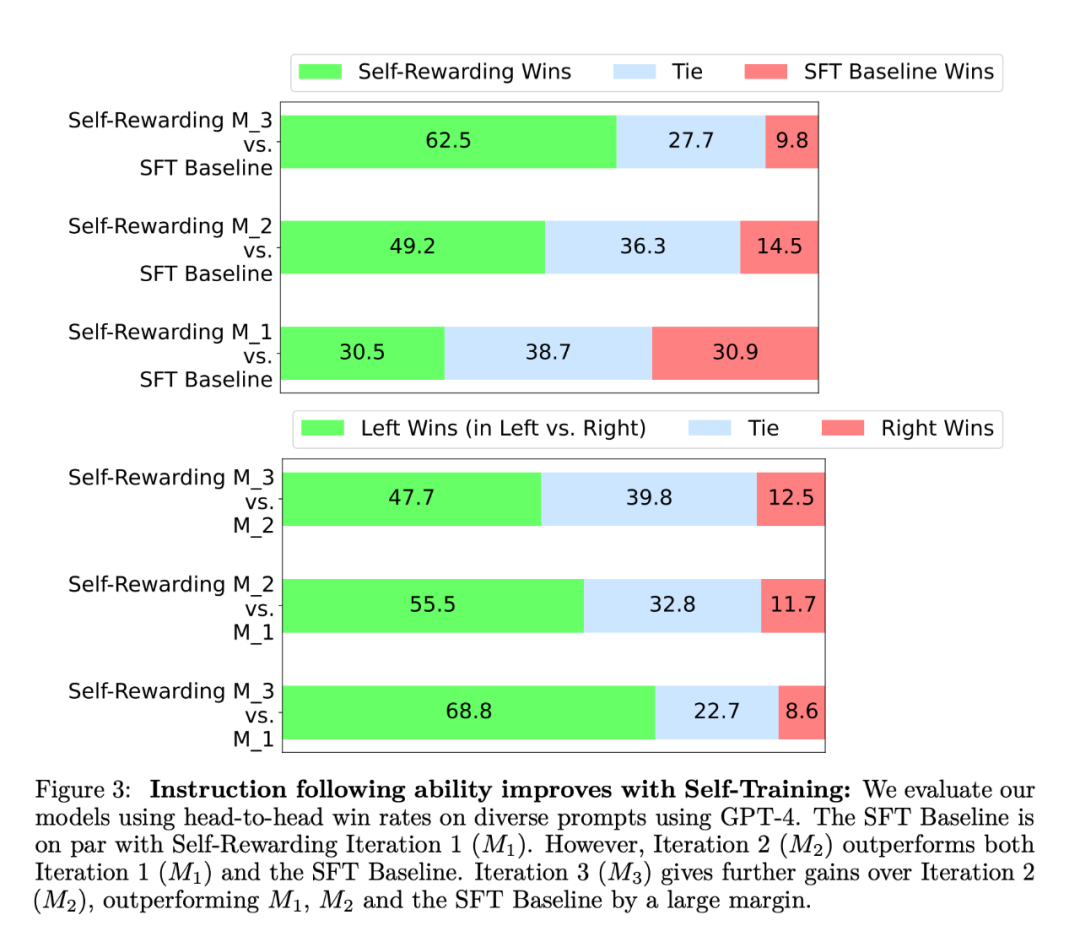 研究者在AlpacaEval 2 排行榜上評估了自獎勵模型,結果如表1 所示。他們觀察到了與 head-to-head 評估相同的結論,即訓練迭代的勝率比 GPT4-Turbo 高,從迭代 1 的 9.94%,到迭代 2 的 15.38%,再到迭代 3 的 20.44%。同時,迭代 3 模型優於許多現有模型,包括 Claude 2、Gemini Pro 和 GPT4 0613。
研究者在AlpacaEval 2 排行榜上評估了自獎勵模型,結果如表1 所示。他們觀察到了與 head-to-head 評估相同的結論,即訓練迭代的勝率比 GPT4-Turbo 高,從迭代 1 的 9.94%,到迭代 2 的 15.38%,再到迭代 3 的 20.44%。同時,迭代 3 模型優於許多現有模型,包括 Claude 2、Gemini Pro 和 GPT4 0613。

EFT在SFT基線上有所改進,使用IFT EFT與單獨使用IFT相比,五個測量指標都有所提升。例如,與人類的配對準確率一致性從65.1%上升到78.7%。
透過自我訓練提升獎勵建模能力。在進行一輪自我獎勵訓練後,模型為下一次迭代提供自我獎勵的能力得到了提高,此外它的指令跟隨能力也得到了提高。
LLMas-a-Judge 提示的重要性。研究者使用了各種提示格式發現,LLMas-a-Judge 提示在使用 SFT 基線時成對準確率更高。
作者認為,自我獎勵的訓練方式既提升了模型的指令追蹤能力,也提升了模型在迭代中的獎勵建模能力。 雖然這只是一項初步研究,但看來已是一個令人興奮的研究方向,此種模型能夠更好地在未來的迭代中分配獎勵,以改善指令遵循,實現一種良性循環。 這種方法也為更複雜的判斷方法開啟了一定的可能性。例如,大模型可以透過搜尋資料庫來驗證其答案的準確性,從而獲得更準確和可靠的輸出。 參考:https://www.reddit.com/r/MachineLearning/comments/19atnu0/r_selfrewarding_language_models_meta_2024/ #
以上是自我獎勵下的大型模型:Llama2透過Meta學習自行優化,超越GPT-4的表現的詳細內容。更多資訊請關注PHP中文網其他相關文章!
























