1 月 22 日,零一萬物 Yi 系列模型家族迎來新成員:Yi Vision Language(Yi-VL)多模態語言大模型正式面向全球開源。據悉,Yi-VL 模型基於 Yi 語言模型開發,包括 Yi-VL-34B 和 Yi-VL-6B 兩個版本。
- #https://huggingface.co/01-ai
- https://www.modelscope.cn/organization/01ai
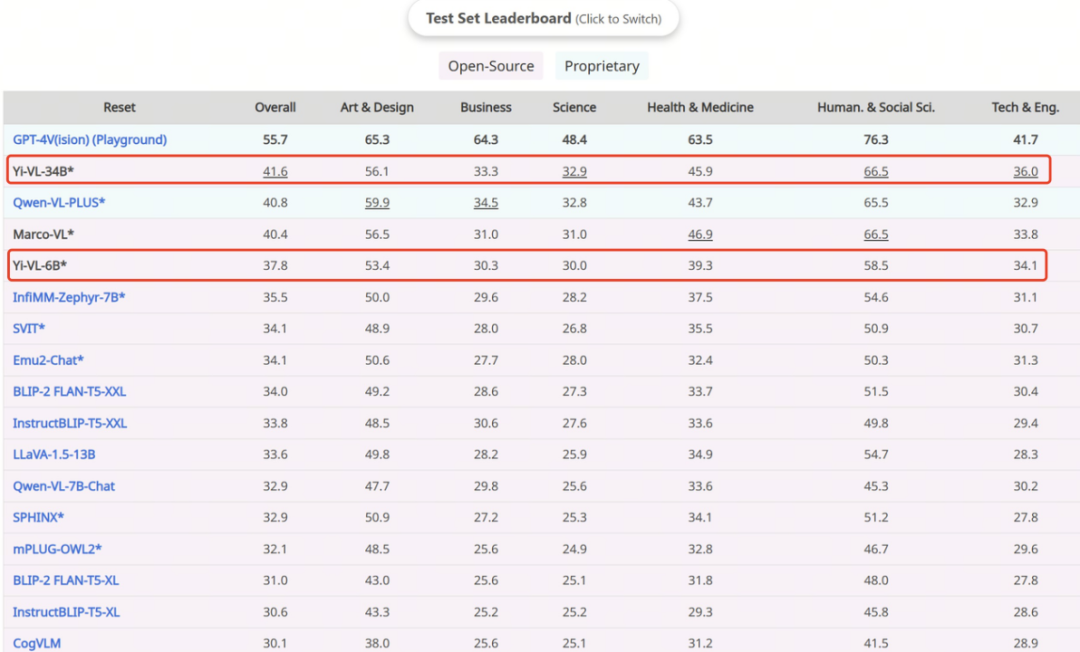
#憑藉卓越的圖文理解和對話生成能力,Yi-VL 模型在英文資料集MMMU 和中文資料集CMMMU 上取得了領先成績,展示了在複雜跨學科任務上的強大實力。 MMMU(全名Massive Multi-discipline Multi-modal Understanding & Reasoning 大規模多學科多模態理解和推理)資料集包含了11500 個來自六大核心學科(藝術與設計、商業、科學、健康與醫學、人文與社會科學以及技術與工程)的問題,涉及高度異構圖像類型和交織文本圖像信息,對模型的高級知覺和推理能力提出了極高要求。在該測試集上,Yi-VL-34B 以41.6% 的準確率表現超越了一系列多模態大模型,僅次於GPT-4V(55.7%),展現出強大的跨學科知識理解與應用能力。 
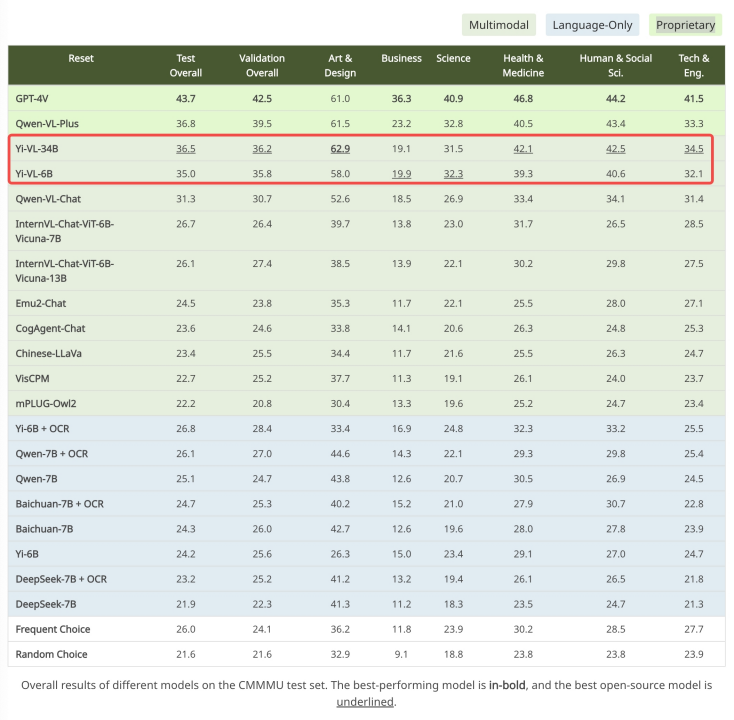
#來源:https://mmmu-benchmark.github.io在針對中文場景打造的CMMMU 資料集上,Yi-VL 模型展現了「更懂中國人」的獨特優勢。 CMMMU 包含了約 12,000 道源自大學考試、測驗和教科書的中文多模態問題。其中,GPT-4V 在該測試集上的準確率為43.7%,Yi-VL-34B 以36.5% 的準確率緊隨其後,在現有的開源多模態模型中處於領先位置。 
# 來源:https://cmmmu-benchmark.github.io/ 那麼,Yi-VL 模型在圖文對話等多元場景中的表現如何? 

可以看到,基於Yi 語言模型的強大文字理解能力,只需對圖片進行對齊,就可以獲得不錯的多模態視覺語言模型—— 這也是Yi-VL 模型的核心亮點之一。 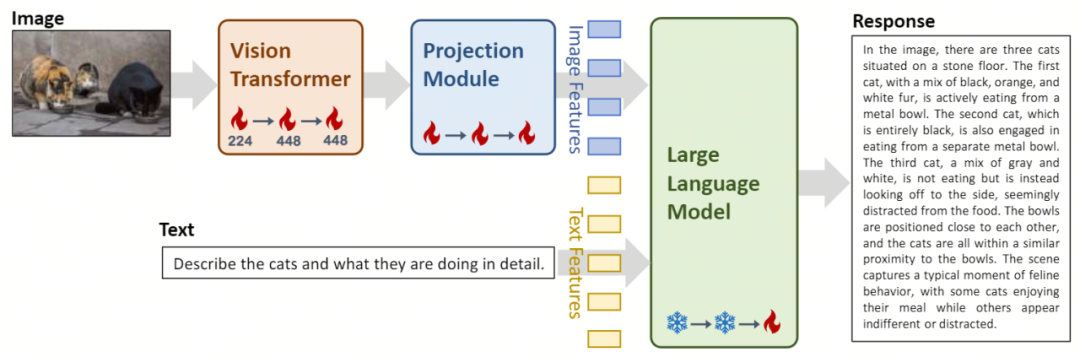
在架構設計上,Yi-VL 模型基於開源LLaVA 架構,包含三個主要模組:
- Vision Transformer(簡稱ViT)用於影像編碼,使用開源的OpenClip ViT-H/14 模型初始化可訓練參數,透過學習從大規模「圖像- 文字」對中提取特徵,使模型具備處理和理解圖像的能力。
- Projection 模組為模型帶來了圖像特徵與文字特徵空間對齊的能力。此模組由一個包含層歸一化(layer normalizations)的多層感知機(Multilayer Perceptron,簡稱 MLP)所構成。這項設計使得模型可以更有效地整合和處理視覺和文字訊息,提高了多模態理解和產生的準確度。
- Yi-34B-Chat 和 Yi-6B-Chat 大規模語言模型的引入為 Yi-VL 提供了強大的語言理解和生成能力。這部分模型借助先進的自然語言處理技術,能夠幫助 Yi-VL 深入理解複雜的語言結構,並產生連貫、相關的文本輸出。
在訓練方法上,Yi-VL 模型的訓練過程分為三個精心設計的階段,旨在全面提升模型的視覺和語言處理能力。
- 第一階段:零一萬物使用 1 億張的「圖片 - 文字」配對資料集訓練 ViT 和 Projection 模組。在這一階段,影像解析度被設定為 224x224,以增強 ViT 在特定架構中的知識獲取能力,同時實現與大型語言模型的高效對齊。
- 第二階段:零一萬物將 ViT 的影像解析度提升至 448x448,這項提升讓模型更擅長辨識複雜的視覺細節。此階段使用了約 2500 萬“圖像 - 文字”對。
- 第三階段:零一萬物開放整個模型的參數進行訓練,目標是提高模型在多模態聊天互動中的表現。訓練資料涵蓋了多樣化的資料來源,共約 100 萬「圖像 - 文字」對,確保了資料的廣泛性和平衡性。
零一萬物技術團隊同時也驗證了可以基於Yi 語言模型強大的語言理解和生成能力,用其他多模態訓練方法如BLIP、Flamingo、EVA 等快速訓練出能夠進行高效影像理解與流暢圖文對話的多模態圖文模型。 Yi 系列模型可以作為多模態模型的基座語言模型,為開源社群提供一個新的選項。 目前,Yi-VL 模型已在Hugging Face、ModelScope 等平台上向公眾開放,用戶可透過以下連結親身體驗這款模型在圖文對話等多元場景中的優異表現。歡迎探索 Yi-VL 多模態語言模型的強大功能,體驗前沿的 AI 技術成果。 以上是Yi-VL大模型開源,榮居MMMU、CMMMU榜首的詳細內容。更多資訊請關注PHP中文網其他相關文章!























