

圖像到視訊生成(I2V)任務是電腦視覺領域的一項挑戰,旨在將靜態圖像轉化為動態視訊。這個任務的困難在於從單張影像中提取並產生時間維度的動態訊息,同時保持影像內容的真實性和視覺上的連貫性。現有的I2V方法通常需要複雜的模型架構和大量的訓練資料來實現這一目標。
近期,快手主導的一項新研究成果《I2V-Adapter: A General Image-to-Video Adapter for Video Diffusion Models》發布。該研究引入了一種創新的影像到視訊轉換方法,提出了一種輕量級適配器模組,即I2V-Adapter。此適配器模組能夠在不改變現有文字到視訊生成(T2V)模型原始結構和預訓練參數的情況下,將靜態影像轉換成動態視訊。此方法在影像到影片轉換領域具有廣泛的應用前景,能夠為影片創作、媒體傳播等領域帶來更多可能性。這項研究結果的發布對於推動影像和視訊技術的發展具有重要意義,為相關領域的研究者提供了一種有效的工具和方法。

相對於現有方法而言,I2V-Adapter在可訓練參數方面取得了巨大的改進,其參數數量最低可達到22M,僅為主流方案Stable Video Diffusion的1%。同時,此適配器也具備與Stable Diffusion社群開發的客製化T2I模型(如DreamBooth、Lora)和控制工具(如ControlNet)的兼容性。透過實驗,研究者證明了I2V-Adapter在產生高品質視訊內容方面的有效性,為I2V領域的創意應用開啟了新的可能性。

Temporal modeling with Stable Diffusion
相較於影像生成,影片生成面臨獨特的挑戰,即建模視訊影格之間的時序連貫性。目前大多數的方法都是基於預先訓練的T2I模型,例如Stable Diffusion和SDXL,透過引入時序模組對影片中的時序資訊進行建模。受到AnimateDiff的啟發,這是一個最初設計用於定制T2V任務的模型,它通過引入與T2I模型解耦的時序模組來建模時序信息,並保留了原始T2I模型的能力,能夠生成流暢的視頻。因此,研究者認為預先訓練的時序模組可以被視為通用的時序表徵,並可以應用於其他視訊生成場景,如I2V生成,而無需進行任何微調。因此,研究者直接使用預先訓練的AnimateDiff時序模組,並保持其參數固定。
Adapter for attention layers
#I2V任務中的另一個挑戰是保持輸入影像的ID資訊。目前的解決方案主要有兩種:一種是使用預先訓練的影像編碼器對輸入影像進行編碼,並透過交叉關注機制將編碼後的特徵注入到模型中以指導去噪過程;另一種是將影像與有雜訊的輸入在通道維度上進行拼接,然後一起輸入到後續的網路中。然而,前一種方法由於影像編碼器難以捕捉底層訊息,可能導致產生的視訊ID發生變化;而後一種方法往往需要改變T2I模型的結構和參數,訓練代價高且相容性較差。
為了解決上述問題,研究者提出了 I2V-Adapter。具體來說,研究者將輸入圖像與noised input 並行輸入給網絡,在模型的spatial block 中,所有幀都會額外查詢一次首幀信息,即key,value 特徵都來自於不加噪的首幀,輸出結果與原始模型的self attention 相加。此模組中的輸出映射矩陣使用零初始化並且只訓練輸出映射矩陣與 query 映射矩陣。為了進一步加強模型對輸入影像語意資訊的理解,研究者引入了預先訓練的 content adapter(本文使用的是 IP-Adapter [8])注入影像的語意特徵。
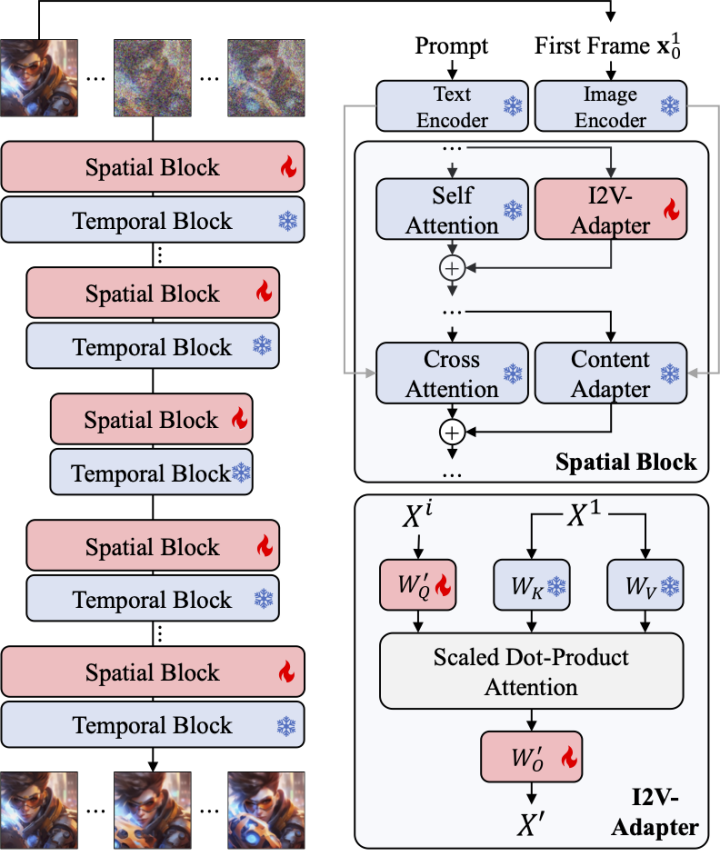
Frame Similarity Prior
#為了進一步增強產生結果的穩定性,研究者提出了幀間相似性先驗,用於在生成影片的穩定性和運動強度之間取得平衡。其關鍵假設是,在相對較低的高斯雜訊水準上,具有雜訊的第一幀和帶雜訊的後續幀足夠接近,如下圖所示:
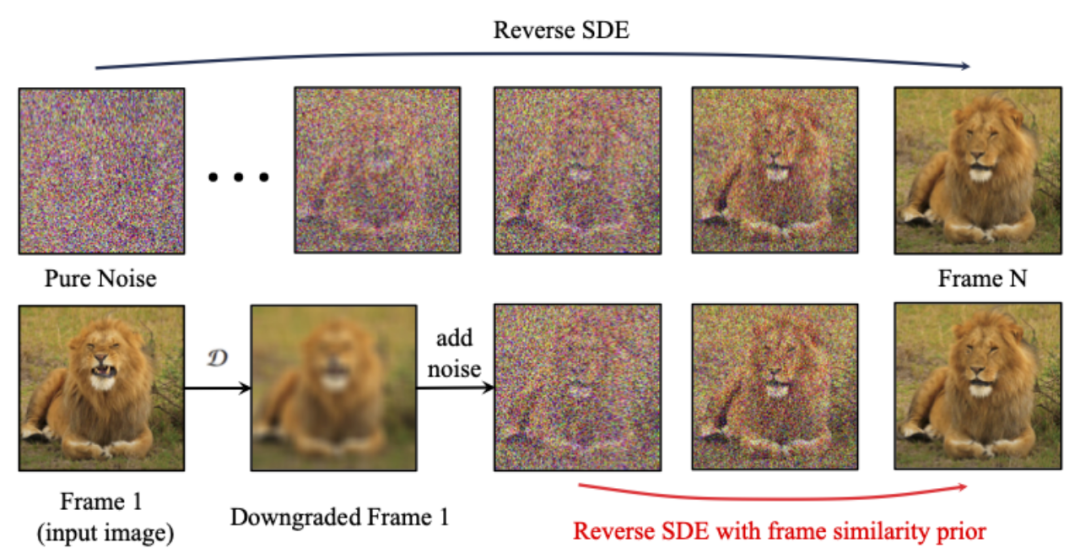
於是,研究者假設所有幀結構相似,並在加入一定量的高斯雜訊後變得難以區分,因此可以把加噪後的輸入影像作為後續影格的先驗輸入。為了排除高頻資訊的誤導,研究者還使用了高斯模糊算子和隨機遮罩混合。具體來說,運算由下式給出:

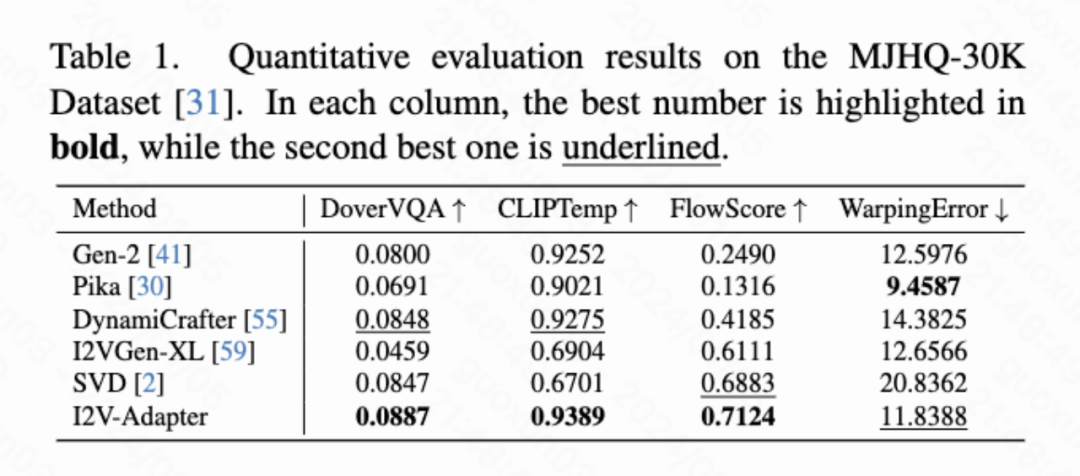
定量結果
本文計算了四種定量指標分別是DoverVQA (美學評分)、CLIPTemp (首幀一致性)、FlowScore (運動幅度) 以及WarppingError (運動誤差)用於評價生成影片的品質。表 1 顯示 I2V-Adapter 得到了最高的美學評分,在首幀一致性上也超過了所有對比方案。此外,I2V-Adapter 產生的影片有著最大的運動幅度,並且相對較低的運動誤差,表明此模型的能夠產生更動態的影片並且同時保持時序運動的準確性。
定性結果
#Image Animation(左為輸入,右為輸出):



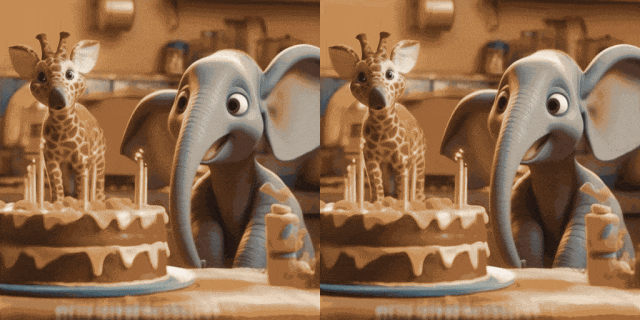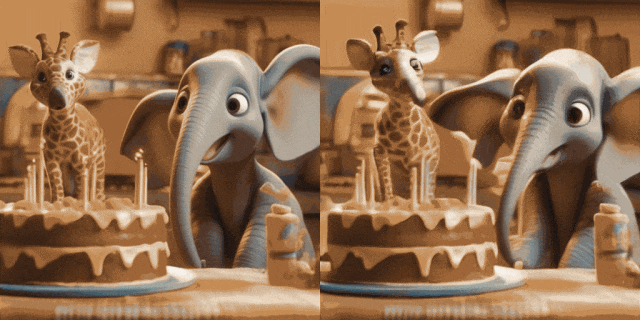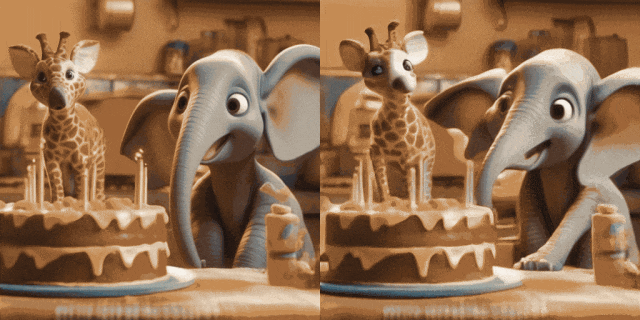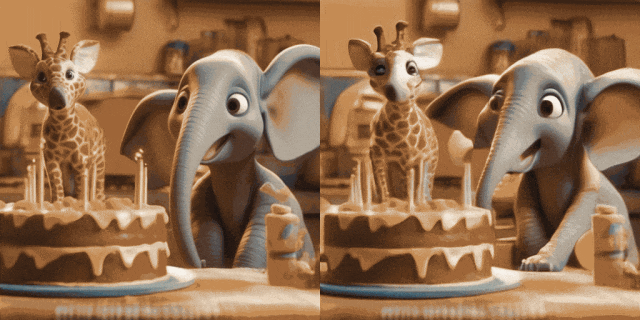
w/ Personalized T2Is(左為輸入,右為輸出):




##w/ ControlNet(左為輸入,右為輸出):



本文提出了 I2V-Adapter,一個即插即用的輕量級模組,用於圖像到視訊生成任務。此方法保留原始T2V 模型的spatial block 與motion block 結構與參數固定,並行輸入不加噪的第一幀與加噪的後續幀,透過注意力機制允許所有幀與無雜訊的第一幀交互,從而產生時序連貫且與首格一致的影片。研究者透過定量與定性實驗證明了該方法在 I2V 任務上的有效性。此外,其解耦設計使得該方案能夠直接結合 DreamBooth、Lora 與 ControlNet 等模組,證明了該方案的兼容性,也促進了定制與可控圖像到視頻生成的研究。
以上是SD社群的I2V-Adapter:無需配置,即插即用,完美相容於圖生視訊插件的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















