

模型評估是深度學習和機器學習中非常重要的一部分,用於衡量模型的性能和效果。本文將逐步分解混淆矩陣,準確性,精確度,回想率和F1分數

#混淆矩陣用於評估模型在分類問題中的表現,它是一個展示模型對樣本分類情況的表格。行代表實際類別,列代表預測類別。對於二分類問題,混淆矩陣的結構如下所示:
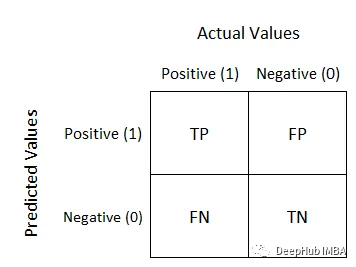
初學者看起來很亂,但實際上這很簡單。後面的Negative/Positive是模型預測值,前面的True/False是模型預測的準確度。例如,True Negative表示模型預測為Negative且與實際值相符,即預測正確。這樣就容易理解了。以下是一個簡單的混淆矩陣:
from sklearn.metrics import confusion_matrix import seaborn as sns import matplotlib.pyplot as plt # Example predictions and true labels y_true = [1, 0, 1, 1, 0, 1, 0, 0, 1, 0] y_pred = [1, 0, 1, 0, 0, 1, 0, 1, 1, 1] # Create a confusion matrix cm = confusion_matrix(y_true, y_pred) # Visualize the blueprint sns.heatmap(cm, annot=True, fmt="d", cmap="Blues", xticklabels=["Predicted 0", "Predicted 1"], yticklabels=["Actual 0", "Actual 1"]) plt.xlabel("Predicted") plt.ylabel("Actual") plt.show()當你想強調正確的預測和整體準確度時,使用TP和TN。當你想了解你的模型所犯的錯誤類型時,使用FP和FN。例如,在誤報成本很高的應用程式中,最小化誤報可能是至關重要的。
舉個例子,我們來談談垃圾郵件分類器。混淆矩陣可以幫助我們了解該分類器正確識別了多少封垃圾郵件,以及錯誤地將多少封非垃圾郵件標記為垃圾郵件
基於混淆矩陣,可以計算許多其他評估指標,例如準確度、精確度、召回率和F1分數。
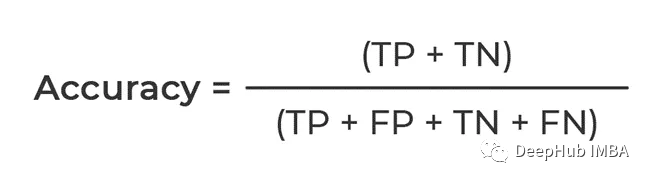
#根據我們上面的總結,計算的是能夠正確預測的的比例,分子是TP和TN都是True,也就是模型預測對了的總數

# #可以看到公式,他計算的是Positive 的佔比,也就是說數據中所有Positive的,正確預測對了有多少,所以精確度Precision又被稱作查準率
在誤報有重大後果或成本的情況下,這一點變得非常重要。以醫學診斷模型為例,精確度的確保確保只有真正需要治療的人接受治療
回收率,又稱為敏感度或真陽性率,是指模型捕捉到所有正類實例的能力
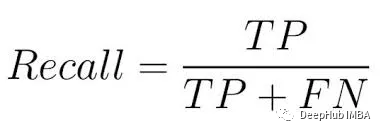
#從公式中可以看出,它的主要目的是計算模型所捕捉的實際正例的數量,也就是正例的比例。因此,Recall又被稱為查全率
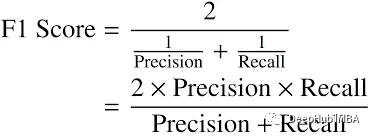
#F1分數的計算公式為: F1 = 2 * (精確度 * 召回率) / (精確度 召回率) 其中,精確度是指模型預測為正例的樣本中,實際為正例的比例;召回率是指模型正確預測為正例的樣本數佔所有實際為正例的樣本數的比例。 F1分數是精確度和召回率的調和平均值,它能夠綜合考慮模型的準確性和全面性,以評估模型的表現
# In this article, we introduced the confusion matrix, accuracy, precision, recall and F1 score in detail, and pointed out that these indicators can effectively evaluate and Improve model performanceSummary
以上是一文讀懂分類模型評估指標的詳細內容。更多資訊請關注PHP中文網其他相關文章!


































