

| 導讀 | 截止到 8 月 20 日,《戰狼Ⅱ》上映的第 25 天,它的票房已超 50 億人民幣,真正成為唯一一部挺進世界影史票房前 100 名的亞洲電影。本文透過 Python 爬蟲的方式取得數據,對豆瓣電影評論進行分析,並製作了豆瓣影評的雲圖。現在,讓我們來看看,《戰狼Ⅱ》評論裡到底藏著哪些有趣的潛台詞。 |

#拋開爆炸的票房不說,電影還激起了觀眾各種情緒,甚至有人放狠話說:敢噴《戰狼Ⅱ》的,要么是智障,要么是公敵,就是這麼簡單粗暴。
大家對《戰狼Ⅱ》褒貶不一,紛紛在豆瓣短評上面留言,表達自己對這部電影的看法。儘管各路評論出街,媒體鬧得沸沸揚揚,觀眾還是傻傻分不清楚哪邊意見比較可靠。
截至目前為止已經有超過十五萬的評論,在你看評論的時候,你可能在一段時間裡看到的大部分是表揚或者是貶低的評論。那麼透過瀏覽評論我們很難看出大家對於這部電影的整體狀況。現在讓我們透過數據分析的方法來看看在這些評論中究竟發生了什麼有趣的事情!
本文透過 Python 爬蟲的方式取得數據,對豆瓣電影評論進行分析,製作了豆瓣影評的雲圖。現在,讓我們來看看,《戰狼Ⅱ》評論裡到底藏著哪些有趣的潛台詞。
資料的取得本文採用的是 Python 爬蟲的方式取得的數據,用到的主要是 requests 套件與正規套件 re,程式並未對驗證碼進行處理。之前也爬取過豆瓣的網頁,當時由於爬取的內容少,所以並沒有遇到驗證碼的事情。在寫本文爬蟲的時候,原以為也不會有驗證碼,但是當爬取到大概 15000 個評論的時候跳出來驗證碼。
然後我就想不就是十二萬嗎?最多我也就是輸入大概十幾次驗證碼,所以就沒有處理驗證碼的事情。但接下來的事情就有點坑到我了,爬取15000 左右評論並輸入驗證碼的時候,我以為會接下來爬取到30000 左右,可是才爬了3000 左右就不行了,還是要輸驗證碼。
然後就一直這樣,跌跌撞撞,有時候爬取好長時間才需要驗證碼,有時候則不是。不過最後還是把評論爬上來了。爬取的內容主要是:用戶名,是否看過,評論的星星點數,評論時間,認為有用的人數,評論內容。以下是 Python 爬蟲的程式碼:
import requests<br>
import re<br>
import pandas as pd<br>
url_first='https://movie.douban.com/subject/26363254/comments?start=0'<br>
head={'User-Agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Ubuntu Chromium/59.0.3071.109 Chrome/59.0.3071.109.
html=requests.get(url_first,headers=head,cookies=cookies)<br>
cookies={'cookie':'你自己的cookie'} #也就是找到你的帳號對應的cookie<br>
reg=re.compile(r'') #下一頁<br>
ren=re.compile(r'<br>(.*?)<span>.*?comment">(.*?).*?.*?</span>(.*?).*?<span .> (.*?)<span>.*?title="(.*?)"></span>.*?title="(.*?)">.*?class=""> (.*?) \n',re.S) #評論等內容</span>
while html.status_code==200:<br>
url_next='https://movie.douban.com/subject/26363254/comments' re.findall(reg,html.text)[0]<br>
zhanlang=re.findall(ren,html.text)<br>
data=pd.DataFrame(zhanlang)<br>
data.to_csv('/home/wajuejiprince/文檔/zhanlang/zhanlangpinglun.csv', header=False,index=False,mode='a ') #寫入csv檔案,'a '是追加模式<br>
data=[]<br>
zhanlang=[]<br>
html=requests.get(url_next,cookies=cookies,headers=head)<br>#
以上程式碼注意設定你自己的 User-Agent,Cookie,CSV 儲存路徑等,爬取的內容儲存成 CSV 格式的檔案。
首先載入要用到的所有套件:
library(data.table)
library(plotly)<br>
library(stringr)<br>
library(jiebaR)<br>
library(wordcloud2)<br>
library(magrittr)<br>#
導入資料並清洗:
dt
plot_ly(my_dt[,.(.N),by=.(五星數)],type = 'bar',x=~五星數,y=~N)
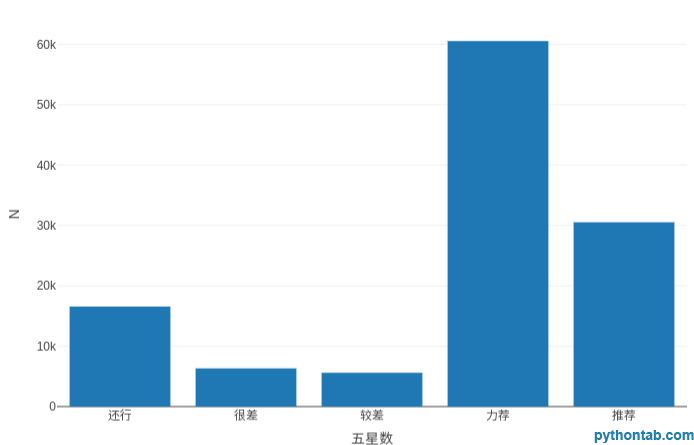
五角星的數量對應 5 個等級,5 顆星代表力薦,4 顆星代表推薦,3 顆星代表還行,2 顆星代表較差,1 顆星代表很差。
透過五角星的評論顯而易見,我們有理由相信絕大部分觀眾對這部電影持滿意態度。
首先我們應該先進行評論的分詞:
wk <br>
整體評論雲圖展示:<br>
<code>words�ta.table()<br>
setnames(words,"N","pinshu")<br>
words[pinshu>1000] #去除較低頻數的詞彙(小於1000的)<br>
wordcloud2(words[pinshu>1000], size = 2, fontFamily = "微軟雅黑",color = "random-light", backgroundColor = "grey")
由於資料太多,導致我的破電腦卡頓,所以在製作雲圖的時候去掉了頻數低於 1000 的詞彙。雲圖結果如下:

整體來看,大家對這不影片的評論還是不錯!劇情,動作,愛國等話題是大家談論的焦點。
評價關鍵字:吳京、個人英雄主義、主旋律、中國、主角光環、達康書記、很燃。
可見,「燃」並不是看完後最多的回饋,觀眾更多是對吳京本人的讚嘆,以及對愛國主義和個人主義的評價。
不同評論等級的雲圖展示但是如果把不同評價的人的評論分別展示會是什麼樣子呢?也就是對五個等級(力薦,推薦,還行,較差,很差)的評論內容製作雲圖,程式碼如下(只要改變程式碼中力薦為其他即可)。
1. 力薦的評論人的評論雲圖




從不同的評論的分詞結果來看,他們都有一個共同的主題:愛國。
在力薦的評論中可能愛國話題的基數比很差的評論中的多,在力薦的評論中人們更願意討論的是愛國話題之外的事情。在很差的評論中人們討論的大多是愛國話題。而且他們佔的比例很有意思,從力薦的人到評論很差的人,愛國話題的比例逐漸增加。
我們不能主觀的認為誰對誰錯,只能說他們站在的角度不一樣,所以看到的結果也不太一樣。當我們和別人意見不同時,往往是所處的角度不同。評論很差的人考慮的更多的是愛國的話題吧(這裡只是愛國話題的討論,並不是誰愛不愛國)! !
分析完了,這部《戰狼2》之所以能獲得這麼多人的支持,根本原因還是在於從製作上實現了《戰狼1》所沒有的美國大片級大場面,同時在愛國主義上引起了共鳴,激起了民心。
以上是Python爬蟲類分析《戰狼》影評的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















