

想將一份文件圖片轉換成Markdown格式?
以往這項任務需要文字辨識、佈局偵測與排序、公式表格處理、文字清洗等多個步驟-
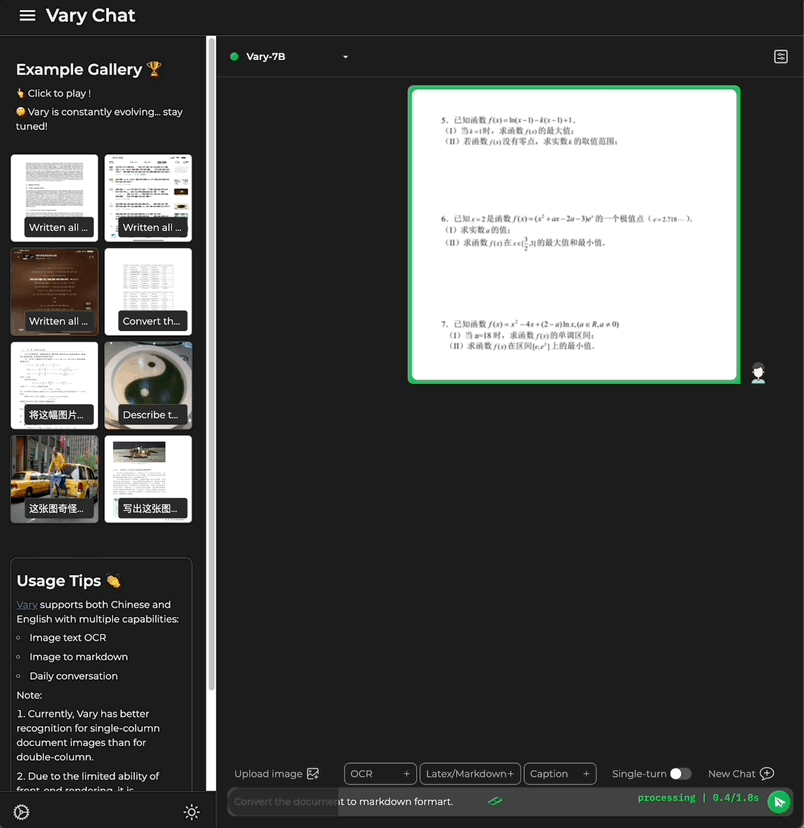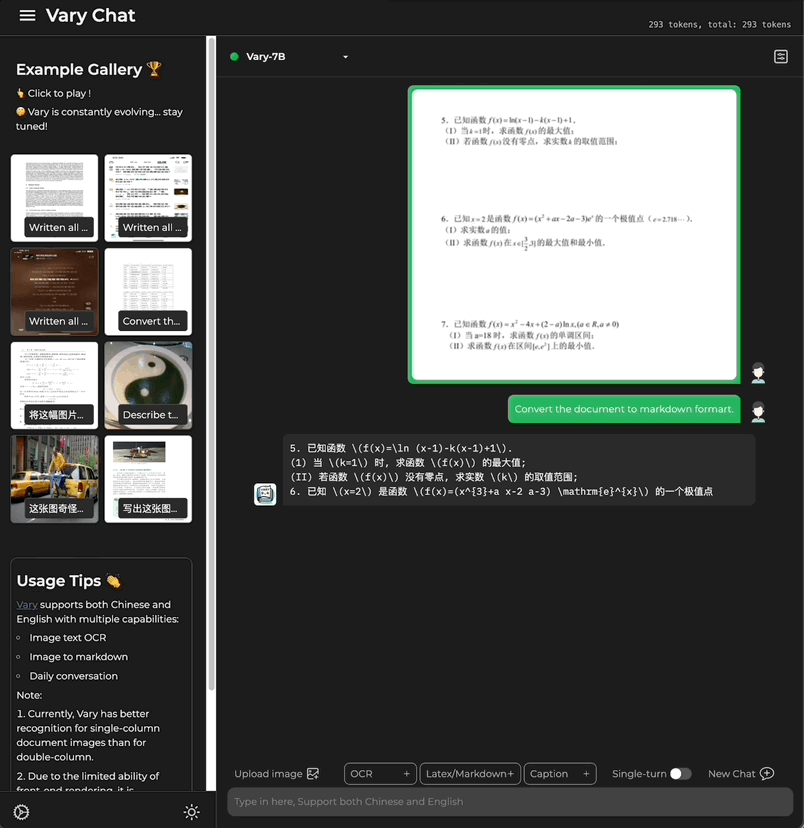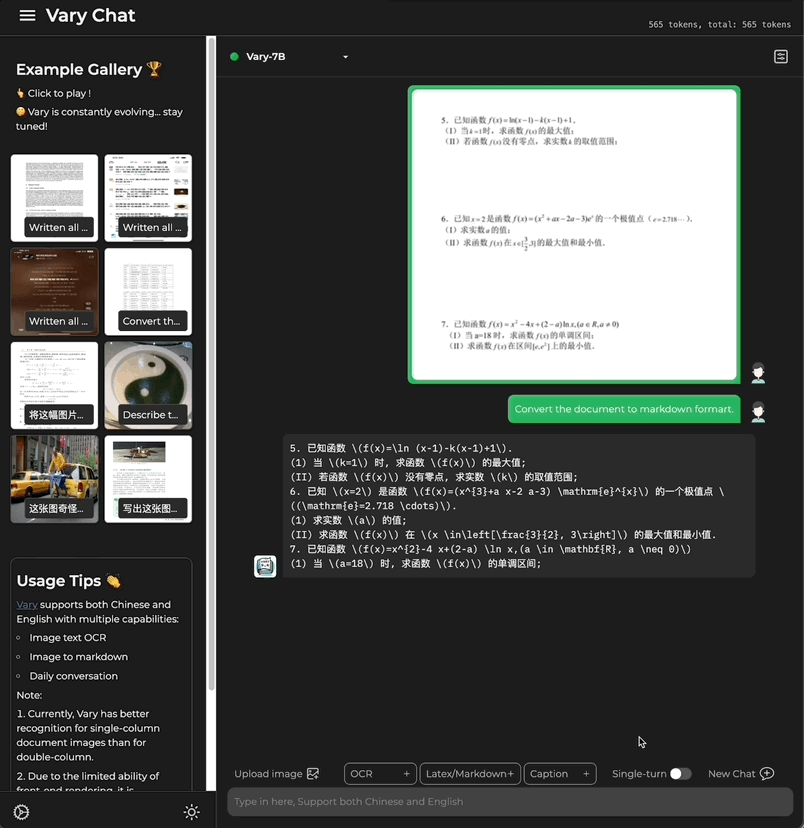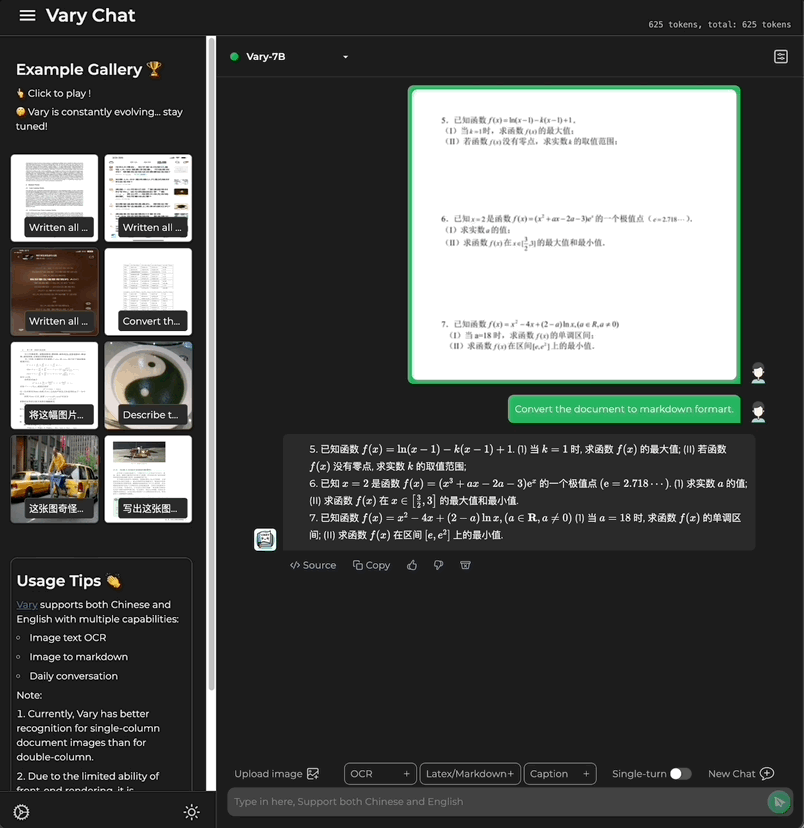
這次,只需一句話指令,多模態大模型Vary直接端對端輸出結果:
 #圖片
#圖片
無論是中英文的大段文字:
 圖片
圖片
也包含了公式的文件圖片
 ##圖片
##圖片
 圖片
圖片
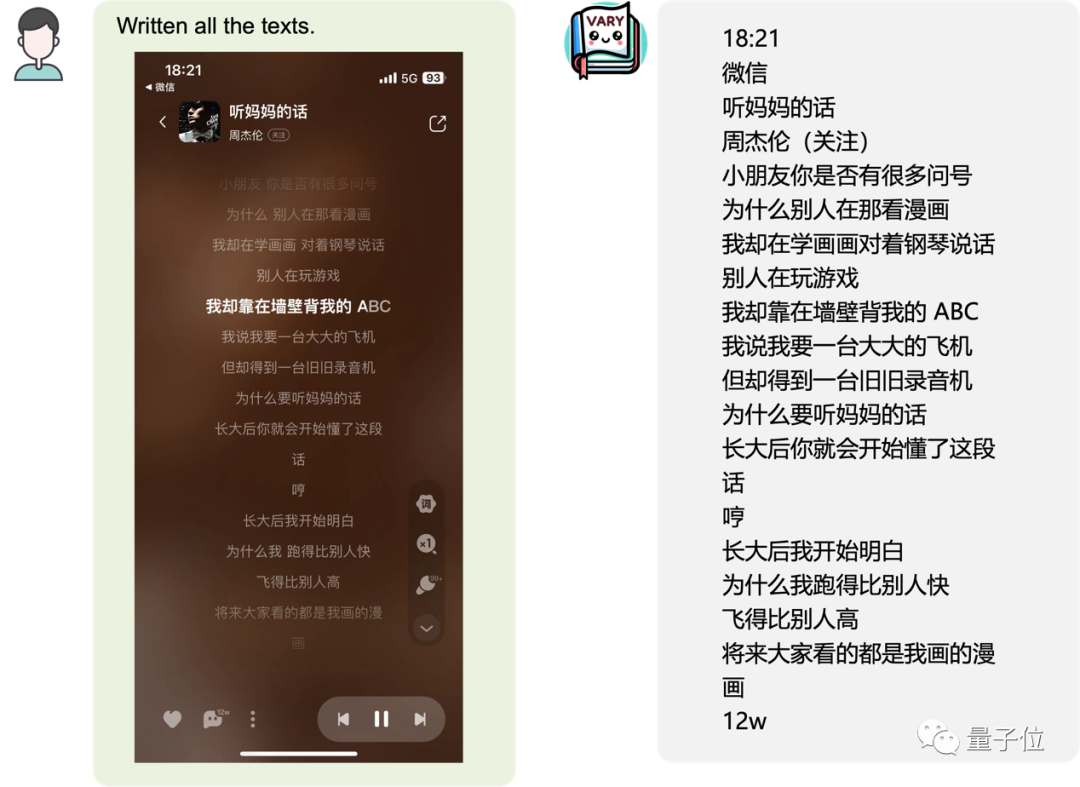
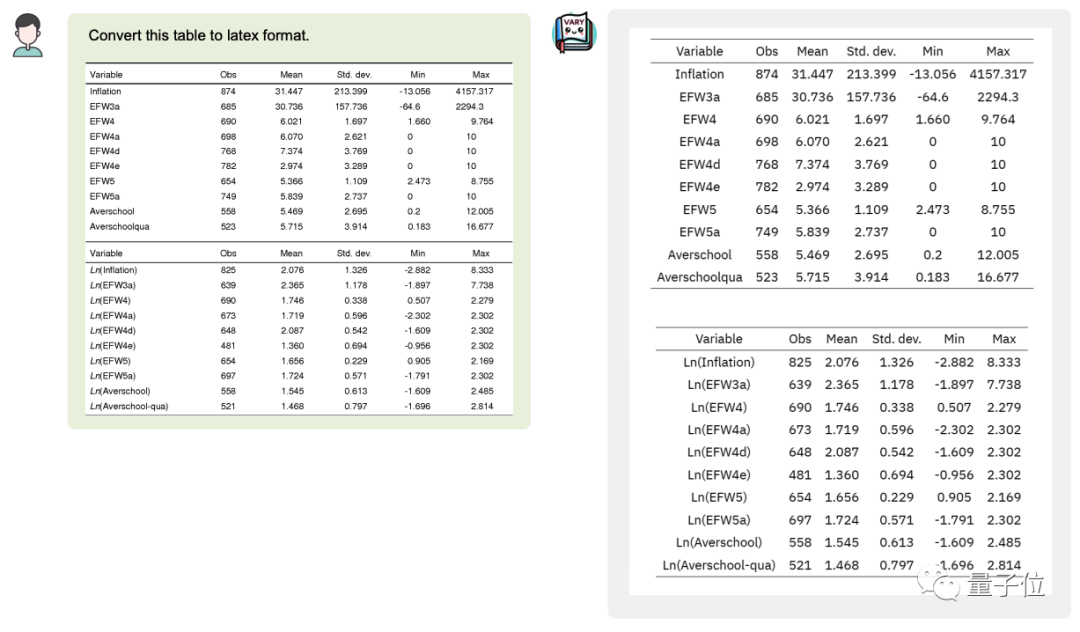
#甚至可以將圖片中的表格轉換成latex格式:
 圖片
圖片
 #圖片
#圖片
 圖片
圖片
編碼低效和out-of-vocabulary問題。
純NLP大模型(如LLaMA)從英文過渡到中文(對大模型來說是“外語”)時,因為原始詞表編碼中文效率低,必須要擴大text詞表才能實現較好的效果。 研究團隊從中得到了啟發,正是因為這個特點現在基於CLIP視覺詞表的多模態大模型,面臨著同樣的問題,遇到“foreign language image ”,如一頁論文密密麻麻的文字,很難有效率地將圖片token化。 Vary是為解決這個問題而提供的解決方案,它可以在不重新建立原始詞表的情況下,高效地擴充視覺詞表 圖片
圖片
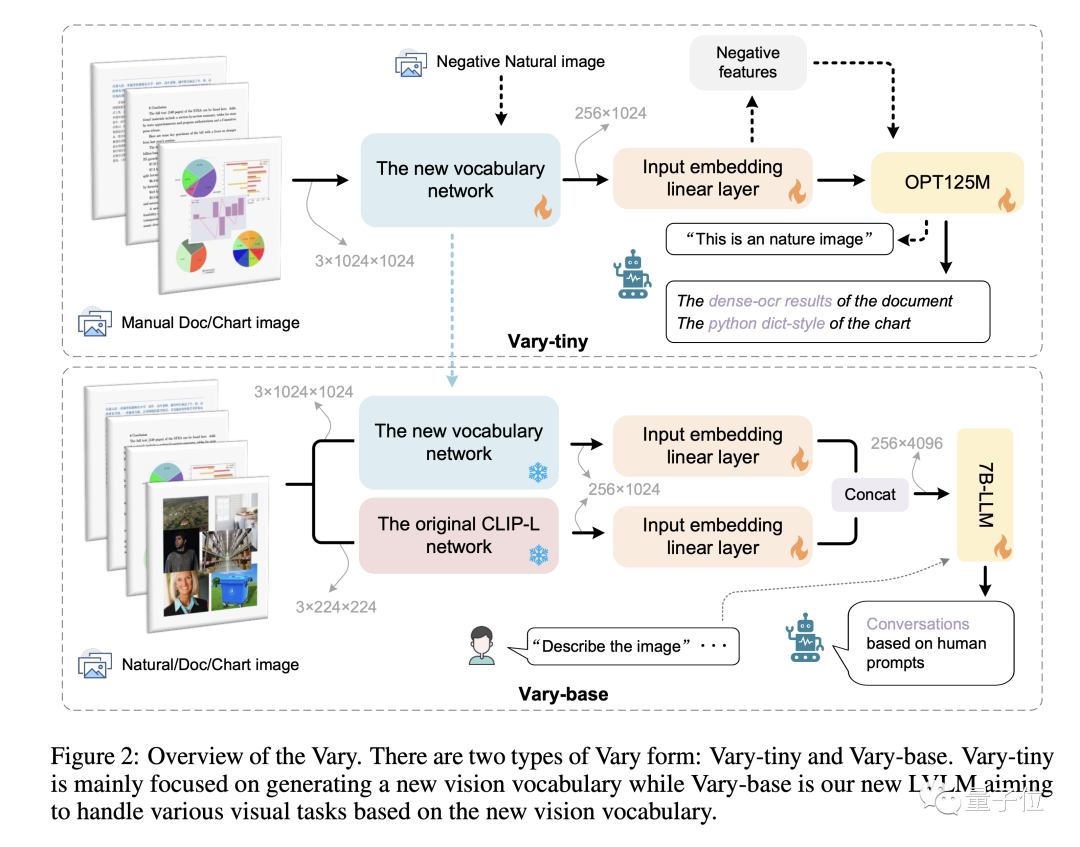
在維持vanilla多模態能力的同時,激發出了端到端的中英文圖片、公式截圖和圖表理解能力。
另外,研究團隊注意到原本可能需要數千tokens 的頁面內容,透過文件圖片輸入,資訊被Vary壓縮在了256個圖片tokens中,這也為進一步的頁面分析和總結提供了更多的想像空間。
目前,Vary的程式碼和模型都已開源,也給了供大家試玩的網頁demo。
有興趣的朋友可以去試試了~
以上是曠視開源多模態大模型,支援文件級OCR,涵蓋中英文,是否標誌著OCR的終結?的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















