近日,由清華大學計算機系朱軍教授課題組發布的基於薛定諤橋的語音合成系統[1],憑藉其“數據到數據”的生成範式,在樣本質量和採樣速度兩方面,均擊敗了擴散模型的「雜訊到資料」範式。 
論文連結:https://arxiv.org/abs/2312.03491計畫網站:https://bridge-tts.github.io/ 程式碼實作:https://github.com/thu-ml/Bridge-TTS自2021 年起,擴散模型(diffusion models)開始成為文字轉語音合成(text-to-speech, TTS)領域的核心生成方法之一,如華為諾亞方舟實驗室提出的Grad-TTS [2]、浙江大學提出的DiffSinger [3] 等方法均實現了較高的生成品質。此後,又有許多研究工作有效提升了擴散模型的採樣速度,如透過先驗優化 [2,3,4]、模型蒸餾 [5,6]、殘差預測 [7] 等方法。然而,如此項研究所示,由於擴散模型受限於「雜訊到資料」的生成範式,其先驗分佈對產生目標提供的資訊始終較為有限,且對條件資訊無法利用充分。 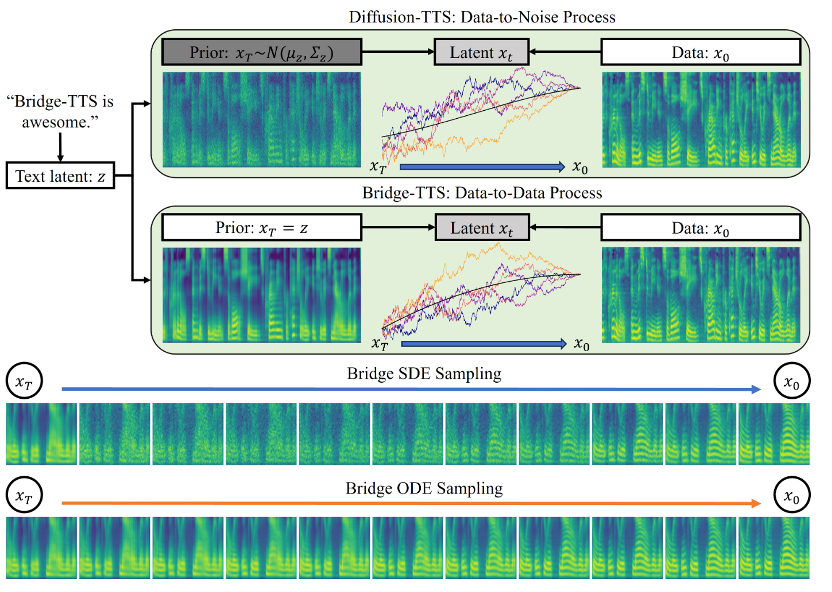
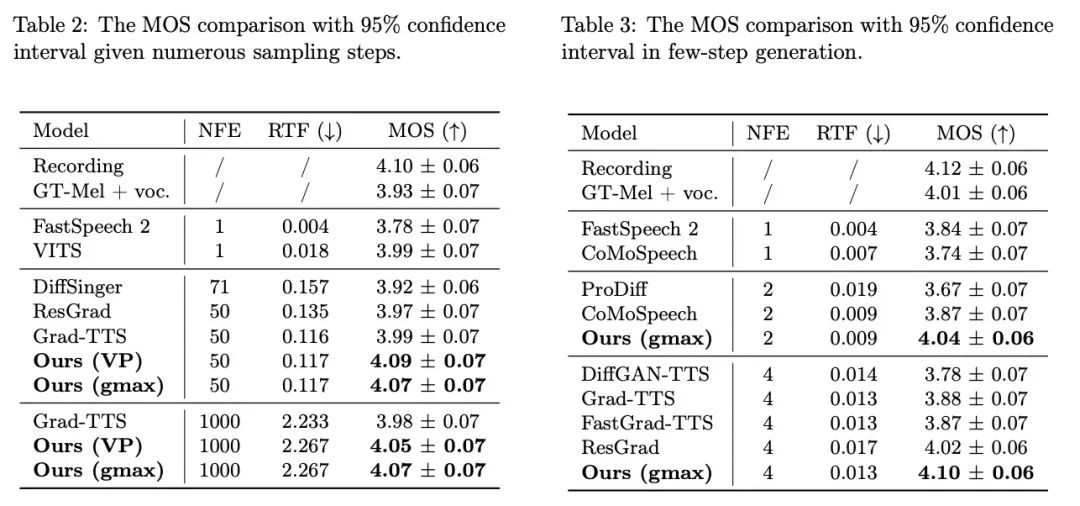
本次語音合成領域的最新研究工作,Bridge-TTS,憑藉其基於薛定諤橋的生成框架,實現了“數據到數據”的生成過程,首次將語音合成的先驗資訊由雜訊修改為乾淨資料,由分佈修改為確定性表徵。 此方法的主要架構如上圖所示,輸入文字首先經由文字編碼器擷取出生成目標(mel-spectrogram, 梅爾譜)的隱空間表徵。此後,與擴散模型將此信息併入噪聲分佈或用作條件信息不同,Bridge-TTS 的方法支持直接將其作為先驗信息,並支持通過隨機或確定性採樣的方式,高質量、快速地生成目標。 在驗證語音合成品質的在標準資料集LJ-Speech 上,研究團隊將 Bridge-TTS 與9 項高品質的語音合成系統和擴散模型的加速採樣方法進行了比較。如下所示,該方法在樣本品質上(1000 步、50 步採樣)擊敗了基於擴散模型的高品質TTS 系統[2,3,7],並在採樣速度上,在無需任何後處理如額外模型蒸餾的條件下,超過了眾多加速方法,如殘差預測、漸進式蒸餾、以及最新的一致性蒸餾等工作[5,6,7]。 以下是Bridge-TTS 與基於擴散模型方法的產生效果範例,更多產生樣本比較可存取專案網站:https://bridge-tts.github. io/
輸入文字:「Printing, then, for our purpose, may be considered as the art of making books by means of movable types.」 #輸入文字:「The first books were printed in black letter, i.e. the letter which was a Gothic development of the ancient Roman character,”
#輸入文字:「The first books were printed in black letter, i.e. the letter which was a Gothic development of the ancient Roman character,” 輸入文字:「The prison population fluctuated a great deal,」
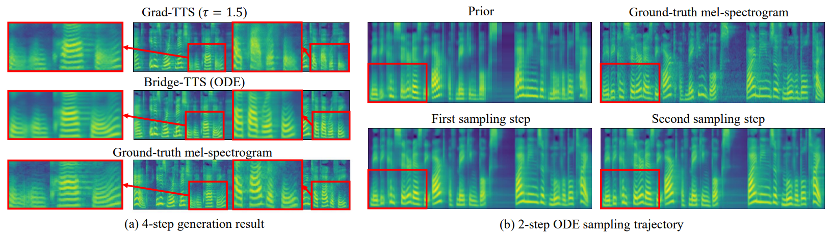
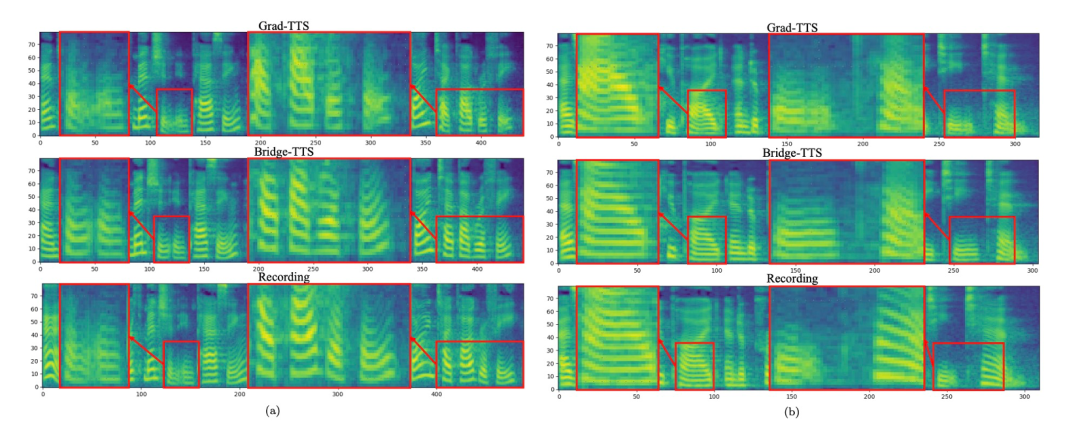
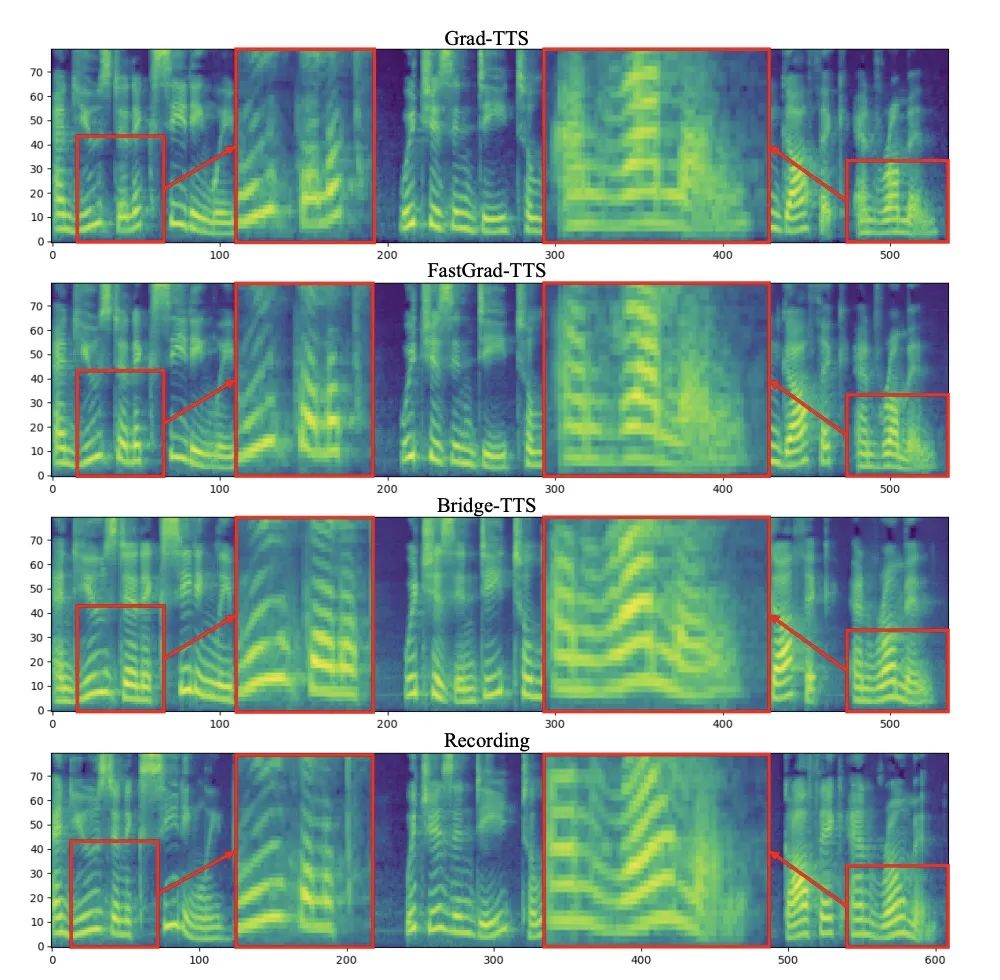
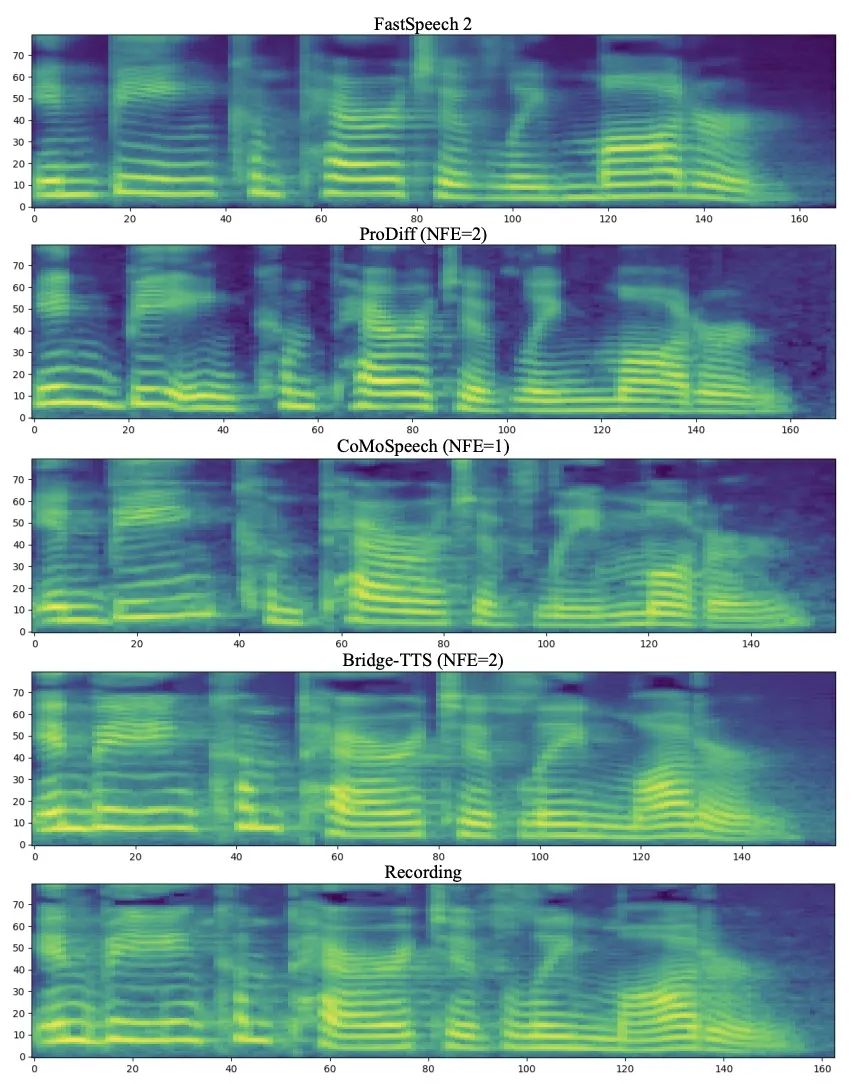
輸入文字:「The prison population fluctuated a great deal,」 下面展示了Bridge- TTS 一個在2 步和4 步的一個確定性合成(ODE sampling)案例。在 4 步驟合成中,此方法相較於擴散模型顯著合成了更多樣本細節,並沒有雜訊殘留的問題。在 2 步驟合成中,該方法展示了完全純淨的採樣軌跡,並在每一步中採樣完善了更多的生成細節。 在頻域中,更多的生成樣本如下所示,在1000 步合成中,該方法相較於擴散模型產生了更高品質的梅爾譜,當取樣步數降到50 步時,擴散模型已經犧牲了部分取樣細節,而基於薛丁格橋的方法仍保持著高品質的生成效果。在 4 步和 2 步合成中,該方法不需要蒸餾、多階段訓練、和對抗損失函數,仍然實現了高品質的生成效果。 在1000 步驟合成中,Bridge-TTS與基於擴散模型的方法的梅爾譜對比
下面展示了Bridge- TTS 一個在2 步和4 步的一個確定性合成(ODE sampling)案例。在 4 步驟合成中,此方法相較於擴散模型顯著合成了更多樣本細節,並沒有雜訊殘留的問題。在 2 步驟合成中,該方法展示了完全純淨的採樣軌跡,並在每一步中採樣完善了更多的生成細節。 在頻域中,更多的生成樣本如下所示,在1000 步合成中,該方法相較於擴散模型產生了更高品質的梅爾譜,當取樣步數降到50 步時,擴散模型已經犧牲了部分取樣細節,而基於薛丁格橋的方法仍保持著高品質的生成效果。在 4 步和 2 步合成中,該方法不需要蒸餾、多階段訓練、和對抗損失函數,仍然實現了高品質的生成效果。 在1000 步驟合成中,Bridge-TTS與基於擴散模型的方法的梅爾譜對比 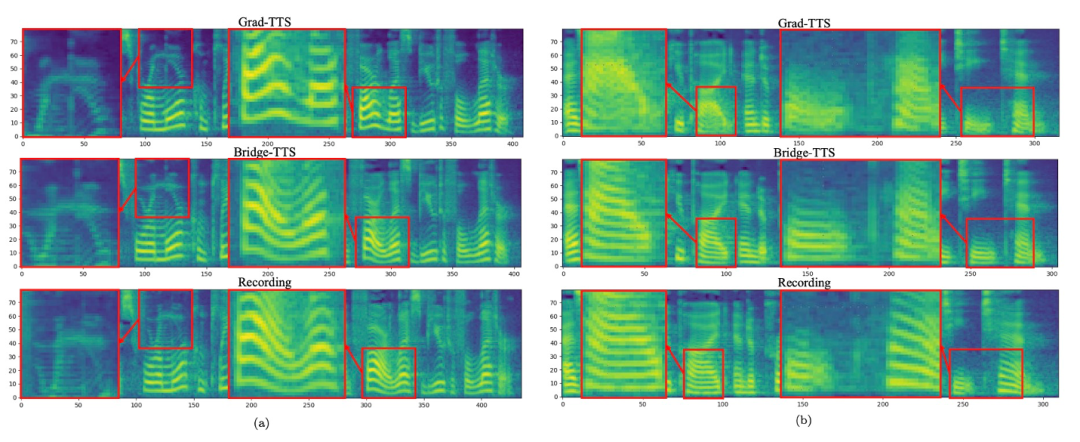
在50 步驟合成中,Bridge-TTS與基於擴散模型的方法的梅爾譜對比
在4 步驟合成中,Bridge-TTS與基於擴散模型的方法的梅爾譜對比 在2 步驟合成中,Bridge-TTS與基於擴散模型的方法的梅爾譜對比 Bridge-TTS一經發布,憑藉其在語音合成上新穎的設計與高品質的合成效果,在Twitter 上引起了熱烈關注,獲得了百餘次轉發和數百次點贊,入選了Huggingface 在12.7 的Daily Paper 並在當日獲得了支持率第一名,同時在LinkedIn、微博、知乎、小紅書等多個國內外平台被關注與轉發報道。 薛丁格橋(Schrodinger Bridge)是一類繼擴散模型之後,近期新興的深度生成模型,在影像生成、影像翻譯等領域都有了初步應用[8,9]。不同於擴散模型在資料和高斯雜訊之間建立變換過程,薛丁格橋支援任兩個邊界分佈之間的轉換。在 Bridge-TTS 的研究中,作者們提出了一個基於成對資料間薛定諤的語音合成框架,靈活支持多種前向過程、預測目標、及取樣過程。其方法概覽如下圖所示: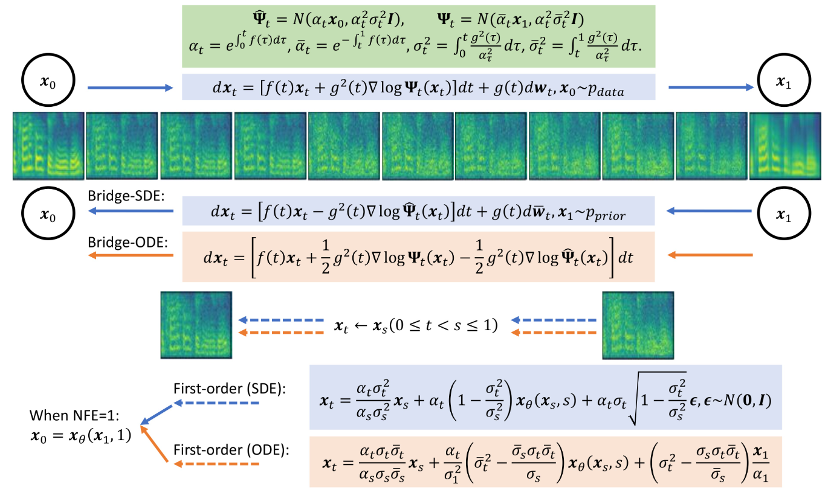
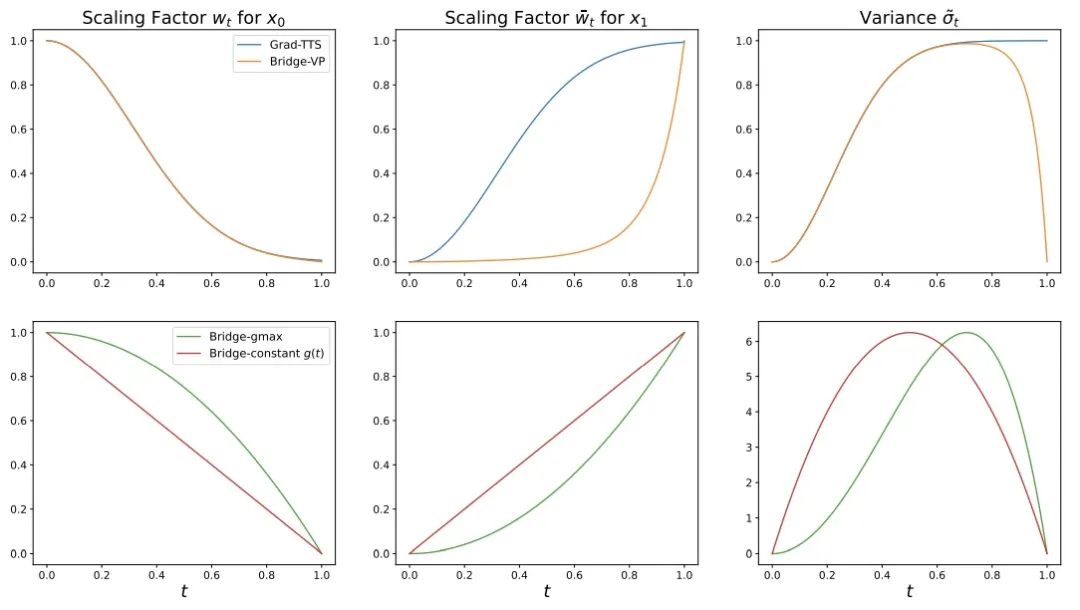
- #前向過程:此研究在強資訊先驗與產生目標之間搭建了完全可解的薛丁格橋,支援靈活的前向過程選擇,如對稱噪音策略:
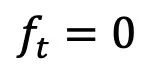 、常數
、常數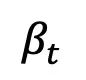 ,和非對稱噪音策略:
,和非對稱噪音策略:  、線性
、線性 ,以及直接與擴散模型相對應的方差保持(VP)雜訊策略。此方法發現在語音合成任務中非對稱噪音策略:即線性
,以及直接與擴散模型相對應的方差保持(VP)雜訊策略。此方法發現在語音合成任務中非對稱噪音策略:即線性 (gmax)和 VP 過程,相較於對稱式噪音策略有較好的生成效果。
(gmax)和 VP 過程,相較於對稱式噪音策略有較好的生成效果。

- 模型訓練:此方法維持了擴散模型訓練過程的多個優點,如單一階段、單一模型、和單一損失函數等。並且其對比了多種模型參數化(Model parameterization)的方式,即網路訓練目標的選擇,包括噪音預測(Noise)、生成目標預測(Data)、和對應於擴散模型中流匹配技術[10,11]的速度預測(Velocity)等。文章發現以產生目標,即梅爾譜為網路預測目標時,可以達到相對較佳的生成效果。
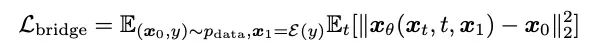
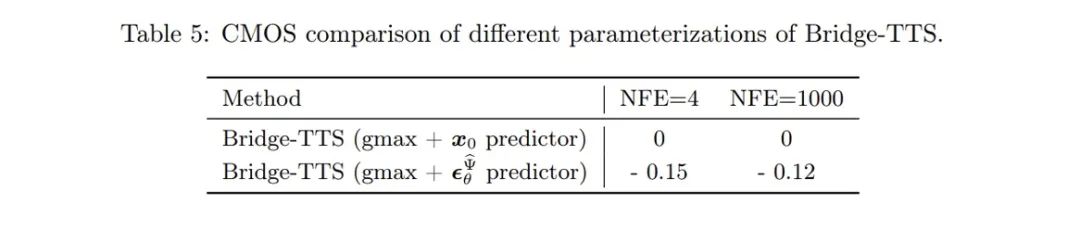
- #取樣過程:得益於本研究中薛丁格橋完全可解的形式,對薛丁格橋對應的前- 後向SDE 系統進行變換,作者們得到了Bridge SDE 和Bridge ODE 用於推斷。同時,由於直接模擬Bridge SDE/ODE 推斷速度較慢,為加快採樣,該研究借助了擴散模型中常用的指數積分器[12,13],給出了薛定諤橋的一階SDE 與ODE 採樣形式:
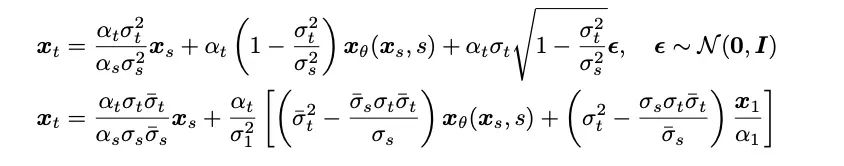
在1 步驟取樣時,其一階SDE 與ODE 的取樣形式共同退化為網路的單步預測。同時,它們與後驗採樣 / 擴散模型 DDIM 採樣有著密切聯繫,文章在附錄中給出了詳細分析。文章也同時給出了薛丁格橋的二階採樣 SDE 與 ODE 採樣演算法。作者發現,在語音合成中,其生成品質與一階取樣過程類似。 在其他任務如語音增強、語音分離、語音編輯等先驗資訊同樣較強的任務中,作者們期待此研究也會帶來較大的應用價值。 #此項研究有三位共同第一作者:陳澤華,何冠德,鄭凱文,皆屬於清華大學電腦系朱軍課題組,文章通訊作者為朱軍教授,微軟亞洲研究院首席研究經理旭譚為計畫合作者。 
# 
陳澤華是清華大學電腦系水木學者博士後,主要研究方向為機率生成模型,及其在語音、音效、生物電訊號合成等方面的應用。曾在微軟、京東、TikTok 等多家公司實習,並在語音與機器學習領域重要國際會議 ICML/NeurIPS/ICASSP 等發表多篇論文。

何冠德是清華大學在學的三年級碩士生,主要研究方向是不確定性估計與生成模型,此前在ICLR 等會議以第一作者身份發表論文。

鄭凱文是清華大學在學的二年級碩士生,主要研究方向是深度生成模型的理論與演算法,及其在圖像、音訊和 3D 生成中的應用。先前在 ICML/NeurIPS/CVPR 等頂級會議發表多篇論文,涉及了擴散模型中的流匹配和指數積分器等技術。 #[1] Zehua Chen, Guande He , Kaiwen Zheng, Xu Tan, and Jun Zhu. Schrodinger Bridges Beat Diffusion Models on Text-to-Speech Synthesis. arXiv preprint arXiv:2312.03491, 2023. [2] Vadim Popov, Ivan Vovk, Vladimir Gogoryan, Tasnima Sadekova, and Mikhail A. Kudinov. Grad-TTS: A Diffusion Probabilistic Model for Text-to-Speech. In ICML, 2021. [3] Jinglin Liu, Chengxi Li, Yi Ren, Feiyang Chen, and Zhou Zhao. DiffSinger: Singing Voice Synthesis via Shallow Diffusion Mechanism. In AAAI, 2022.################################### # ###########[4] Sang-gil Lee, Heeseung Kim, Chaehun Shin, Xu Tan, Chang Liu, Qi Meng, Tao Qin, Wei Chen, Sungroh Yoon, and Tie-Yan Liu. PriorGrad : Improving Conditional Denoising Diffusion Models with Data-Dependent Adaptive Prior. In ICLR, 2022.###################[5] Rongjie Huang, Zhou Zhao, Huadai Liu, Jing####[5] Rongjie Huang, Zhou Zhao, Huadai Liu, Jing####[5] Rongjie Huang, Zhou Zhao, Huadai Liu, Jing####[5] Rongjie Huang, Zhou Zhao, Huadai Liu, Jing####[5] Rongjie Huang, Zhou Zhao, Huadai Liu, Jing####[5] Rongjie Huang, Zhou Zhao, Huadai Liu, Jing####[5] Rongjie 漢, Chenye Cui, and Yi Ren. ProDiff: Progressive Fast Diffusion Model For High-Quality Text-to-Speech. In ACM Multimedia, 2022.##################[6 ] Zhen Ye, Wei Xue, Xu Tan, Jie Chen, Qifeng Liu, and Yike Guo. CoMoSpeech: One-Step Speech and Singing Voice Synthesis via Consistency Model. In ACM Multimedia, 2023.########## ########[7] Zehua Chen, Yihan Wu, Yichong Leng, Jiawei Chen, Haohe Liu, Xu Tan, Yang Cui, Ke Wang, Lei He, Sheng Zhao, Jiang Bian, and Danilo P. Mandic. ResGrad: Residual Denoising Diffusion Probabilistic Models for Text to Speech. arXiv preprint arXiv:2212.14518, 2022.##################[8] Yuyang Shi, Valentin De Borang Shi, Valentin De Borang, Andrew### , and Arnaud Doucet. Diffusion Schrödinger Bridge Matching. In NeurIPS 2023.##################[9] Guan-Horng Liu, Arash Vahdat, De-An Huang, Evangelos A . Theodorou, Weili Nie, and Anima Anandkumar. I2SB: Image-to-Image Schrödinger Bridge. In ICML, 2023.###################[10] Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow Matching for Generative Modeling. In ICLR, 2023.##################[11] Kaiwen Zheng, Cheng Lu, Jianfei Chen, and Jun Zhu. Improved Techniques for Maximum Likelihood Estimation for Diffusion ODEs. In ICML, 2023.##################[12] Cheng Lu, Yuhao################[12] Cheng Lu, Yuhao################[12] Cheng Lu, Yuhao################[12] Cheng Lu, Yuhao################[12] Cheng Lu, Yuhao################[12] Cheng Lu, Yuhao################[12] Cheng Lu, Yuhao################[12] Cheng Lu、 Zhou, Fan Bao, Jianfei Chen, Chongxuan Li, and Jun Zhu. DPM-Solver: A Fast ODE Solver for Diffusion Probabilistic Model Sampling in Around 10 Steps. In NeurIPS, 2022.############ ######[13] Kaiwen Zheng, Cheng Lu, Jianfei Chen, and Jun Zhu. DPM-Solver-v3: Improved Diffusion ODE Solver with Empirical Model Statistics. In NeurIPS, 2023.######## #以上是薛丁格橋輔助,清華朱軍團隊開發新型語音合成系統應對擴散挑戰的詳細內容。更多資訊請關注PHP中文網其他相關文章!


 、線性
、線性 ,以及直接與擴散模型相對應的方差保持(VP)雜訊策略。此方法發現在語音合成任務中非對稱噪音策略:即線性
,以及直接與擴散模型相對應的方差保持(VP)雜訊策略。此方法發現在語音合成任務中非對稱噪音策略:即線性




















