

在大型模式時代,Transformer獨自支撐了整個科學研究領域。自從發布以來,基於Transformer的語言模型在各種任務上展現出了出色的性能,在自然語言建模和推理方面的底層Transformer架構已經成為最先進的技術,在計算機視覺和強化學習等領域也顯示出了強大的前景
目前的Transformer 架構非常龐大,通常需要大量的運算資源來進行訓練和推理
##這是有意為之的,因為經過更多參數或資料訓練的Transformer 顯然比其他模型更有能力。儘管如此,越來越多的工作表明,基於 Transformer 的模型以及神經網路不需要所有擬合參數來保留其學到的假設。
一般來說,在訓練模型時大規模過度參數化似乎有幫助,但這些模型在推理之前可以進行大幅剪枝;研究表明,神經網路通常可以去除90 %以上的權重,而性能不會有明顯下降。這種現象促使研究者開始轉向研究有助於模型推理的剪枝策略
來自麻省理工學院和微軟的研究人員在一篇名為《真相就在其中:透過層選擇性排名減少提高語言模型的推理能力》的論文中提出了一個令人驚訝的發現。他們發現,在Transformer模型的特定層進行精細的剪枝可以顯著提高模型在某些任務上的表現

#研究中將這種簡單的介入措施稱為LASER(LAyer SElective Rank reduction,層選擇性降秩)。它透過奇異值分解選擇性地減少Transformer模型中特定層的學習權重矩陣的高階分量,從而顯著提高LLM的性能。這種操作可以在模型訓練完成後進行,而無需額外的參數或資料
在操作過程中,權重的減少是透過對模型特定的權重矩陣和層進行執行的。研究還發現,許多類似的矩陣都能夠顯著地減少權重,並且在刪除超過90%的組件之前,通常不會觀察到性能下降
研究還發現,減少這些因素可以顯著提高準確率。有趣的是,這項發現不僅適用於自然語言,對於強化學習也能提升表現
此外,這項研究試圖推論儲存在高階元件中的內容,以便透過刪除來提高效能。研究發現,在使用LASER回答問題後,原始模型主要使用高頻詞(如「the」、「of」等)來回應。這些詞與正確答案的語義類型甚至不相符,也就是說在沒有乾預的情況下,這些成分會導致模型生成一些不相關的高頻詞彙
然而,透過進行一定程度的降秩後,模型的回答可以轉換成正確的。
為了理解這一點,研究也探討了其餘組件各自編碼的內容,他們僅使用其高階奇異向量來近似權重矩陣。結果發現這些組件描述了與正確答案相同語義類別的不同響應或通用高頻詞。
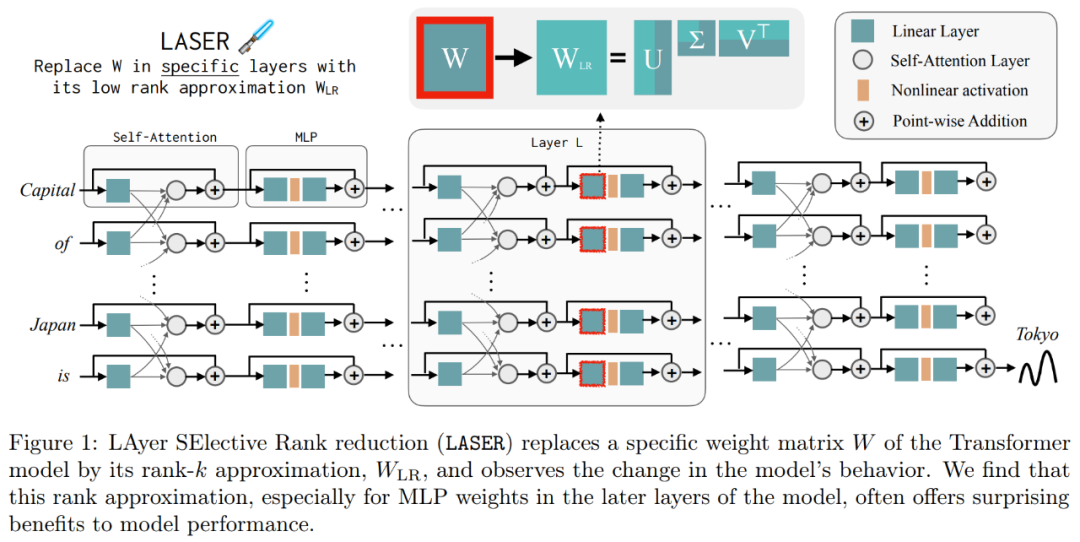
這些結果表明,當雜訊的高階分量與低階分量組合時,它們相互衝突的反應會產生一種平均答案,這可能是不正確的。圖 1 直觀地展示了 Transformer 架構和 LASER 遵循的程序。在這裡,特定層的多層感知器(MLP)的權重矩陣被替換為其低秩近似。
研究者對LASER介入進行了詳細介紹。單步LASER幹預是透過三個參數(τ、ℓ和ρ)來定義的。這些參數共同描述了要被低秩近似取代的矩陣以及近似的程度。研究者根據參數類型對待幹預的矩陣進行分類
研究者關注的重點是矩陣W = {W_q, W_k, W_v, W_o, U_in, U_out},該矩陣由多層感知機(MLP)和注意力層中的矩陣組成。層數表示研究者介入的層級,其中第一層的索引是0。例如,Llama-2有32個層級,因此表示為 ℓ ∈ {0, 1, 2,・・・31}#
最终,ρ ∈ [0, 1) 描述了在做低秩近似时应该保留最大秩的哪一部分。例如设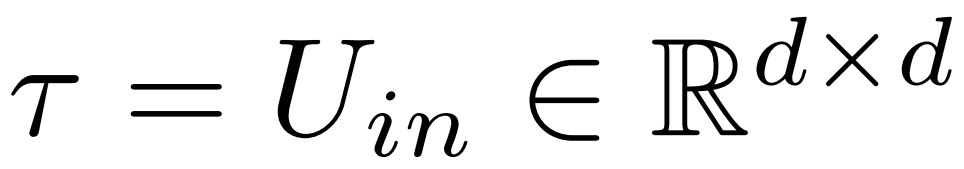 ,则该矩阵的最大秩为 d。研究者将它替换为⌊ρ・d⌋- 近似。
,则该矩阵的最大秩为 d。研究者将它替换为⌊ρ・d⌋- 近似。
以下是需要 在下图1中,展示了一个LASER的示例。图中的符号τ = U_in和ℓ = L表示在第L层的Transformer块中更新MLP的第一层权重矩阵。还有一个参数用于控制rank-k近似中的k值
LASER 可以限制网络中某些信息的流动,并出乎意料地产生显著的性能优势。这些干预也可以很容易组合起来,比如以任何顺序来应用一组干预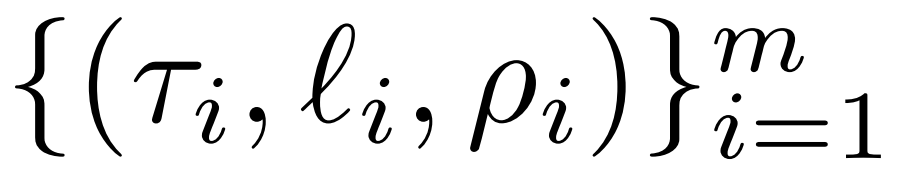 。
。
LASER 方法只是对这类干预进行简单的搜索,并修改以带来最大收益。不过,还有很多其他方法可以将这些干预组合起来,这是研究者未来工作的方向。
在实验部分,研究者使用了在 PILE 数据集上预训练的 GPT-J 模型,该模型的层数为 27,参数为 60 亿。然后在 CounterFact 数据集上评估模型的行为,该数据集包含(主题、关系和答案)三元组的样本,每个问题提供了三个释义 prompt。
首先,我们对 GPT-J 模型在 CounterFact 数据集上进行了分析。图 2 展示了在 Transformer 架构中,将不同数量的降秩应用于每个矩阵后,对数据集分类损失的影响。每个 Transformer 层由一个两层的小型 MLP 组成,输入和输出矩阵分别显示。不同颜色表示移除组件的不同百分比
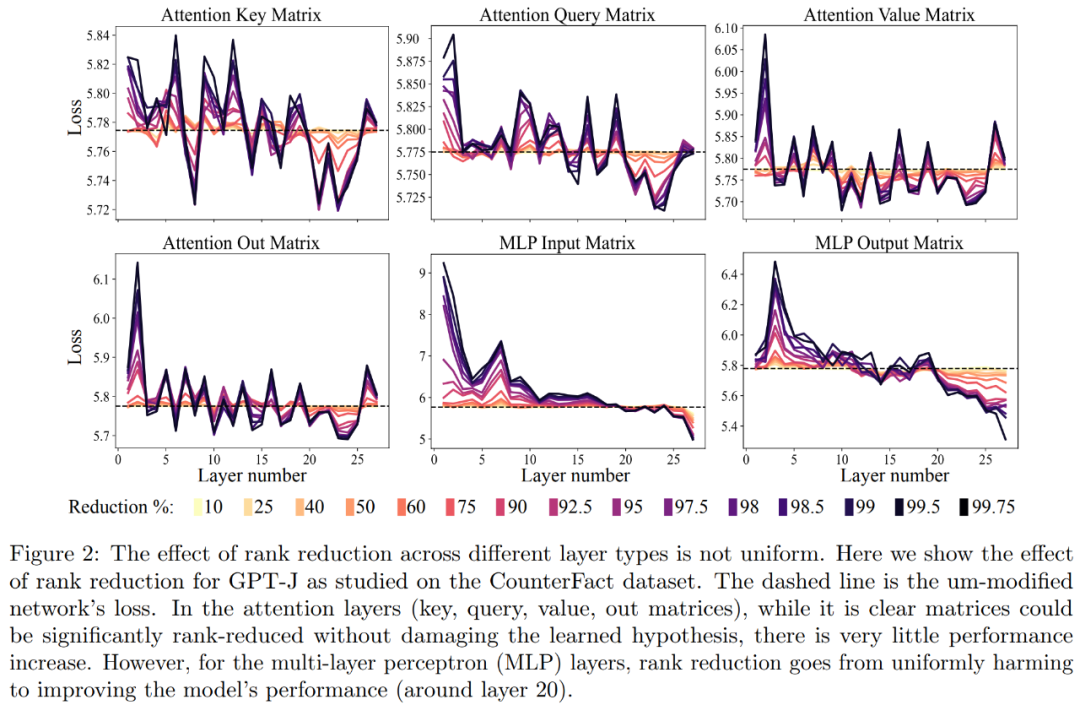
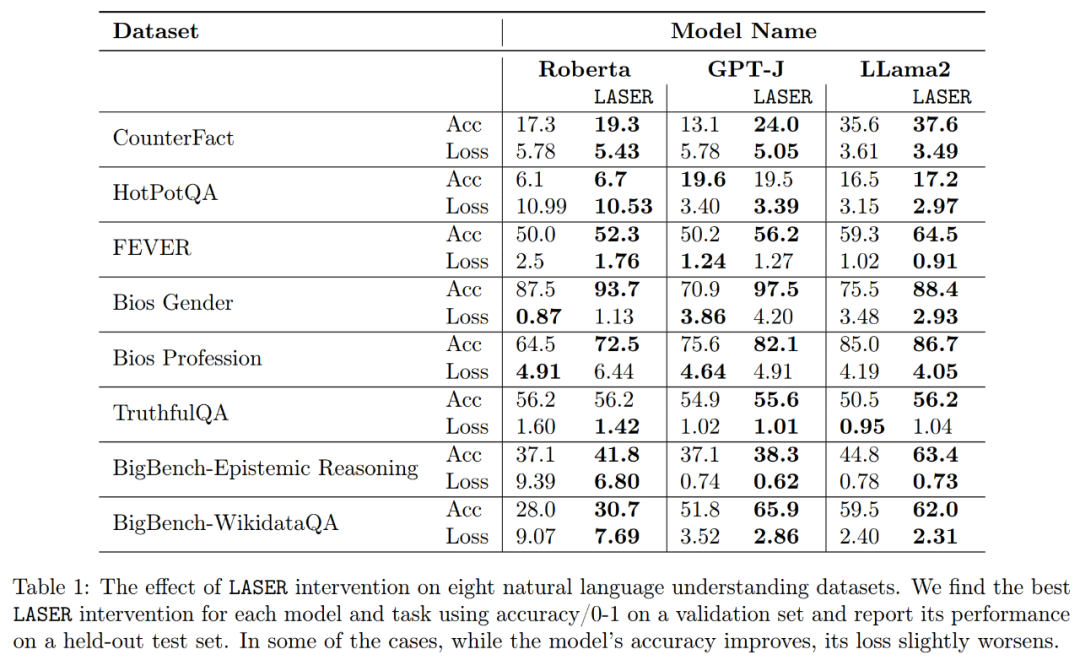
关于提升释义的准确度和稳健性,如上图 2 和下表 1 所示,研究者发现,当在单层上进行降秩时,GPT-J 模型在 CounterFact 数据集上的事实准确度从 13.1% 增加到了 24.0%。需要注意一点,这些改进只是降秩的结果,并不涉及对模型的任何进一步训练或微调。
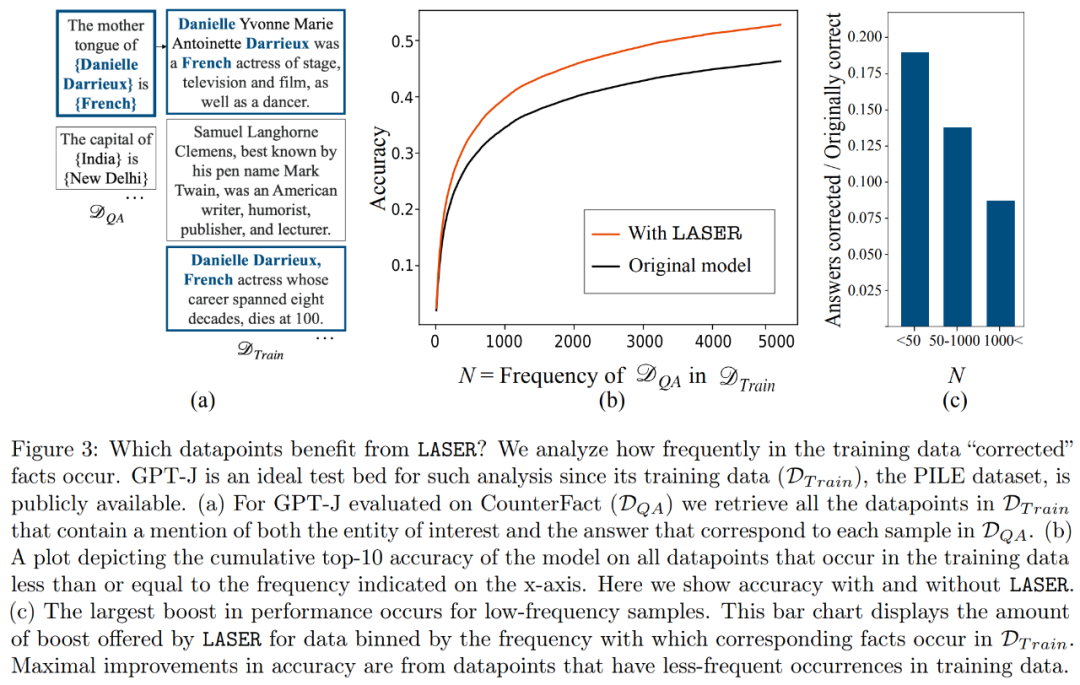
哪些事实在进行降秩恢复时会得到恢复?研究者发现,通过降秩恢复得到的事实很可能在数据集中出现的次数非常少,如图3所示
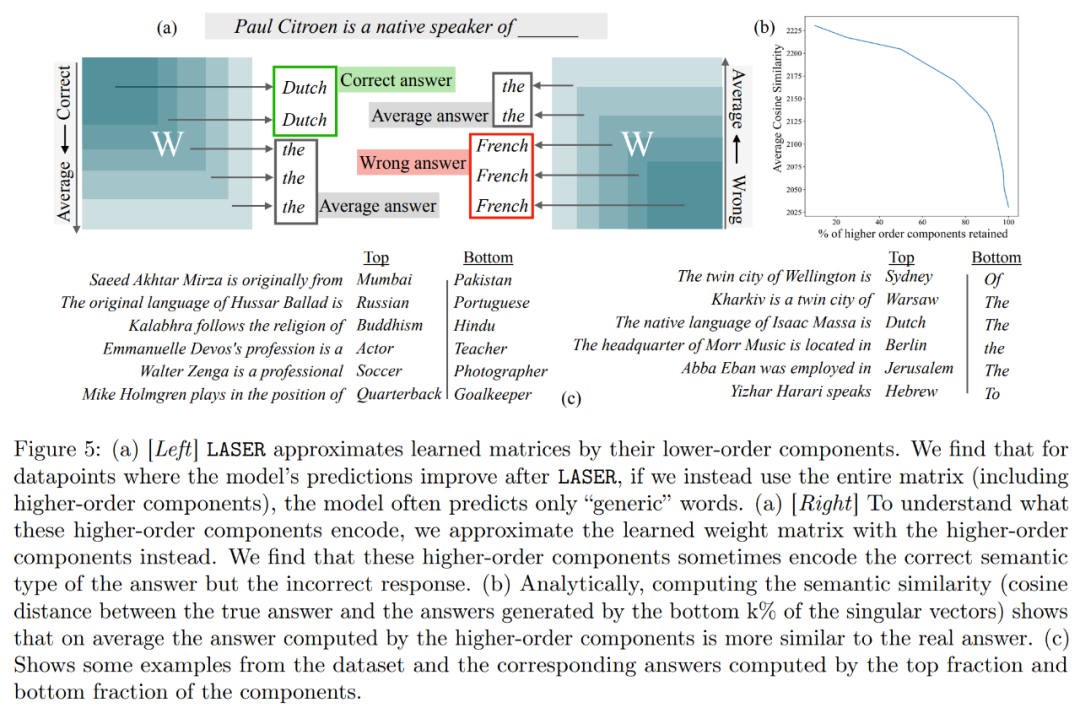
高阶组件存储什么呢?研究者使用高阶组件近似最终的权重矩阵(而不像 LASER 那样使用低阶组件来近似),如下图 5 (a) 所示。当使用不同数量的高阶组件来近似矩阵时,他们测量了真实答案相对于预测答案的平均余弦相似度,如下图 5 (b) 所示。
研究者最终对他们发现的三种不同的LLM在多项语言理解任务上的普适性进行了评估。对于每个任务,他们使用生成准确度、分类准确度和损失三个指标来评估模型的性能。根据表1的结果显示,即使矩阵的秩降低很大,也不会导致模型准确度下降,反而能提升模型的性能
以上是Transformer模型降維減少,移除90%以上特定層的元件時,LLM性能保持不變的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















