


GoogleGemini的實力究竟如何?卡內基美隆大學進行了一項專業客觀的第三方比較
為保證公平,所有模型使用相同的提示和生成參數,並提供可重複的程式碼和完全透明的結果。

不會像Google官方發表會那樣,用CoT@32比較5-shot了。
一句話結果:Gemini Pro版本接近但略遜於GPT-3.5 Turbo,GPT-4還是遙遙領先。
在深入分析中也發現Gemini一些奇怪特性,例如選擇題喜歡選D##…


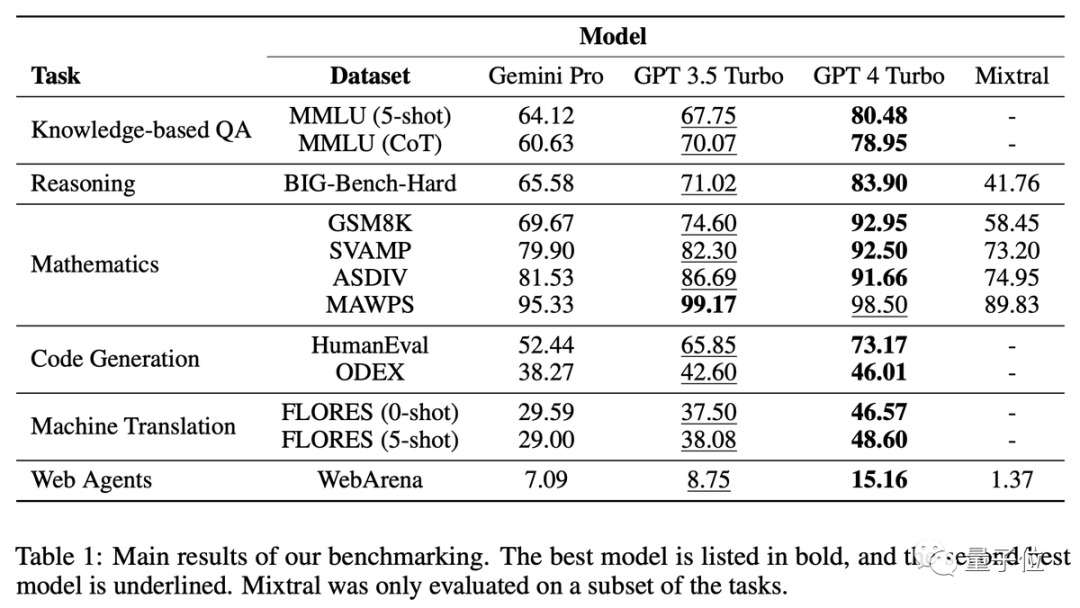
 在MMLU資料集中,所有的題目都是多選題。進一步分析結果後,發現了一個奇怪的現象:Gemini更喜歡選擇D選項
在MMLU資料集中,所有的題目都是多選題。進一步分析結果後,發現了一個奇怪的現象:Gemini更喜歡選擇D選項
GPT系列在4個選項上的分佈就要平衡很多,團隊提出這可能是
Gemini沒針對多選題做大量指令微調造成的。
 另外,Gemini的安全過濾非常嚴格。在涉及道德問題時,它只能回答85%的問題。而在涉及人類性行為相關問題時,它只能回答28%的問題
另外,Gemini的安全過濾非常嚴格。在涉及道德問題時,它只能回答85%的問題。而在涉及人類性行為相關問題時,它只能回答28%的問題
 Gemini Pro在安全研究和高中微觀經濟學方面的表現超過了GPT- 3.5,但差距並不大,團隊表示無法找出任何特別之處
Gemini Pro在安全研究和高中微觀經濟學方面的表現超過了GPT- 3.5,但差距並不大,團隊表示無法找出任何特別之處
 #推理:長問題不擅長
#推理:長問題不擅長
 GPT系列在處理更長、更複雜的問題時表現更出色,相較之下,Gemini Pro的表現較為不佳
GPT系列在處理更長、更複雜的問題時表現更出色,相較之下,Gemini Pro的表現較為不佳
特別是在長篇問題上,GPT-4 Turbo幾乎沒有效能下降,這表明它具備了理解複雜問題的強大能力
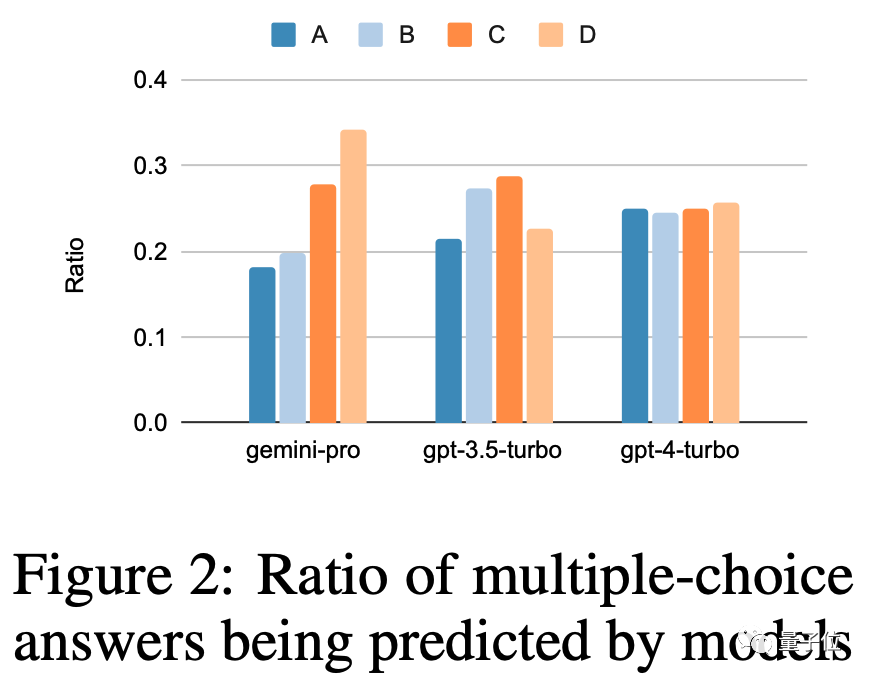
 根據問題類型進行分析,Gemini在「追蹤交換物品」這類問題上表現不佳,這類問題涉及人們進行物品交換,最終需要AI判斷每個人擁有哪些物品
根據問題類型進行分析,Gemini在「追蹤交換物品」這類問題上表現不佳,這類問題涉及人們進行物品交換,最終需要AI判斷每個人擁有哪些物品

Gemini擅長的任務包括理解世界各種體育運動知識、操作符號堆疊、按字母順序排序單字以及解析表格

問題本身太長,導致Gemini Pro和GPT-3.5的表現同時下降,只有GPT-4能夠維持一貫的水準

當思維鏈的長度達到最長時,Gemini超過了GPT-3.5

對於程式碼問題,Gemini在參考答案較長的問題上表現不佳

#GPT系列在大多數類型中更強大,但在matplotlib方面表現完全不佳

在翻譯任務中,Gemini拒絕回答了12種類型的問題,但只要回答了的翻譯品質都非常出色,整體表現超過了GPT-4

#雙子座拒絕翻譯的語言主要涉及拉丁語和阿拉伯語

WebArena為AI模擬了一個網路環境,包括電子商務、社交論壇、GitLab協作開發、內容管理系統和線上地圖等。 AI需要在這個環境中尋找資訊或跨站點完成任務
Gemini在整體表現不如GPT-3.5 Turbo,但在跨多個站點的任務中表現稍好。

最終,CMU副教授格雷厄姆·紐比格承認了這項研究的一些限制

Google大型模型推理團隊的負責人周登勇指出,將Gemini的溫度設定為0可以提高5-10個百分點,對於推理任務非常有幫助

在這項測試中,除了Gemini和GPT系列,還引入了最近備受關注的開源MoE模型Mixtral
不過,強化學習專家Noam Brown認為可以不考慮Mixtral的結果,因為它使用的是第三方API而不是官方實作


Mistral AI創辦人為團隊提供了官方版呼叫權限,他相信這將帶來更好的結果
#雖然Gemini Pro還不及GPT-3.5,但它的優勢在於每分鐘調用不超過60次就可以免費使用
因此,許多個人開發者已經改變了陣營

目前Gemini的最高版本Ultra版尚未發布,屆時CMU團隊也打算繼續進行這項研究
你認為雙子座Ultra能夠達到GPT-4的水平嗎?
本文詳細介紹了論文:https://arxiv.org/abs/2312.11444
參考連結:
#[1]https://twitter.com/gneubig/status/17371089777954251216。
以上是CMU進行詳細比較研究,發現GPT-3.5比Gemini Pro更優,確保公平透明可重複性的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















