

微软 CEO 纳德拉在 Ignite 大会上宣布,上个月,Phi-2 小尺寸模型将完全开源。这一举措将显著改进常识推理、语言理解和逻辑推理的性能

今天,微软公布了 Phi-2 模型的更多细节以及全新的提示技术 promptbase。这个仅 27 亿参数的模型在大多数常识推理、语言理解、数学和编码任务上超越了 Llama2 7B、Llama2 13B、Mistral 7B,与 Llama2 70B 的差距也在缩小(甚至更好)。
同时,小尺寸的 Phi-2 可以在笔记本电脑、手机等移动设备上运行。纳德拉表示,微软非常高兴将一流的小语言模型(SLM)和 SOTA 提示技术向研发人员分享。
微软在今年六月发表了一篇名为《只需教科书》的论文,使用了仅包含7B个标记的“教科书质量”数据来训练了一个包含1.3B个参数的模型,即phi-1。尽管数据集和模型规模比竞争对手小几个数量级,但是phi-1在HumanEval中的一次通过率达到了50.6%,在MBPP中的准确率达到了55.5%。phi-1证明了即使是高质量的“小数据”也能够使模型具备良好的性能
微软随后在九月份发表了《只需教科书II:Phi-1.5技术报告》,对高质量的“小数据”潜力进行了进一步的研究。文中提出了Phi-1.5,该参数适用于QA问答、代码等场景,可达到13亿的规模
如今 27 亿参数的 Phi-2,再次用「小身板」给出了卓越的推理和语言理解能力,展示了 130 亿参数以下基础语言模型中的 SOTA 性能。得益于在模型缩放和训练数据管理方面的创新, Phi-2 在复杂的基准测试中媲美甚至超越了 25 倍于自身尺寸的模型。
微软表示,Phi-2 将成为研究人员的理想模型,可以进行可解释性探索、安全性改进或各种任务的微调实验。微软已经在 Azure AI Studio 模型目录中提供了 Phi-2,以促进语言模型的研发。
语言模型规模增加到千亿参数,的确释放了很多新能力,并重新定义了自然语言处理的格局。但仍存在一个问题:是否可以通过训练策略选择(比如数据选择)在较小规模的模型上同样实现这些新能力?
微软提供的解决方案是使用Phi系列模型,通过训练小型语言模型来实现与大型模型类似的性能。Phi-2在两个方面打破了传统语言模型的缩放规则
首先,训练数据的质量在模型性能中起着至关重要的作用。微软通过专注于「教科书质量」的数据,将这一认知发挥到了极致。他们的训练数据包含了专门创建的综合数据集,教给模型常识性知识和推理,例如科学、日常活动和心理等。此外,他们还通过精心挑选的网络数据来进一步扩充自己的训练语料库,这些网络数据经过教育价值和内容质量的筛选
其次,微软使用创新技术进行扩展,从 13 亿参数的 Phi-1.5 开始,将知识逐渐嵌入到了 27 亿参数的 Phi-2 中。这种规模化知识迁移加速了训练收敛,并显著提升了 Phi-2 的基准测试分数。
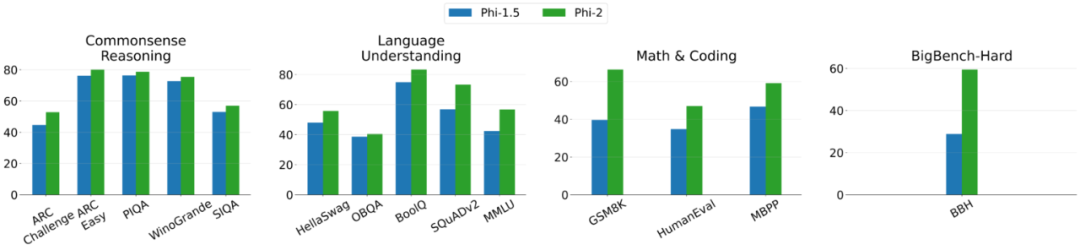
以下是Phi-2和Phi-1.5之间的比较图,除了BBH(3-shot CoT)和MMLU(5-shot)之外,所有其他任务都是使用0-shot进行评估
Phi-2 是一个基于 Transformer 的模型,其目标是预测下一个词。它在合成数据集和网络数据集上进行了训练,使用了 96 块 A100 GPU,并花费了 14 天的时间
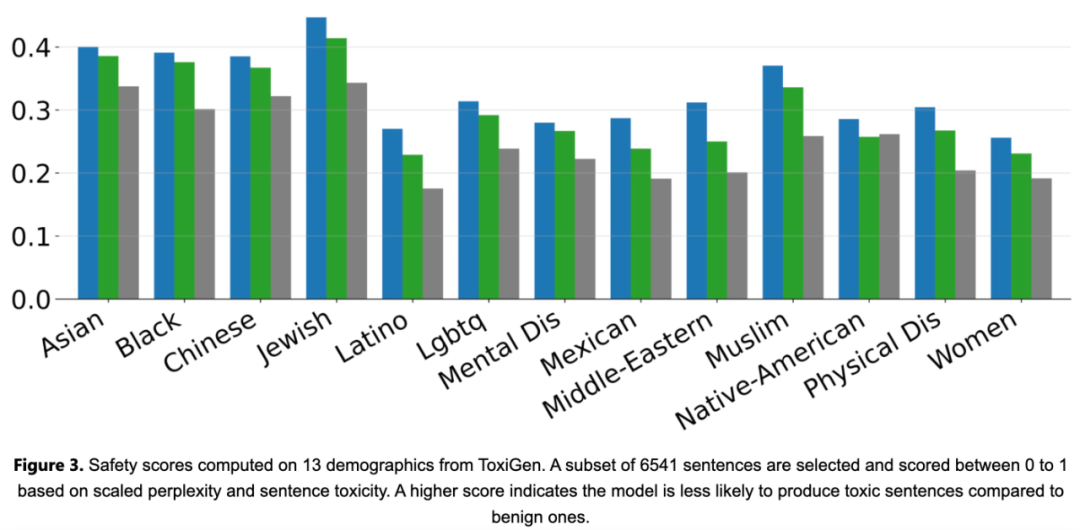
Phi-2 是一个基础模型,没有通过人类反馈强化学习 (RLHF) 进行对齐,也没有进行指令微调。尽管如此,与经过调整的现有开源模型相比,Phi-2 在毒性和偏见方面仍然表现得更好,如下图 3 所示。
首先,研究在學術基準上對Phi-2 與常見語言模型進行了實驗比較,涵蓋多個類別,包括:
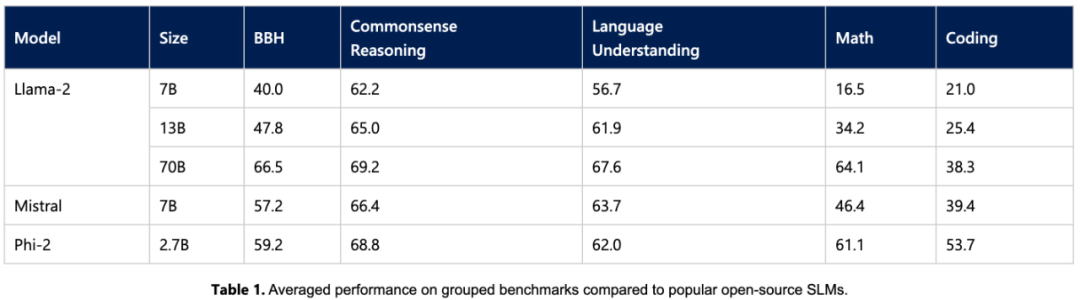
#Phi-2模型僅有27億個參數,卻在各種聚合基準上表現超越了7B和13B的Mistral模型和Llama2模型。值得一提的是,與龐大的25倍Llama2-70B模型相比,Phi-2在多步驟推理任務(即編碼和數學)方面表現更出色
此外,儘管尺寸較小,但Phi-2 的性能可以媲美最近由Google發布的Gemini Nano 2
由於許多公共基準可能會洩漏到訓練資料中,研究團隊認為測試語言模型效能的最佳方法是在具體用例上對其進行測試。因此,該研究使用多個微軟內部專有資料集和任務對Phi-2 進行了評估,並再次將其與Mistral 和Llama-2 進行比較,平均而言,Phi-2 優於Mistral-7B,Mistral -7B 優於Llama2 模型(7B、13B、70B)。

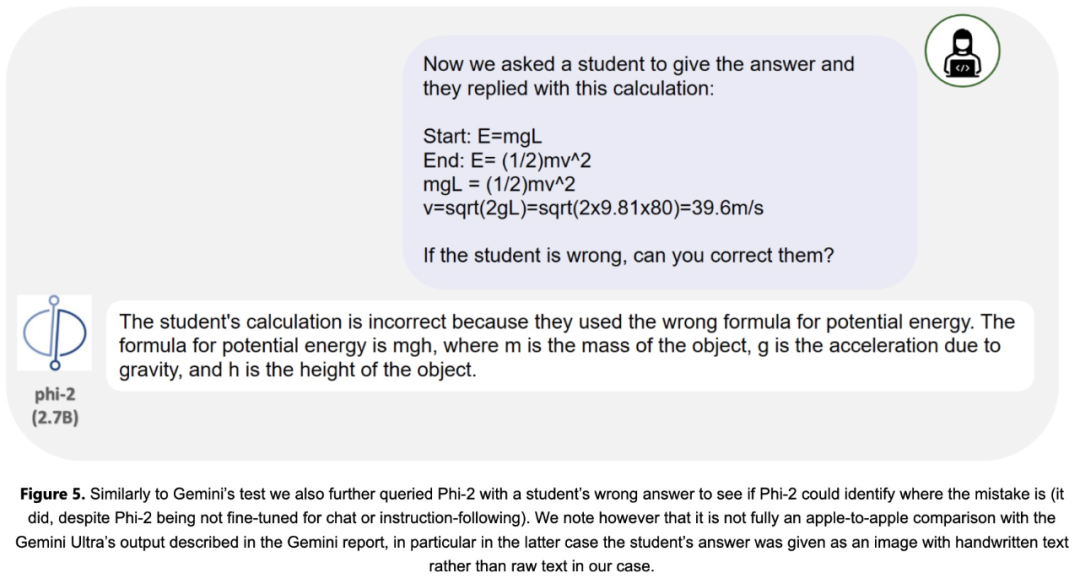
#研究團隊也對常見的研究社群提示進行了廣泛測試。 Phi-2的表現與預期相符。例如,對於用於評估模型解決物理問題能力的提示(最近用於評估Gemini Ultra模型),Phi-2給出了以下結果:

以上是手機運行微軟小模型勝過27億參數的大模型的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















