

在手機等行動端側運行 Stable Diffusion 等文生圖生成式 AI 大模型已成為業界追逐的熱點之一,其中生成速度是主要的限制因素。
近日,來自Google的一篇論文「MobileDiffusion: Subsecond Text-to-Image Generation on Mobile Devices」,提出了手機端最快文生圖,在iPhone 15 Pro 上只要0.2 秒。論文出自 UFOGen 同一團隊,在打造超小擴散模型的同時, 採用當前大火的 Diffusion GAN 技術路線做採樣加速。

請點擊以下連結查看論文:https://arxiv.org/abs/2311.16567
#下面是MobileDiffusion 一步產生的結果。

那麼,MobileDiffusion 是如何優化得到的呢?
首先,讓我們從問題出發,探討為何優化是必要的
目前最熱門的文字到圖像生成技術都是基於擴散模型實現的。由於其預先訓練的模型具有極強的基本圖像生成能力和在下游微調任務上的穩健性質,因此我們看到了擴散模型在圖像編輯、可控生成、個性化生成以及視頻生成等領域的出色表現
然而,作為基礎模型,其不足之處也很明顯,主要包括兩個方面:一是擴散模型的大量參數導致計算速度慢,尤其是在資源有限的情況下;二是擴散模型需要多步驟才能進行取樣,進一步導致推理速度緩慢。以備受矚目的 Stable Diffusion 1.5(SD)為例,其基礎模型包含近10億個參數,我們在iPhone 15 Pro上對模型進行量化後進行推理,50步採樣需要接近80秒。如此昂貴的資源需求和遲緩的用戶體驗極大地限制了其在行動端的應用場景
為了解決以上問題,MobileDiffusion 點對點地進行最佳化。 (1) 針對模型體積龐大的問題,我們主要對其核心組件UNet 進行了大量試驗及優化,包括了將計算昂貴的捲積精簡和注意力運算放在了較低的層上,以及針對Mobile Devices的操作最佳化,諸如激活函數等。 (2)針對擴散模型需要多步驟採樣的問題,MobileDiffusion 探索並實踐了像 Progressive Distillation 和當前最先進的 UFOGen 的一步推理技術。
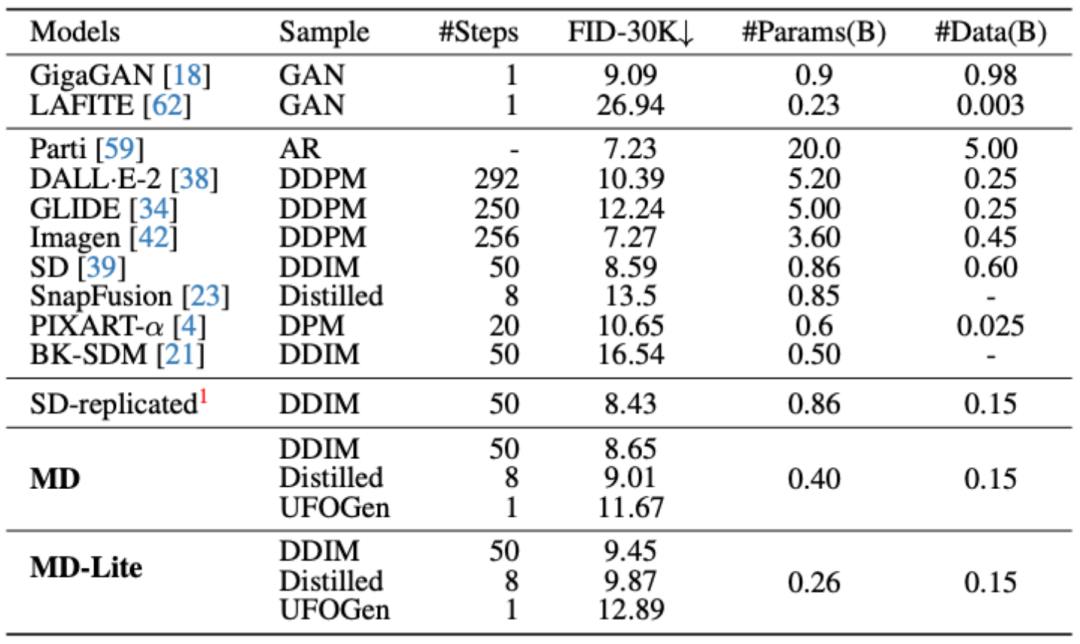
MobileDiffusion 基於當下開源社群裡最火的SD 1.5 UNet 進行最佳化#。在每次的最佳化操作後, 會同時衡量相對於原始 UNet 模型的效能的損失,測量指標包括 FID 和 CLIP 兩個常用 metric。
整體規劃
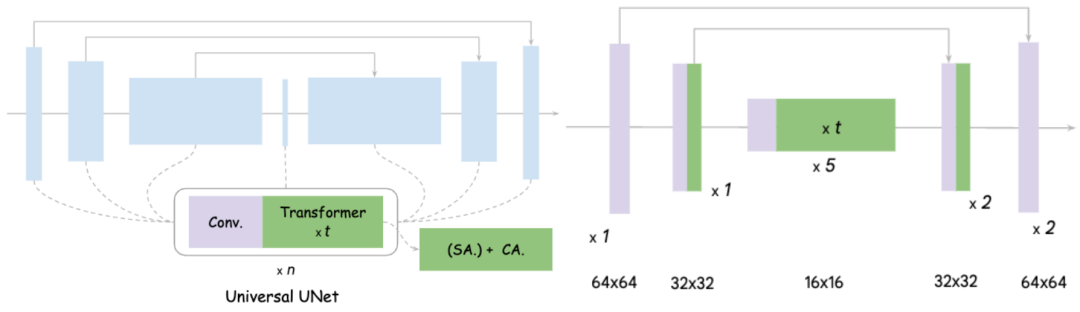
#在圖上的左側是原始UNet 的設計示意,可以看出它基本上包括了卷積和Transformer,而Transformer又包括了自註意力機制和交叉注意力機制
MobileDiffusion對UNet 優化的核心思路分為兩點:1)精簡Convolution, 眾所周知,在高分辨率的特徵空間上進行了Convolution 是十分耗時的, 而且參數量很大,這裡指的是Full Convolution;2)提高Attention 效率。和 Convolution 一樣,高 Attention 需要對整個特徵空間的長度進行運算,Self-Attention 複雜度和特徵空間展平後長度成平方關係,Cross-Attention 也要和空間長度成正比。
經過實驗證明,將整個UNet的16個Transformer移動到特徵解析度最低的內層,並且每一層都剪掉一個卷積,對效能沒有明顯影響。所達到的效果是:MobileDiffusion將原本的22個卷積和16個Transformer精簡到了只有11個卷積和大約12個Transformer,並且這些注意力都是在低解析度特徵圖上進行的。這樣做的效率大大提高,帶來了40%的效率提升和40%的參數剪切。最終的模型如右圖所示。以下是與其他模型的比較:

#需要重新寫的內容是:微觀設計
這裡將只介紹幾種新穎的設計,有興趣的讀者可以閱讀正文, 會有更詳細的介紹。
解耦自註意力和交叉注意力
##解耦自註意力和交叉注意力
傳統UNet 裡Transformer 同時包含Self-Attention 和Cross-Attention,MobileDiffusion 將Self -Attention 全部放在了最低解析度特徵圖,但是保留一個Cross-Attention 在中間層,發現這種設計既提高了運算效率又保證了模型出圖品質
Finetune softmax into relu
眾所周知,在大部分未最佳化的情況下,softmax函數很難進行平行處理,效率較低。 MobileDiffusion提出了一種新的方法,即將softmax函數直接調整(finetune)為relu函數,因為relu函數對於每個資料點的啟動更有效率。令人驚訝的是,僅需大約一萬步的微調,模型的度量指標反而提高了,產生的影像品質也得到了保證。因此,相較於softmax函數,relu函數的優點顯而易見
Separable Convolution (可分離卷積)
MobileDiffuison 精簡參數的關鍵也採用了Seprable Convolution。這種技術已經被 MobileNet 等工作證實是極為有效的,特別是行動端,但是一般在生成模型上很少採用。 MobileDiffusion 實驗發現 Separable Convolution 對減少參數是很有效的,尤其是將其放在 UNet 最內層,模型品質經分析證明是沒有損失的。
取樣最佳化
目前最受歡迎的取樣最佳化方法包括漸進式蒸餾(Progressive Distillation)和UFOGen,它們分別可以實現8步驟和1步。為了證明即使在模型經過極致簡化後,這些採樣方法仍然有效,MobileDiffusion對這兩種方法進行了實驗驗證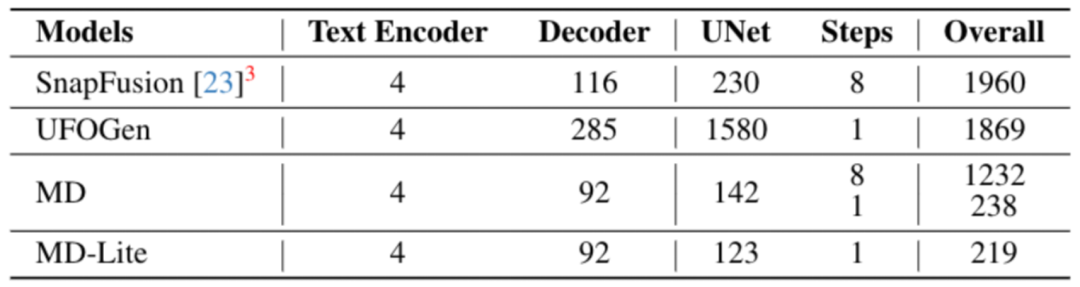
優化後的採樣與基準模型進行了比較,可以看出取樣優化後的8 步驟與1 步驟模型的指標都有顯著的提升
實驗與應用程式
 行動端基準測試
行動端基準測試
#在iPhone 15 Pro 上,MobileDiffusion 可以以目前最快的速度進行出圖,只需0.2 秒!
###################下游任務測試#####################MobileDiffusion 探索了包含ControlNet/Plugin 和LoRA Finetune 的下游任務。從下圖可以看出,經過模型和取樣優化後,MobileDiffusion 依然保持了優秀的模型微調能力。 #####################總結#############MobileDiffusion對多種模型和取樣優化方法進行了探索,最終實現了在行動端亞秒的影像產生能力,同時確保了下游微調應用的穩定性。我們相信這將對未來高效的擴散模型設計產生影響,並拓展行動端應用的實際應用案例######以上是手機上影像0.2秒即可呈現,Google建置最快的行動擴散模式MobileDiffusion的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















