

迴歸是統計學中最有力的工具之一,機器學習監督學習演算法分為分類演算法和迴歸演算法兩種。迴歸演算法用於連續型分佈預測,可以預測連續型資料而不僅僅是離散的類別標籤。
迴歸分析在機器學習領域中廣泛應用,例如預測商品銷售、交通流量、房價以及天氣狀況等
迴歸演算法是一種常用的機器學習演算法,用於建立自變數X和因變數Y之間的關係。從機器學習的角度來看,它用於建立一個演算法模型(函數),以實現屬性X和標籤Y之間的映射關係。在學習過程中,演算法試圖找到最佳的參數關係,以使擬合程度最好
在迴歸演算法中,演算法(函數)的最終結果是一個連續的資料值。輸入值(屬性值)是一個d維度的屬性/數值向量
一些常用的迴歸演算法包括線性迴歸、多項式迴歸、決策樹迴歸、Ridge迴歸、Lasso迴歸、ElasticNet迴歸等等
本文將介紹一些常見的迴歸演算法,以及它們各自的特點
線性迴歸通常是人們學習機器學習和資料科學的第一個演算法。線性迴歸是一種線性模型,它假設輸入變數 (X) 和單一輸出變數 (y) 之間存在線性關係。一般來說,有兩種情況:
單變數線性迴歸是一種建模方法,用於分析單一輸入變數(即單一特徵變數)與單一輸出變數之間的關係
多變量線性迴歸(也稱為多元線性迴歸):它對多個輸入變數(多個特徵變數)和單一輸出變數之間的關係進行建模。
當我們想要為非線性可分資料建立模型時,多項式迴歸是最受歡迎的選擇之一。它類似於線性迴歸,但使用變數 X 和 y 之間的關係來找到繪製適合資料點的曲線的最佳方法。
支援向量機在分類問題中是眾所周知的。 SVM 在迴歸中的使用稱為支持向量迴歸(SVR)。 Scikit-learn在 SVR()中內建了這種方法。
決策樹是一種用於分類和迴歸的非參數監督學習方法。目標是創建一個模型,透過學習從資料特徵推斷出的簡單決策規則來預測目標變數的值。一棵樹可以看成是分段常數近似。
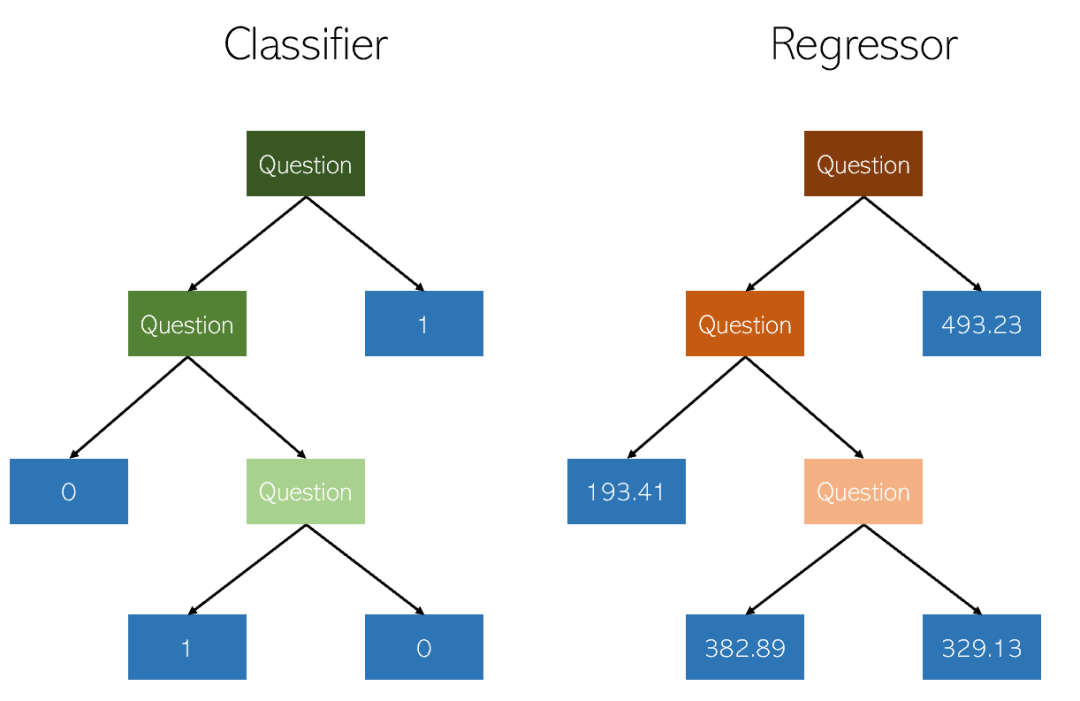
隨機森林迴歸與決策樹迴歸基本上非常相似。它是一種元估計器,可以在資料集的各個子樣本上擬合多個決策樹,並透過平均來提高預測準確性和控制過擬合
##隨機森林迴歸器在迴歸問題中的表現可能會優於決策樹,也可能不如決策樹(儘管在分類問題中通常更好),這是由於樹構造演算法本身存在微妙的過擬合和欠擬合的權衡
LASSO迴歸是一種變體的收縮線性迴歸。收縮是將數據值收縮到中心點作為平均值的過程。這種迴歸類型非常適用於具有嚴重多重共線性(特徵之間高度相關)的模型
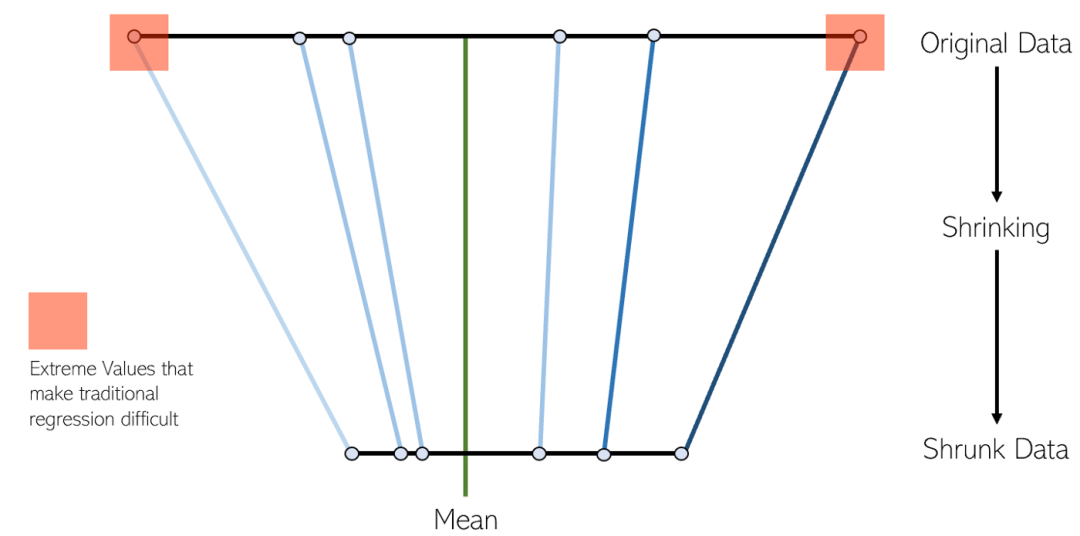
嶺迴歸(Ridge regression)和LASSO迴歸非常相似,因為這兩種技巧都採用了收縮方法。 Ridge和LASSO回歸都非常適合具有嚴重多重共線性問題(即特徵之間高度相關)的模型。它們之間的主要差異在於Ridge使用L2正規化,這意味著沒有一個係數會像LASSO迴歸中那樣變為零(而是接近零)
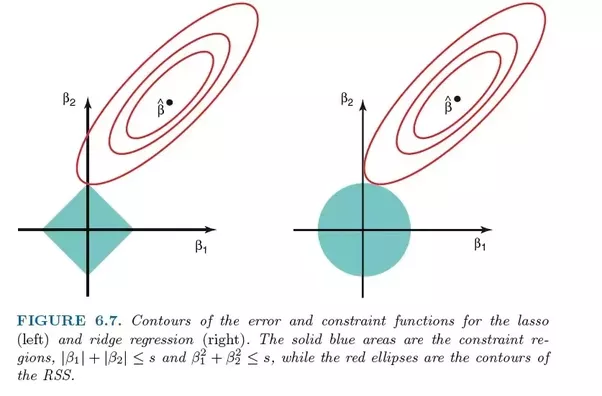
ElasticNet 是另一個使用 L1 和 L2 正規化訓練的線性迴歸模型。它是 Lasso 和 Ridge 回歸技術的混合體,因此它也非常適合顯示重度多重共線性(特徵相互之間高度相關)的模型。
在權衡Lasso和Ridge之間時,一個實際的優勢是Elastic-Net可以在旋轉下繼承Ridge的一些穩定性
九、 XGBoost 迴歸XGBoost 是梯度提升演算法的一種高效且有效的實作。梯度提升是一類可用於分類或迴歸問題的整合機器學習演算法
XGBoost是一個開源函式庫,最初由陳天奇在他於2016年的論文《XGBoost: A Scalable Tree Boosting System》中開發。此演算法的設計旨在具有高效和效率的運算能力
In Local Weights Linear Regression (Local Weights Linear Regression), we are also performing linear regression. However, unlike ordinary linear regression, locally weighted linear regression is a local linear regression method. By introducing weights (kernel functions), when making predictions, only some samples that are close to the test points are used to calculate the regression coefficients. Ordinary linear regression is global linear regression, which uses all samples to calculate the regression coefficient
11. Bayesian Ridge Regression
The linear regression model solved using the Bayesian inference method is called Bayesian linear regressionBayesian linear regression is a method that treats the parameters of a linear model as random variables and calculates the posterior through the prior. Bayesian linear regression can be solved by numerical methods, and under certain conditions, posterior or related statistics in analytical form can also be obtained
Bayesian linear regression has a Bayesian statistical model The basic properties of it can solve the probability density function of weight coefficients, conduct online learning and model hypothesis testing based on Bayes factor (Bayes factor)
Advantages and Disadvantages&Applicable Scenarios
The disadvantage is the learning process overhead Too big. When the number of features is less than 10, you can try Bayesian regression.
以上是常用的迴歸演算法及其特點在機器學習中的應用的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















