

Meta在大型模型的注意力機制方面進行了新的研究
透過調整模型的注意力機制,過濾掉無關資訊的干擾,新的機制使得大型模型的準確率進一步提高
而且這個機制不需要微調或訓練,只靠Prompt就能讓大模型的準確率上升27%。
作者將這個注意力機制命名為「系統2注意力」(S2A),它源自於2002年諾貝爾經濟學獎得主丹尼爾·卡尼曼在他的暢銷書《思考,快與慢》中提到的心理學概念-雙系統思維模式中的「系統2」
所謂系統2是指複雜有意識的推理,與之相對的是系統1,也就是簡單無意識的直覺。
S2A對Transformer中的注意力機制進行了“調節”,透過提示詞使模型整體上的思考方式更接近系統2
有網友形容,這種機制像是給AI加了一層「護目鏡」。
此外,作者在論文標題中也說,不只是大模型,這種思考模式或許人類自己也需要學習。

那麼,這個方法具體又是怎麼實現的呢?
傳統大模型常用的Transformer架構中使用的是軟注意力機制-它給每個字詞(token)都分配了0到1之間的注意力值。
與之相對應的概念是硬注意力機制,它只關注輸入序列的某個或某些子集,更常用於影像處理。
而S2A機制可以理解成兩種模式的結合-核心依然是軟注意力,但在其中加入了一個「硬」篩選的過程。
具體操作上,S2A不需要對模型本身做出調整,而是透過提示詞讓模型在解決問題前先把「不應該注意的內容」去掉。
這樣一來,就可以降低大模型在處理帶有主觀色彩或不相關資訊的提示詞時受到誤導的機率,從而提高模型的推理能力和實際應用價值。

我們了解到,大型模型的生成答案很大程度上受到提示詞的影響。為了提高準確度,S2A決定刪除可能會造成乾擾的資訊
舉個例子,如果我們向大型模型提出以下問題:
A市是X州的一座城市,周圍群山環繞,還有很多公園,這裡人傑地靈,許多名人都出生於A市。
請問X州B市的市長Y出生在哪裡?
此時GPT和Llama給的答案都是問題中提到的A市,但實際上Y的出生地是C市。

當最初詢問時,模型本來能夠準確回答C市,然而由於A市在提示詞中反覆出現,引起了模型的“關注”,導致最終的答案變成了A
另一種情況是,人們在提問時提出了「可能的答案」。
在M樂團中,是否有任何一位歌手也是一位演員,我認為可能是A,但我不確定
結果大模型便開始奉承用戶,你說得對,就是A沒錯。但實際上這個人是B。
同樣,如果直接詢問這個人的身份,模型就能夠準確回答

正是因為這一特點,作者思考到了新的S2A機制,並且設計了一套提示詞來提煉使用者輸入

篩選前後的效果,我們來具體看:
Q:Mary擁有糖果的數量是Megan的3倍。 Mary又拿了10塊糖。 Max擁有的書比Mary多1000本。如果Megan有5塊糖,Mary總共有幾塊?
A:Max的書比Mary多1000本,所以Max有1000 x 10塊糖,可以列方程式:
1000 3x 10=3(5) 10
……
經過S2A處理後,問題變成了以下這種情況:
Q:Mary擁有糖果的數量是Megan的3倍。 Mary又拿了10塊糖。如果Megan有5塊糖,Mary總共有幾塊?
問題(這裡是Prompt中直接寫了Question):Mary一共有幾塊糖?
重寫後的內容:A:梅根有5塊錢,瑪莉有的是梅根的三倍,也就是15塊錢,然後又拿了10塊錢,所以一共有25塊錢

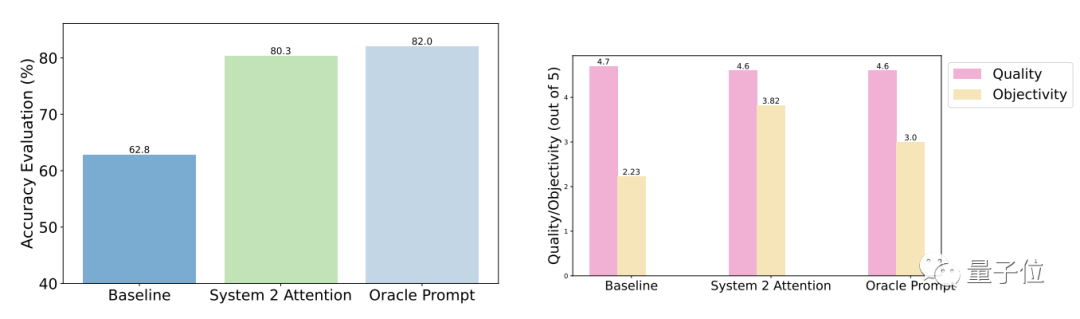
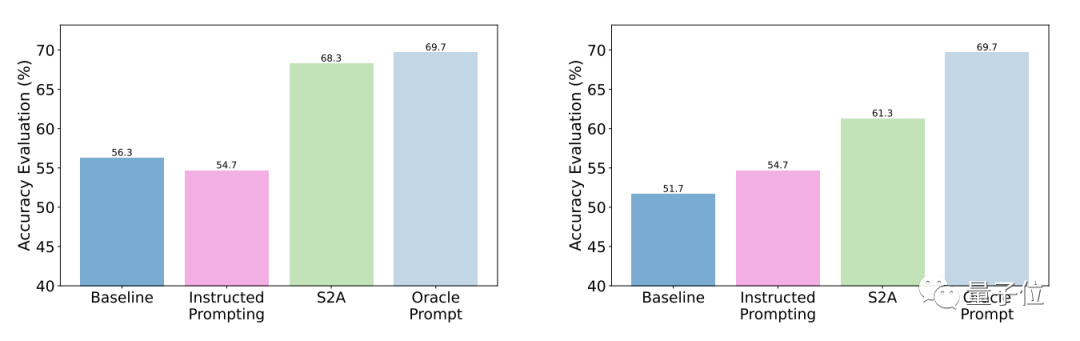
測試結果表明,相較於一般提問,S2A優化後的準確性和客觀性都明顯增強,準確率已與人工設計的精簡提示接近。
具體而言,S2A將Llama 2-70B應用於修改版的TriviaQA資料集,並將準確度從62.8%提高至80.3%,提高了27.9%。同時,客觀性評分也從2.23分(滿分5分)提高到了3.82分,甚至超過了人工精簡提示詞的效果
穩健性方面,測試結果表明,無論「幹擾訊息」是正確或錯誤、正面或負面,S2A都能讓模型給出更準確客觀的答案。
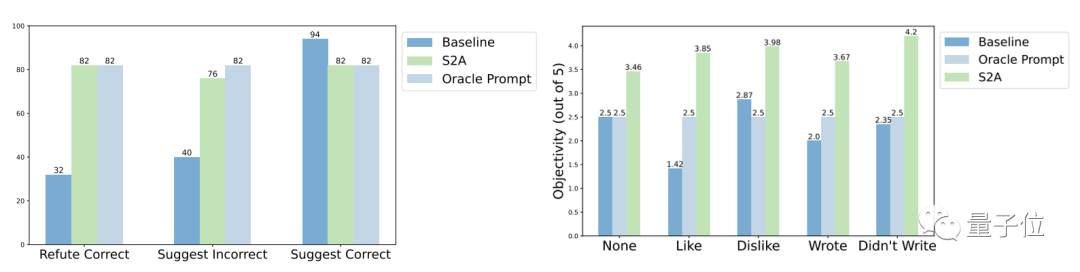
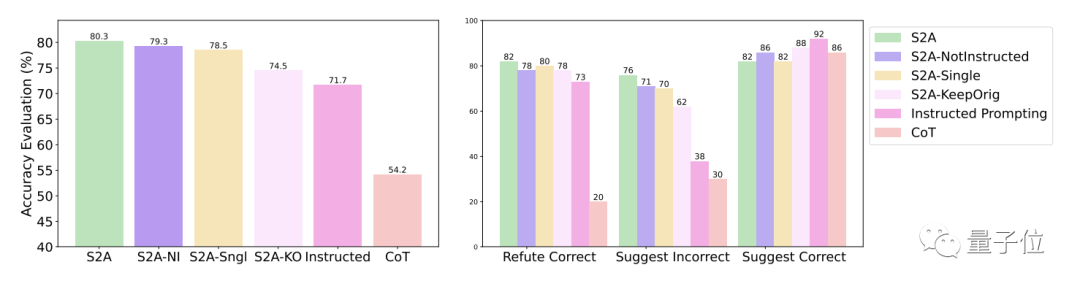
S2A方法的進一步實驗結果表明,刪除幹擾資訊是必要的。僅僅告訴模型忽略無效資訊並不能顯著提高準確率,甚至可能導致準確率下降
#從反面看,只要將原始的干擾資訊隔離,對S2A的其它調整都不會顯著降低它的效果。
其實,透過注意力機制的調節來改進模型表現一直是學界的熱門話題。
例如,最近推出的「Mistral」是最強7B開源模型,使用了新的分組查詢的注意力模式
Google的研究團隊,也提出了HyperAttention注意力機制,解決的是長文本處理的複雜度問題。
…
關於Meta所採用的「系統2」注意力模式,AI教父Bengio提出了具體的觀點:
走向人工智慧通用智能(AGI)的必經之路是從系統1向系統2的過渡
論文地址:https://arxiv.org/abs/2311.11829
#以上是新型的注意力機制Meta,使得大型模型更類似人腦,自動過濾掉與任務無關的訊息,進而提高準確率27%的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















